
每天刷那么多信息,有用的记不住、存不下、找不到。
看到一篇好文章,丢进收藏夹吃灰;想做个行业周刊,每周手动复制粘贴、用翻译器转录、再搞排版,没干两周就放弃了。信息过载的时代,个人创作者最大的痛点其实不是“缺内容”,而是“缺自动化的工作流”。
那能不能一个人,不买云服务器,不掏月租,靠白嫖大厂的免费套餐,给自己搭一个“自动化内容工作台”?
完全可以。今天这篇,我们就用 Cloudflare 现成的五件套,搭一个 “AI 科技周刊自动生成器”。它能每天自动去抓你想看的信息源,让 AI 先做一轮中文摘要和分类,分好类存进数据库,最后自动发布成一个公开的网页。
这套体系不光能做周刊,你还可以把它改造成个人的第二大脑信息流、或者垂直领域的聚合站。
架构一览:五件套都在干嘛
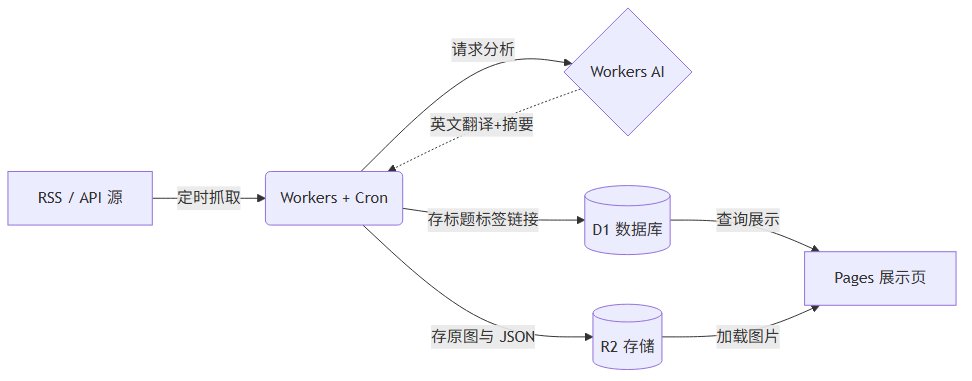
只要你有一个 Cloudflare 账号,就相当于拥有了一个全栈的云端机房。我们这条“流水线”会用到它家的 5 个核心服务:
npx wrangler d1 create content-db
# 我用 Cloudflare 免费搭了一套 AI 内容流水线,真的能跑起来
npx wrangler d1 execute content-db --local --file=schema.sql
# 我用 Cloudflare 免费搭了一套 AI 内容流水线,真的能跑起来
npx wrangler d1 execute content-db --remote --file=schema.sql
用人话解释一下它们的分工:
-
Workers + Cron:打工人+定时闹钟。每天定时去 Hacker News、RSS 源抓文章。
-
Workers AI:外包脑力。直接用 Llama 等开源大模型,先根据标题、链接或正文片段做中文摘要、推荐理由和标签;如果你接入正文抽取,也可以进一步做深度总结。
-
R2:大仓库。用来存抓下来的文章封面图、或者原始的超大 JSON 数据(免流量费)。
-
D1:账本。一个好用的数据库,存整理好的文章标题、链接、摘要内容。
-
Pages:门面。把 D1 里的数据渲染出来,做成别人能访问的静态网站。
不用担心开销,个人项目跑这套流程,Cloudflare 给的免费额度通常够用(文末有成本测算)。
下面我们一步步把这套流水线跑起来。
Step 1:用 Workers + Cron 定时抓取信息
第一步,我们需要一个“打工人”,每天定点去给我们收集素材。
在本地建好项目后,一切的配置都在 wrangler.toml 里搞定。我们要用 [triggers] 让 Worker 每天早上 8 点自动干活。
# 我用 Cloudflare 免费搭了一套 AI 内容流水线,真的能跑起来
[[r2_buckets]]
binding = "BUCKET"
bucket_name = "content-store"
对应的代码逻辑非常简单,写在 src/index.js 里:

这就完事了。一分钱不用花,你拥有了一个绝对不会睡过头的爬虫。
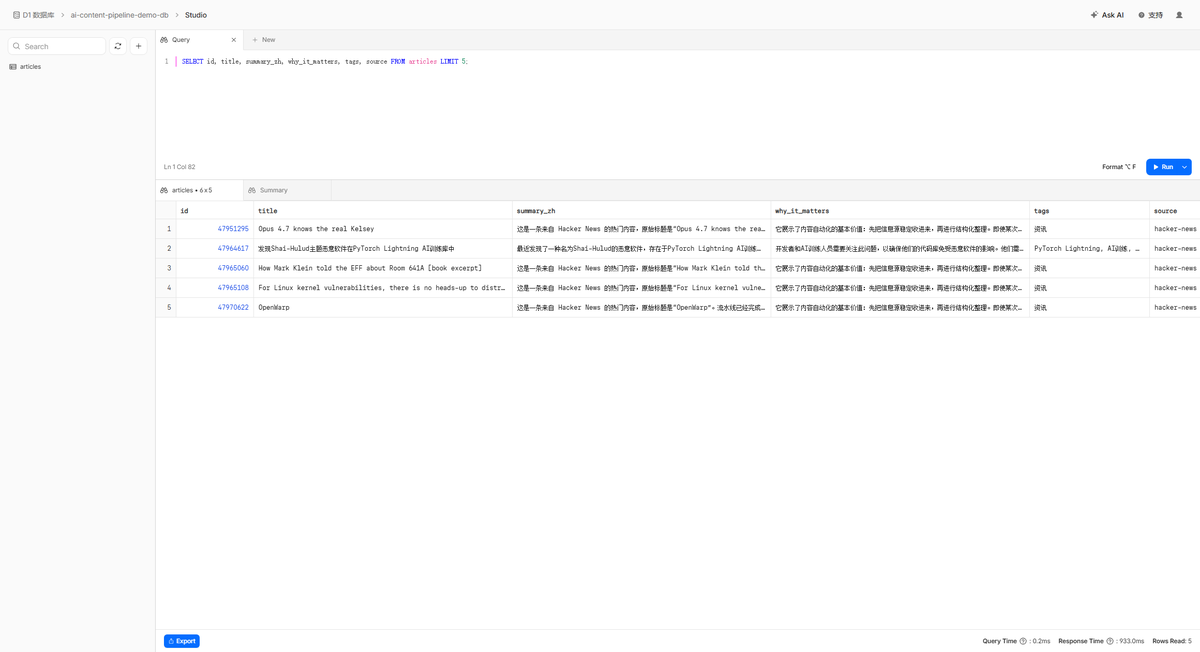
下面几张截图来自同一套流程的一次真实运行:Worker 从 Hacker News 抓取条目,AI 做中文整理,D1 保存结构化结果,R2 保留原始 JSON,最后由 Pages 展示出来。
