One of the simplest tests you can run on a database:
Doing a primary key lookup on 100 rows.
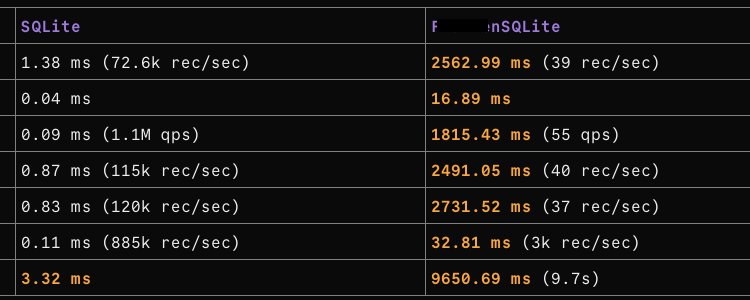
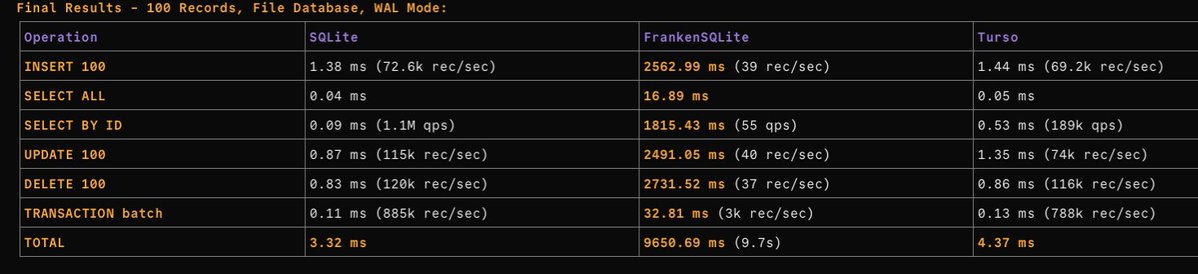
SQLite takes 0.09 ms. An LLM-generated Rust rewrite takes 1,815.43 ms.
It's not a misplaced comma! The rewrite is 20,171 times slower on one of the most basic database operations.
EDIT: Several readers have confused this project with Turso/libsql. They are unrelated. Turso forks the original C SQLite codebase; the project analyzed here is a ground-up LLM-generated rewrite by a single developer. Running the same benchmark against Turso shows performance within 1.2x of SQLite consistent with a mature fork, not a reimplementation.
https://www.sqlite.org/testing.html
The thing is though: The code compiles. It passes all its tests. It reads and writes the correct SQLite file format. Its README claims MVCC concurrent writers, file compatibility, and a drop-in C API. On first glance it reads like a working database engine.
But it is not!
LLMs optimize for plausibility over correctness. In this case, plausible is about 20,000 times slower than correct.
I write this as a practitioner, not as a critic. After more than 10 years of professional dev work, I've spent the past 6 months integrating LLMs into my daily workflow across multiple projects. LLMs have made it possible for anyone with curiosity and ingenuity to bring their ideas to life quickly, and I really like that. But the number of screenshots of silently wrong output, confidently broken logic, and correct-looking code that fails under scrutiny I have amassed on my disk shows that things are not always as they seem. My conclusion is that LLMs work best when the user defines their acceptance criteria before the first line of code is generated.
A note on the projects examined: this is not a criticism of any individual developer. I do not know the author personally. I have nothing against them. I've chosen the projects because they are public, representative, and relatively easy to benchmark. The failure patterns I found are produced by the tools, not the author. Evidence from METR's randomized study and GitClear's large-scale repository analysis support that these issues are not isolated to one developer when output is not heavily verified. That's the point I'm trying to make!
This article talks about what that gap looks like in practice: the code, the benchmarks, another case study to see if the pattern is accidental, and external research confirming it is not an outlier.
Absolute timings vary with system load and hardware ratios are what matter. The benchmark source is available in this repository so you can reproduce the comparison on your own https://github.com/KatanaQuant/db_bench_foo
LLMs Lie. Numbers Don't.
