
上个月我把 Claude 从 Pro 升到 Max,$200 一个月,心想这下总该用够用了吧。
第五天:本周额度已耗尽。
翻使用日志我才看清楚钱花在哪。一次调研 47 篇论文的下午会话,单次就吃掉一周 10% 的额度。这种会话一周跑两三次,额度自然撑不住。
·问题在我一直让 Claude 干它不擅长的事——当全文检索引擎。
一坨 50k 字符的日志塞进对话,问一个问题,日志全文就要被算一次 input token;再问个,就算命中了 prompt cache(单价只剩 1/10),主会话也会随轮次缓慢累加。更糟的是 cache 有 1h TTL,间隔久了就得重写一次全价。这就好比每次问律师问题,都让他把你 50 页的合同先朗读一遍再开口。
Claude Code 擅长推理、编排、写代码。读原始语料这件事该让别的工具干,Claude 只看结论。顺着这个思路找下去,我想到了 NotebookLM。
跟着这篇配置一遍,你 $20 的账号能干出 $200 的活。
导读
长文,按兴趣挑着看:
-
一:NotebookLM 是什么 + 能干什么
-
二:为什么要再套一层 Claude
-
三:装 skill,10 分钟动手
-
四:实测 token 账 + 原理拆解
-
五:学者 / 学生工作流
-
六:打新股 / 读招股书 工作流
-
七:个人知识库工作流
-
总结
想先看工作流,直接跳到第五部分——找到你那一类看就行。
一句话论点
真正省 Claude token 的办法不是开 cache,是让重数据一开始就不进 Claude。
具体做法:让 NotebookLM 存储语料和检索,Claude 只做推理和编排。两者分工清晰,用一个比喻概括——
NotebookLM 是老师:你亲自采集进去的论文、财报、笔记形成它的知识库。你问它,它答经验,答案带引用,边界在源内,不乱外推。Claude 是助手:负责写代码、跑脚本、整理结果、编排工具。不懂就去问老师,拿到答案继续干活。你是课题负责人:只在关键决策点介入。
关键原理,为什么这样分工省钱
一、RAG vs 塞 context 是两种不同的成本模型。 把 50k 字符日志塞进 Claude 对话,这坨数据就被算进 input token。每问一次就要被"看"一次,成本随语料大小线性涨。走 RAG 则是 NotebookLM 内部用向量检索命中相关片段,Claude 只看到几百字的蒸馏答案,成本近乎常数。
二、prompt cache 有 1h TTL,研究场景命中率很低。 很多人以为开了 cache 就万事大吉。实际 Anthropic 的 prompt cache 默认只存 1 小时,超时就自动失效;你思考几分钟、切去做别的、或者开新 session,下一次调用就得按全价把语料重写一次 cache_creation。研究性会话恰好是"问一下、想一会、再问一下"的节奏,命中率常常惨不忍睹。这是账单暴涨的真正原因。
三、基于事实输出会更有效 NotebookLM 的答案被约束在你上传的源里,每句话带 [1][2] 引用,点回原文。不会胡编。Claude 拿这种答案做决策,不用反复让它"再确认一下",省下的是更难量化的那部分时间成本。
谁不用看下面了
-
语料 < 5k tokens、只查一两次——直接问 Claude,别折腾
-
需求是纯 Q&A、不嵌工作流——打开 notebooklm 网页用就够了
-
在乎响应速度超过账单——慢 3 倍受不了
-
要理解代码结构 / 跳定义——NotebookLM 更加适合文本 RAG
谁继续往下读
-
想要具体的安装步骤和避坑
-
想看几个场景怎么落地到指令层
-
在用 Claude Code 想把 NotebookLM 变成一个 skill
第一部分:先认识 NotebookLM