Cloudflare 后台 - Worker 定时触发
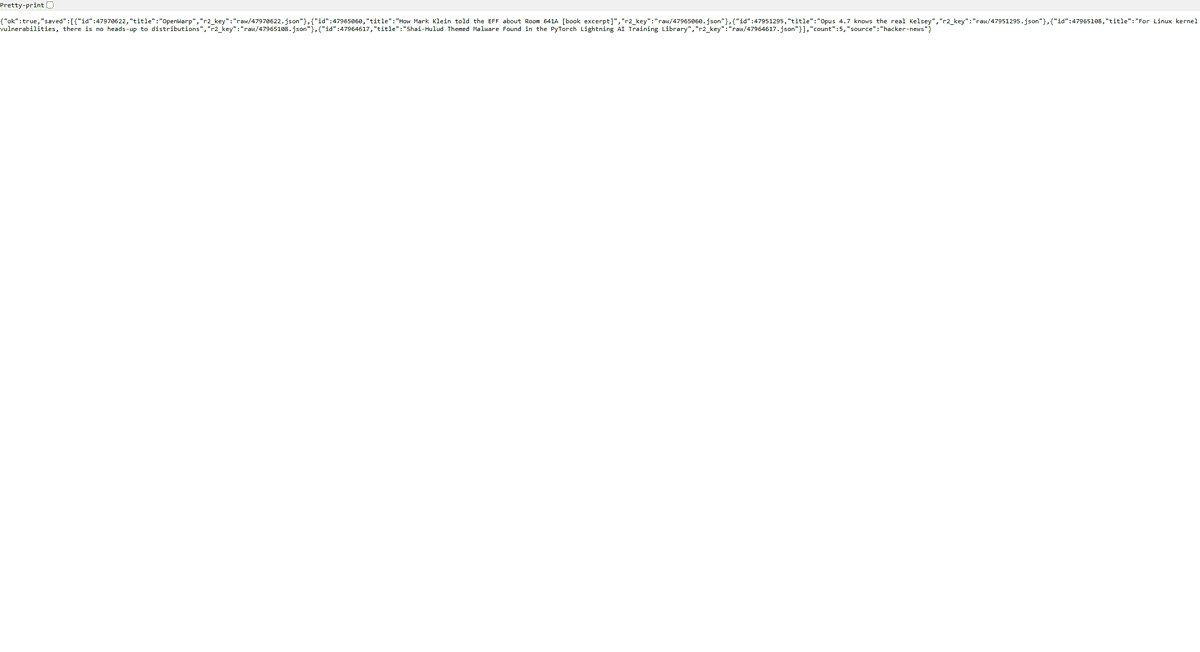
手动触发流水线结果
Step 2:用 Workers AI 做摘要、翻译、分类
文章信息抓回来了,但直接看英文标题和链接仍然很费时间。这时候就要让 AI 上场,先帮我们做一轮可读的中文整理。
在 wrangler.toml 里加上 AI 的绑定:
DROP TABLE IF EXISTS articles;
CREATE TABLE articles (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
summary_zh TEXT,
why_it_matters TEXT,
tags TEXT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
Cloudflare 贴心地在边缘节点上部署了各种开源大模型(比如 Llama 3 系列),可以直接调,不需要你再去 OpenAI 注册账号充 API。
我们在刚才的代码里加上 processArticles 函数:
// 续写上文的代码
async function saveToStorage(article, env) {
const fileKey = `raw/${article.id}.json`;
// 直接丢进 R2
await env.BUCKET.put(fileKey, JSON.stringify(article));
return fileKey;
}
这里先用最基本的 prompt 演示标题和链接级别的整理。如果你要做深度处理,还可以让 Worker 去 fetch 原文页面的 HTML,提取正文后再喂给 AI 做深度总结。
Step 3:用 R2 存图片和原始资料
结构化的数据存数据库,那些大块头的杂物(比如抓下来的文章配图、很长的原始 JSON)存哪里?放 D1 太浪费,放 R2 刚好。
R2 是 Cloudflare 的对象存储,适合放原始 JSON、图片和网页快照这类大文件。它的一个重要优势是没有传统云存储常见的出站流量费用。
加配置,在本地创建一个叫 content-store 的 R2 bucket 并绑定:
[[d1_databases]]
binding = "DB"
database_name = "content-db"
database_id = "终端里吐出来的那个ID"

在代码里把原始抓取的数据存个档,留着以后分析:
[ai]
binding = "AI"
以后如果前端要配图,直接把图抓下来 env.BUCKET.put() 进去。需要注意的是,R2 里的文件默认不是公开的,想让网页直接访问图片,还要给 bucket 开启公开访问、绑定自定义域名,或者由 Worker 生成临时访问链接。
R2 原始 JSON 数据

Step 4:用 D1 存文章、链接、标签
终于来到核心部分了。AI 整理好的精炼内容,我们要存在 D1 数据库里。D1 其实就是一个 Serverless 的 SQLite,极其轻量且不用管运维。
先建表,写一个 schema.sql:
async function processArticles(articles, env) {