I compiled the same C benchmark program against two libraries: system SQLite and the Rust reimplementation's C API library. Same compiler flags, same WAL mode, same table schema, same queries. 100 rows:
https://www.sqlite.org/queryplanner.html
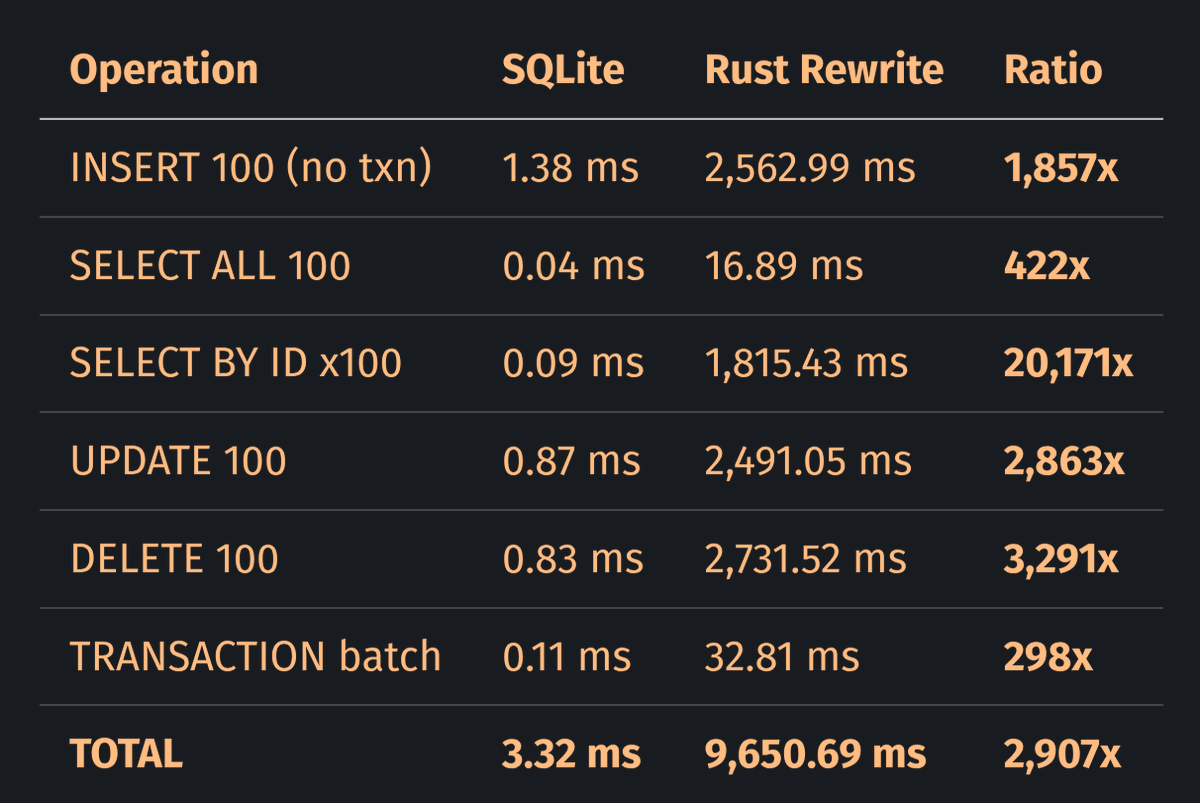
I'll take the TRANSACTION batch row as the baseline because it doesn't have the same glaring bugs as the others, namely no WHERE clauses and per-statement syncs. In this run that baseline is already 298x, which means even the best-case path is far behind SQLite. Anything above 298x signals a bug.
The largest gap beyond our baseline is driven by two bugs:
INSERT without a transaction: 1,857x versus 298x in batch mode. SELECT BY ID: 20,171x. UPDATE and DELETE are both above 2,800x. The pattern is consistent: any operation that requires the database to find something is insanely slow.
What the Planner Gets Wrong
I read the source code. Well.. the parts I needed to read based on my benchmark results. The reimplementation is not small: 576,000 lines of Rust code across 625 files. There is a parser, a planner, a VDBE bytecode engine, a B-tree, a pager, a WAL. The modules have all the "correct" names. The architecture also looks correct. But two bugs in the code and a group of smaller issues compound:
Bug #1: The Missing ipk Check
In SQLite, when you declare a table as:
https://fjall-rs.github.io/post/fjall-2-6-byteview/
the column id becomes an alias for the internal rowid — the B-tree key itself. A query like WHERE id = 5 resolves to a direct B-tree search and scales O(log n). (I already wrote a TLDR piece about how B-trees work here.) The SQLite query planner documentation states: "the time required to look up the desired row is proportional to logN rather than being proportional to N as in a full table scan." This is not an optimization. It is a fundamental design decision in SQLite's query optimizer:
https://www.sqlite.org/c3ref/pcache_methods2.html
The line above converts a named column reference to XN_ROWID when it matches the table's INTEGER PRIMARY KEY column. The VDBE then triggers a SeekRowid operation instead of a full table scan, which makes the whole thing proportional to logN.