第一次打开 NotebookLM 是因为一位朋友安利。她写论文的 reading list 有 60 多篇,以前在 PDF 阅读器里挨个 Ctrl-F,现在把全部论文丢进一个 notebook,问"谁支持 X 观点、谁反对、分歧集中在哪几个变量"——答案带 [1][2][3] 引用直接甩过来,点一下就跳回原文对应段落。
她说一周能省十几个小时。
我抱着怀疑态度试了一周,最后上瘾了。下面是这一周攒下的经验,下面是 NotebookLM 使用的优点:
-
支持免费档 50 个源 / Pro 档 300 个
-
处理能力不要钱,上传、索引、生成、对话——全走 Google 的算力
-
除了问答,它能把一整个 notebook 直接自动生成音频播客(通勤听最舒服)、思维导图、PPT、闪卡等等。
-
播客尤其惊艳——你自己的资料,被两个陌生 AI 用你没想过的角度讲一遍,常常能听出新东西。
格式从来不是问题:PDF、网页 URL、YouTube 字幕、Google Docs、纯文本粘贴、图片 OCR、音频转写——都能当源。
光上面这些,NotebookLM 已经是一个非常强的独立工具。如果你的需求就是"坐下来问几个问题",这篇文章到这里就够了,下面的都不用看。
但我用着用着发现它卡在2个地方:
一、心流被切 tab 切烂 调研一个课题:问一个问题 → 得到答案 → 点引用跳原文 → 读完一段 → 回 notebook 复制答案 → 切到 Claude Code 消费→ 做完实验 → 发现少一篇资料 → 切到 Google 搜 → 切到下载 → 切回 notebook 加源 → 继续问……一下午切 200 次 tab。
二、跟本地工具是两个世界 我排查线上事故时把日志灌进 notebook 后能查。但我还要同时在终端 grep 本地配置、看 k8s events、起 pod 复现——网页不能帮我跑任何本地命令,每次都是"在网页看完 → 手动敲一遍 → 再切回网页"。
NotebookLM 网页把自己定位成终点——你问它,它答你,结束。但我想让它成为流水线上的一环——被调度、被批处理、输出能流到下一步。
这是 Claude 登场的地方。
第二部分:再把 Claude 套上去
把 NotebookLM 变成 Claude 的一个工具。一件事就够了——Claude 需要领域知识时,自己去问老师。
流程的形状
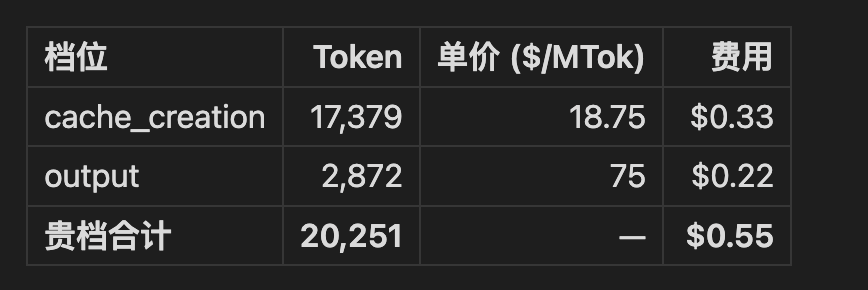
老师(NotebookLM)是只读的咨询台:你一次性把 47 篇论文灌进去就不用再管了,它就在那儿待着等你问。不用回灌、不用喂新笔记——论文本身的观点已经足够撑起所有查询。
下面这个 prompt 把流程图的六步、工作纪律、具体 notebook ID 全编码进去了,贴进 Claude Code 就能跑(注意替换id):

几条线索
-
47 篇论文原文一次都没进 Claude 对话——主会话 token 只花在推理和代码
-
老师只被咨询、不参与执行——它的长处是带引用的领域检索
-
你只在 ① 介入——中间要不要再问一次老师,Claude 自己判断
-
老师知识库静止不变——47 篇论文就是 47 篇,够用了
这是"串起来"比"单独用"强的根本原因:省掉的 tab 切换、省下的 token,都是附赠福利。下面讲福利有多大。
第三部分:安装 NotebookLM Client & skill,让 Claude 认识这个老师
Google 官方没有提供 NotebookLM client,不过 @icebear0828 已经写了第三方 client 可以连接 NotebookLM,安装后,Agent可以通过命令行或者自然语言访问 NotebookLM。
https://github.com/icebear0828/notebooklm-client 。
基础安装:
# 角色
你是我的研究助手。我的课题老师是一个固定的 NotebookLM notebook