for (let article of articles) {
if (!article.url) continue;
const prompt = `
请将以下新闻标题和链接整理成严格 JSON,不要输出 Markdown。
字段包括:
- title_zh:中文标题
- summary_zh:2-3 句话中文摘要,只根据标题和链接做保守判断
- why_it_matters:1-2 句话说明它为什么值得创作者或开发者关注
- tags:2-3 个分类标签数组
原文标题:${article.title}
原文链接:${article.url}
`;
// 调免费的 Llama 3 8B 模型干活
const aiResponse = await env.AI.run('@cf/meta/llama-3.1-8b-instruct-fast', {
messages: [{ role: "user", content: prompt }]
});
const aiResult = aiResponse.response;
// 假设 AI 返回了我们需要的结构化数据
console.log("AI 处理结果:", aiResult);
// 接下来我们要把它存起来
await saveToDatabase(article, aiResult, env);
}
}
执行命令创建数据库和表结构:
# 我用 Cloudflare 免费搭了一套 AI 内容流水线,真的能跑起来
name = "ai-content-pipeline"
main = "src/index.js"
compatibility_date = "2026-04-30"
# 我用 Cloudflare 免费搭了一套 AI 内容流水线,真的能跑起来
[triggers]
crons = ["0 0 * * *"]
更新 wrangler.toml:
// 当访问 /api/articles 时触发
export async function onRequest(context) {
// 从绑定的 D1 里查数据
const { results } = await context.env.DB.prepare(
"SELECT * FROM articles ORDER BY created_at DESC LIMIT 20"
).all();
return Response.json(results);
}
回到我们的 Worker 代码,把 AI 处理完的数据塞进去:
async function saveToDatabase(article, aiResult, env) {
// 假设我们解析了 AI 的结果
const zhTitle = "AI 生成的中文标题";
const summary = "2-3 句话中文摘要";
const whyItMatters = "这条内容为什么值得看";
const tags = "AI, 自动化, 资讯";
// 用标准的 SQL 写入 D1
await env.DB.prepare(
`INSERT INTO articles (id, title, url, summary_zh, why_it_matters, tags)
VALUES (?, ?, ?, ?, ?, ?)