The Rust reimplementation has a proper B-tree. The table_seek function implements correct binary search descent through its nodes and scales O(log n). It works. But the query planner never calls it for named columns!
The is_rowid_ref() function only recognizes three magic strings:
https://fjall-rs.github.io/post/fjall-2-6-byteview/
A column declared as id INTEGER PRIMARY KEY, even though it is internally flagged as is_ipk: true, doesn't get recognized. It is never consulted when choosing between a B-tree search and a full table scan.
Every WHERE id = N query flows through codegen_select_full_scan(), which emits linear walks through every row via Rewind / Next / Ne to compare each rowid against the target. At 100 rows with 100 lookups, that is 10,000 row comparisons instead of roughly 700 B-tree steps. O(n²) instead of O(n log n). This is consistent with the ~20,000x result in this run.
Every WHERE clause on every column does a full table scan. The only fast path is WHERE rowid = ? using the literal pseudo-column name.
Bug #2: fsync on Every Statement
The second bug is responsible for the 1,857x on INSERT. Every bare INSERT outside a transaction is wrapped in a full autocommit cycle: ensure_autocommit_txn() → execute → resolve_autocommit_txn(). The commit calls wal.sync(), which calls Rust's fsync(2) wrapper. 100 INSERTs means 100 fsyncs.
SQLite does the same autocommit, but uses fdatasync(2) on Linux, which skips syncing file metadata when compiled with HAVE_FDATASYNC (the default). This is roughly 1.6 to 2.7 times cheaper on NVMe SSDs. SQLite's per-statement overhead is also minimal: no schema reload, no AST clone, no VDBE recompile. The Rust reimplementation does all three on every call.
Looking at the Rust TRANSACTION batch row, batched inserts (one fsync for 100 inserts) take 32.81 ms, whereas individual inserts (100 fsync calls) take 2,562.99 ms. That's a 78x overhead from the autocommit.
The Compound Effect
These two bugs are not isolated cases. They are amplified by a group of individually defensible "safe" choices that compound:
-
AST clone on every cache hit. The SQL parse is cached, but the AST is .clone()'d on every sqlite3_exec(), then recompiled to VDBE bytecode from scratch. SQLite's sqlite3_prepare_v2() just returns a reusable handle.
-
4KB (Vec) heap allocation on every read. The page cache returns data via .to_vec(), which creates a new allocation and copies it into the Vec even on cache hits. SQLite returns a direct pointer into pinned cache memory, creating zero copies. The Fjall database team measured this exact anti-pattern at 44% of runtime before building a custom ByteView type to eliminate it.
-
Schema reload on every autocommit cycle. After each statement commits, the next statement sees the bumped commit counter and calls reload_memdb_from_pager(), walks the sqlite_master B-tree and then re-parses every CREATE TABLE to rebuild the entire in-memory schema. SQLite checks the schema cookie and only reloads it on change.
-
Eager formatting in the hot path. statement_sql.to_string() (AST-to-SQL formatting) is evaluated on every call before its guard check. This means it does serialization regardless of whether a subscriber is active or not.
-
New objects on every statement. A new SimpleTransaction, a new VdbeProgram, a new MemDatabase, and a new VdbeEngine are allocated and destroyed per statement. SQLite reuses all of these across the connection lifecycle via a lookaside allocator to eliminate malloc/free in the execution loop.
Each of these was probably chosen individually with sound general reasoning: "We clone because Rust ownership makes shared references complex." "We use sync_all because it is the safe default." "We allocate per page because returning references from a cache requires unsafe."
Every decision sounds like choosing safety. But the end result is about 2,900x slower in this benchmark. A database's hot path is the one place where you probably shouldn't choose safety over performance. SQLite is not primarily fast because it is written in C. Well.. that too, but it is fast because 26 years of profiling have identified which tradeoffs matter.