(id: 6634ad4d-0594-4700-bddf-4a400ad46fa2),里面装着 47 篇相关论文。
你通过已安装的 notebooklm skill(`/notecraft chat` 等命令)跟老师对话。
# 铁律
1. 任何涉及论文观点、公式、方法、已知坑的问题,**先 /notecraft chat 问老师**,
不要凭记忆回答,也不要让我把论文原文贴进对话。
2. 老师是**只读咨询台**:不要把笔记、代码、实验结果回灌进 notebook。
知识库就 47 篇论文,静止不变。
3. 老师的答案带 [1][2] 引用。把引用原样保留在你给我的输出里。
4. 中间要不要再问一次老师,你自己判断——不用每一步都确认。
5. 老师答不上或引用弱的问题,明确说"老师无解",不要外推硬编。
# 工作流程
① 我给你一个课题 / 子问题。
② 识别里面哪些点需要领域知识(论文观点、前人方法、公式推导、已知失败模式
)。
③ 对这些点逐条 /notecraft chat,拿到带引用的答案。
④ 用答案驱动执行:写代码、跑脚本、grep 本地文件、整理结果。
⑤ 执行中冒出新疑问就回到 ③ 再问老师,直到没有新疑问。
⑥ 最终输出给我:
- 结论(带老师答案的 [引用])
- 你的代码 / 实验结果
- 老师没覆盖的 open question 单独列一节
# 输出格式
每次交付用这个骨架:
## 老师说
(/notecraft chat 拿到的要点,每条保留 [引用])
## 我做了什么
(你写的代码 / 跑的命令 / 观察到的结果)
## 结论
(对我原始课题的回答)
## 老师没覆盖的
(老师答不上或引用弱的点,留给我人工跟进)
# 开始
我的第一个课题是:<在这里写你的问题>
装完之后在对话里说"查一下那个 notebook 里 X 的部分",Claude 会自动调——不用每次解释语法。
第四部分:实测——到底省多少钱(Opus 4.7)
下面这组数不是模拟的,是真实一轮研究会话,从 Claude Code 的 session log 里扒出来的。
NotebookLM 侧那部分 token 上传、检索、生成——Google 全部免费,不进你的账单。下面所有数字只算 Opus 这边。
测试设置
-
语料:47 篇图像 + LiDAR SLAM 相关论文,一次性灌进同一个 NotebookLM notebook
-
模型:Claude Opus 4.7
-
轮数:5 轮深度问答(从"最适合做 SLAM 重建的方法"一路问到"3DGS vs NeRF 接 SLAM 后端的坑")
-
方式:Claude Code 里正常对话,每轮助手自己调 /notecraft chat 去问老师
实测结果(本文做法)
真正决定账单的是 token input + cache_creation(往缓存写新内容)和 output(生成)。便宜档(cache_read + input)单价不到它们的 1/10,这里忽略,只算贵档:
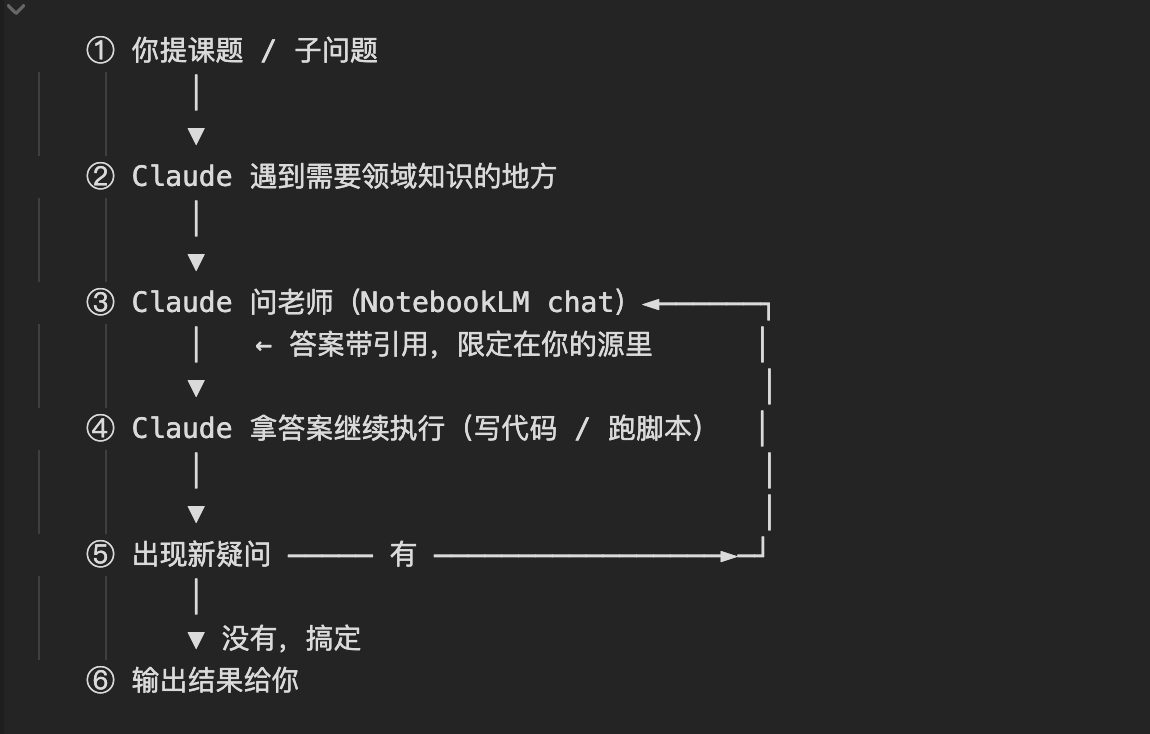
5 轮贵档合计 $0.55,平均每轮约 $0.11。
关键数字:cache_creation 只有 17,379
cache_creation 是每次"往缓存写新内容"的 token,贵档里最容易爆的一档。这次 5 轮里写进缓存的只有每轮老师答案(~3-6k token)+ 少量系统增量——合计 1.7 万。
47 篇论文的原文一个字都没进 Claude 的 cache_creation——这就是省钱的全部秘密。
对比:如果把 47 篇论文直接塞 prompt
47 篇论文实测 38.4 万 words ≈ 50 万 token(从 NotebookLM 官方统计字数算出来)。塞 prompt 的传统做法分两种场景:
https://github.com/icebear0828/notebooklm-client
最公平的对比是和"单 session 多轮对话"第二行,——同一研究会话里首轮建 cache、后续复用,是传统做法的最优情况。即使这样,5 轮问答贵档差出 17 倍($9.59 vs $0.55)。跨 session 场景只会更惨(86 倍)。
为什么 cache 帮不了传统做法?很多人以为"开了 cache 就万事大吉"。实际 Anthropic 的 prompt cache 默认只有付费档 1 小时),超时就自动失效;加上每次 claude -p 新起 session、思考停顿、切换别的窗口,都会把上一轮 cache 挤出窗口。
本文做法里论文压根不进 Claude,cache 命不命中都无所谓。
语料再翻倍(100 篇、200 篇)差距继续线性拉开——传统做法 cache_creation 随论文数线性涨,本文做法基本不变(只随老师答案长度微涨)。
用 Opus 跑研究的人:200 次研究会话一年就是小两千刀的差距——光"论文不进 Claude"这一个动作,一年省下的够再升一次 Max。
代价:慢 3 倍
操作 实测中位耗时 建 notebook + 加一个源 10-15 秒 NotebookLM chat 一次 16-48 秒(中位约 45 秒) Claude Opus 单问(不过 NotebookLM) 20-35 秒

如果你在乎每秒响应不是每月账单,这套不适合你。
接下来的几个部分,作为抛砖引玉,写了三个适合NotbookLM的工作流
五:学者 / 学生工作流
六:打新股 / 读招股书 工作流
七:个人知识库工作流
第五部分:研究者 / 学生工作流
reading list 是天然的知识边界。
痛点:一学期几十篇论文,同一批 PDF 要反复查几十次。以前 Ctrl-F 翻到眼花,问 ChatGPT 又怕它瞎编不带引用。
语料配方(灌一次用一学期):
-
20-50 篇课题相关论文 PDF
-
课程大纲、讲座字幕
-
导师邮件、自己的章节草稿、读书笔记
老师能回答的杀手问题:
-
"哪两篇结论互相冲突,冲突在哪一层假设?"
-
"X 方法在这个语料里出现过几次,各自怎么用的?"
-
"A 论文的公式 3 和 B 论文的公式 7 实际等价吗?"
Claude 在链路里干嘛:按课题推进——问老师拿概念/公式 → 写代码复现 → 跑实验 → 整理笔记。论文原文一次都不进 Claude 会话。
第六部分:打新股 / 读招股书工作流
一本招股书 300-600 页,打新窗口就三天。靠人读完再决策根本来不及。
痛点:港股/A 股打新节奏快,新股上市前只有聆讯后资料集(港股)或招股意向书(A 股)能看,文档动辄 500 页+,里面有公司介绍、历史沿革、业务模式、财务数据、募资用途、风险因素、基石投资者等 20+ 章节。靠人读:
-
一家看完至少 4 小时
-
一周 5-8 家新股,根本来不及
-
决策窗口就 72 小时,错过就只能下期再打
而且招股书最有信息量的不是"公司怎么夸自己",是藏在风险因素、关联交易、历次融资估值里的那些红旗。这部分人眼最容易漏。
语料配方(一家公司一个 notebook):
-
招股书全本(聆讯后资料集 / 招股意向书)——必灌,最核心
-
基石投资者披露表——看谁背书、锁定期多久
-
同行可比公司最新财报——估值对标的锚
-
保荐人/承销商研报(能搞到的话)——官方定价逻辑
-
管理层过往访谈、公司过去融资轮估值表——看估值跳涨节奏
-
行业监管政策文件(如医药的 NMPA、科技的相关新规)——决定行业天花板的外部变量
老师能回答的杀手问题:
判断要不要打,通常就问这 8 个——每个都是 200 页招股书里找半天的那种:
-
"核心产品/业务是什么?近 3 年收入结构变化如何?客户集中度?"