ON CONFLICT(id) DO NOTHING`
).bind(article.id, zhTitle, article.url, summary, whyItMatters, tags).run();
}
至此,一个最小版的后台自动抓取流水线已经能跑通了。上面的代码为了讲清楚流程做了简化:AI 返回结果还需要按中文标题、多段摘要、推荐理由、标签拆开,R2 存档函数也要接进主流程。把这些补齐后,只等每天早上 8 点,内容就会源源不断地自动流进你的数据库里。
Cloudflare 后台 - D1 数据表
D1 数据接口返回
Step 5:用 Pages 展示成公开网站
光有数据库不行,得让人能看到。最后一步,我们用 Cloudflare Pages 搭一个极简的前端展示页。
Pages 自带了 Functions 功能(基于 Workers),所以我们连后端 API 都不用单独部署,直接在 Pages 项目里建一个 functions/api/articles.js。不过这类接口请求会按 Workers 的规则计入用量,不能简单理解成“Pages 页面访问无限,所以接口也无限”。
export default {
// 这是 Cron 定时触发的入口
async scheduled(event, env, ctx) {
// 1. 去源头抓数据 (这里拿 Hacker News 举例)
const hnResponse = await fetch("https://hacker-news.firebaseio.com/v0/topstories.json");
const storyIds = await hnResponse.json();
// 取前 5 篇
const top5Ids = storyIds.slice(0, 5);
let articles = [];
for (let id of top5Ids) {
const itemRes = await fetch(`https://hacker-news.firebaseio.com/v0/item/${id}.json`);
const item = await itemRes.json();
articles.push(item);
}
// 把文章传给下一步处理 (见下文)
await processArticles(articles, env);
}
};
然后在同目录下写一个普通的 index.html,用点基础的 JS 去调这个接口:
<!DOCTYPE html>
<html>
<head>
<title>我的 AI 科技周刊</title>
</head>
<body>
<h1>每日 AI 科技精选</h1>
<div id="content"></div>
<script>
fetch('/api/articles')
.then(res => res.json())
.then(data => {
const html = data.map(article => `
<div style="margin-bottom: 20px; padding: 15px; border: 1px solid #eee;">
<h3><a href="${article.url}">${article.title}</a></h3>