-
"这家和同行(A、B、C)在毛利率、营收增速、研发占比上的差异在哪?"
-
"基石投资者是谁、认购金额、锁定期?基石里有没有知名产业资本?"
-
"此次募资用途按比例拆,哪部分最大?募资完成后控股股东持股稀释到多少?"
-
"风险因素里,哪些是行业共性(可以对照同行打折看),哪些是公司特有(必须警惕)?"
-
"过往融资估值:上一轮估值 / IPO 估值的跳涨倍数?上轮投资人锁定期多久?"
-
"历史财务有没有一次性收益把利润做高的痕迹?过去 3 年经营现金流和净利润是否匹配?"
-
"关联交易占营收比多少?前五大客户里有没有关联方?"
每个问题都带 [页码] 引用——老师会直接把招股书里对应的那段甩给你,不用再翻 PDF。
Claude 在链路里干嘛:
批处理就是这个工作流的灵魂:
# 装客户端
npm i notebooklm-client
# 导出登录 session(会开浏览器登 Google)
npx notebooklm export-session
# 与笔记本对话
# npx notebooklm chat <notebook-id> --transport auto --question "帮我总结一下"
#安装后在 agent 中使用 `/notecraft` 即可自动化 NotebookLM 操作
npx notebooklm skill install
一周打新池 = [新股A, 新股B, 新股C, ...]
最后 Claude 把 8 家的一页汇总成一张 markdown 决策表 → 你 15 分钟扫完下单。
一周打新池 5-8 家 = 40-64 次查询,全程论文(这里是招股书)不进 Claude 对话——单本招股书 150-250k token,5 家就是 100 万 token 的语料量,传统做法光这一项一周就能烧掉 $50+。走本文做法 $2 以内。
真实打新场景的增量价值:
-
压缩决策时长:4 小时/家 → 20 分钟/家
-
红旗不会漏:8 个问题里第 5、7、8 项(风险、财务调整、关联交易)是散户最常忽略的,老师会逐条抠
-
跨家对比:港股同一周常有 3 家同行业公司同时招股,用同一套模板跑完直接能排序
第七部分:个人知识库工作流
给自己建"第二大脑"。
痛点:Obsidian 搜索只认关键词,答不出"我对 X 的看法这三年变过没"。所有笔记都是自己写的,合规上没顾虑,但体量散、格式杂,本地没工具能跨文件做语义检索。
语料配方(一股脑全灌,之后增量补):
-
Obsidian / Notion 全量导出
-
Kindle 高亮、Readwise 剪藏
-
工作日记、会议纪要、复盘文档
老师能回答的杀手问题:
-
"我这三年对'专注力'写过什么?观点变了吗?"
-
"《原则》和《思考快与慢》对认知偏差的说法,哪里重叠哪里冲突?"
-
"过去一个月所有会议纪要里,X 项目各人的态度分别是什么?"
Claude 在链路里干嘛:主题演进类问题本来就需要对话式 AI + 全量语料。Claude 负责把老师的多轮答案合成结构化总结(时间轴、观点对比表、待跟进清单)。
三个工作流的共同点:反复查、跨文档、私有边界——占任何一条,建库 15 秒成本一周内摊平。
最后
有一些值得注意的:
-
storage_state.json 里面是你 Google 的活 session。注意保管。
-
notebooklm-client 是逆向 NotebookLM 内部协议做出来的。Google 不认账,随时可能改后端让你的命令突然报错。
这套东西的核心就一句话——分工:
-
NotebookLM 当老师:答领域知识,带引用,不乱外推
-
Claude 当助手:编排工具、写代码、整理结果,不懂就问老师
-
你当课题负责人:只在关键决策点介入
我用了一个月,省下来的钱够再吃好几顿大餐。但更重要的是,调研十几篇论文不再让我心疼额度了——这种"不用算账"的爽,比省钱本身还上瘾。