<p><strong>摘要:</strong>${article.summary_zh}</p>
<p><strong>为什么值得看:</strong>${article.why_it_matters}</p>
<p><small>标签:${article.tags}</small></p>
</div>
`).join('');
document.getElementById('content').innerHTML = html;
});
</script>
</body>
</html>
在 Dashboard 里新建一个 Pages 项目,把这俩文件扔上去,或者用命令行一键部署。连上 D1 binding,你的个人内容订阅站就正式上线了。
最终展示页
npx wrangler r2 bucket create content-store
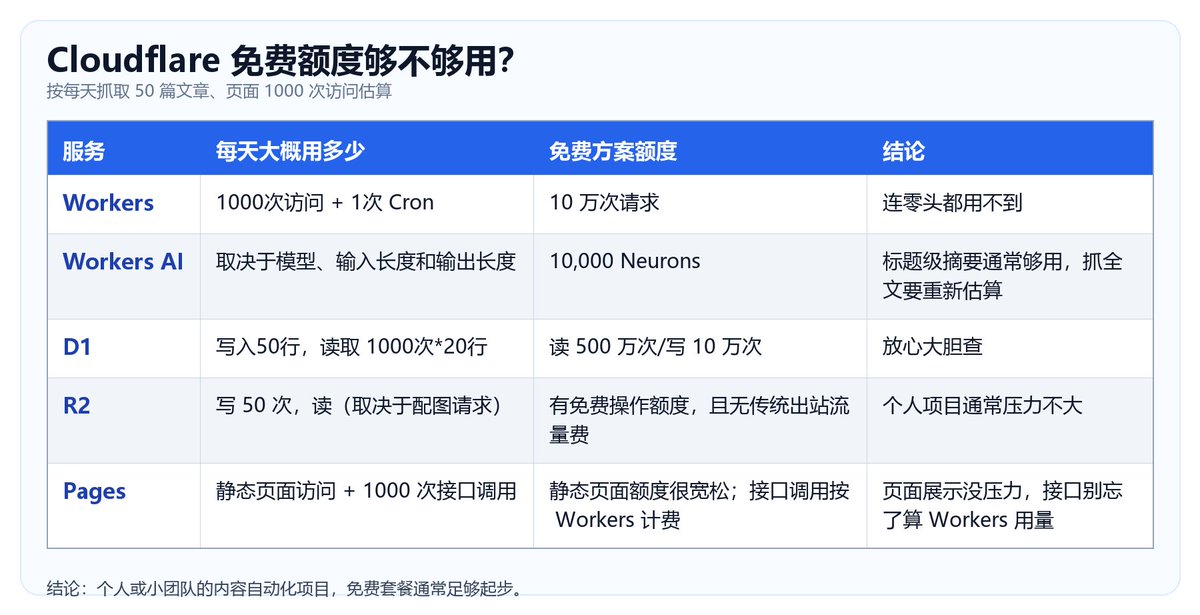
免费额度到底够不够用?
很多朋友一听到“全家桶”,第一反应就是“这跑起来不得破产?”
我们来算笔账。假设你搞的这个周刊,每天自动抓取 50 篇 文章进行 AI 翻译和总结,你的前端页面每天有 1000 次 访问。
结论很明确:只要你不拿它做商业级别的大型爬虫,对于个人或者小团队的内容流自动化,Cloudflare 的免费套餐通常已经足够起步。真正上线前,还是建议按自己的抓取频率、AI 输出长度和访问量重新算一遍。
几个防踩坑与进阶玩法
-
Cron 触发的超时问题:免费版 Workers 有 CPU 运行时间限制。如果你一次性抓 100 篇文章喂给 AI,很可能会超时。建议用多个短频快的定时任务(比如每 2 小时抓 5 篇),或者利用 Queue 把抓取和 AI 分析拆成异步。
-
AI 的神经元(Neurons)计算:Workers AI 现在的免费额度是按 Neurons 算的。尽量选 @cf/meta/llama-3.1-8b-instruct-fast 这样的小且快模型,便宜好用。
-
加点“料”:Vectorize 语义搜索:如果你想在页面上加一个“按意思搜文章”的功能,可以把 AI 生成的文本再过一遍 Embedding 模型,存进 Cloudflare Vectorize 库里,瞬间变成高阶版的 RAG。
-
邮件推送:如果还想做邮件版周刊,可以再接邮件发送服务或 Cloudflare 的邮件相关能力。这里要注意,收信转发、处理来信和主动发信不是一回事,具体实现前要先确认当前账号可用的发送方式。
结语
从抓取、清洗、AI 提炼、存储、到最终的发布。我们只用了不到两百行代码,零服务器成本,就在云端拼起了一个完整的“编辑部”。
这就是 Serverless + AI 带来的恐怖生产力。你不需要再陷在日常的 Ctrl+C 和 Ctrl+V 里,那些重复的信息筛选工作,完全可以交给机器在你看不到的边缘节点上默默完成。
如果你也有兴趣搞这么一套,可以先去官网注册个账号。准备好你的 API 源,建个 D1 跑跑看。
你手头现在最想自动化的是什么内容流?小红书笔记?竞品公众号?还是投资研报?在评论区聊聊,没准你的痛点大家都有同感。更多 AI 干货同步更新公众号:雨哥聊AI,关注我带你玩转 AI 时代!