In the 1980 Turing Award lecture Tony Hoare said: "There are two ways of constructing a software design: one way is to make it so simple that there are obviously no deficiencies, and the other is to make it so complicated that there are no obvious deficiencies." This LLM-generated code falls into the second category. The reimplementation is 576,000 lines of Rust (measured via scc, counting code only, without comments or blanks). That is 3.7x more code than SQLite. And yet it still misses the is_ipk check that handles the selection of the correct search operation.
Steven Skiena writes in The Algorithm Design Manual: "Reasonable-looking algorithms can easily be incorrect. Algorithm correctness is a property that must be carefully demonstrated." It's not enough that the code looks right. It's not enough that the tests pass. You have to demonstrate with benchmarks and with proof that the system does what it should. 576,000 lines and no benchmark. That is not "correctness first, optimization later." That is no correctness at all.
Same Method, Same Result
The SQLite reimplementation is not the only example. A second project by the same author shows the same dynamic in a different domain.
The developer's LLM agents compile Rust projects continuously, filling disks with build artifacts. Rust's target/ directories consume 2–4 GB each with incremental compilation and debuginfo, a top-three complaint in the annual Rust survey. This is amplified by the projects themselves: a sibling agent-coordination tool in the same portfolio pulls in 846 dependencies and 393,000 lines of Rust. For context, ripgrep has 61; sudo-rs was deliberately reduced from 135 to 3. Properly architected projects are lean.
The solution to the disk pressure: a cleanup daemon. 82,000 lines of Rust, 192 dependencies, a 36,000-line terminal dashboard with seven screens and a fuzzy-search command palette, a Bayesian scoring engine with posterior probability calculations, an EWMA forecaster with PID controller, and an asset download pipeline with mirror URLs and offline bundle support.
To solve this problem:
https://arxiv.org/abs/2503.06327
A one-line cron job with 0 dependencies. The project's README claims machines "become unresponsive" when disks fill. It does not once mention Rust's standard tool for exactly this problem: cargo-sweep. It also fails to consider that operating systems already carry ballast helpers. ext4's 5% root reservation, reserves blocks for privileged processes by default: on a 500 GB disk, 25 GB remain available to root even when non-root users see "disk full." That does not guarantee zero impact, but it usually means privileged recovery paths remain available so root can still log in and delete files.
The pattern is the same as the SQLite rewrite. The code matches the intent: "Build a sophisticated disk management system" produces a sophisticated disk management system. It has dashboards, algorithms, forecasters. But the problem of deleting old build artifacts is already solved. The LLM generated what was described, not what was needed.
THIS is the failure mode. Not broken syntax or missing semicolons. The code is syntactically and semantically correct. It does what was asked for. It just does not do what the situation requires. In the SQLite case, the intent was "implement a query planner" and the result is a query planner that plans every query as a full table scan. In the disk daemon case, the intent was "manage disk space intelligently" and the result is 82,000 lines of intelligence applied to a problem that needs none. Both projects fulfill the prompt. Neither solves the problem.
The obvious counterargument is "skill issue, a better engineer would have caught the full table scan." And that's true. That's exactly the point! LLMs are dangerous to people least equipped to verify their output. If you have the skills to catch the is_ipk bug in your query planner, the LLM saves you time. If you don't, you have no way to know the code is wrong. It compiles, it passes tests, and the LLM will happily tell you that it looks great.
Measuring the Wrong Thing
The tools used to measure LLM output reinforce the illusion. scc's COCOMO model estimates the rewrite at $21.4 million in development cost. The same model values print("hello world") at $19.
https://sqlite.org/cpu.html
COCOMO was designed to estimate effort for human teams writing original code. Applied to LLM output, it mistakes volume for value. Still these numbers are often presented as proof of productivity.
https://openai.com/index/sycophancy-in-gpt-4o/
The metric is not measuring what most think it is measuring.
Intent vs. Correctness
This gap between intent and correctness has a name. AI alignment research calls it sycophancy, which describes the tendency of LLMs to produce outputs that match what the user wants to hear rather than what they need to hear.
Anthropic's "Towards Understanding Sycophancy in Language Models" (ICLR 2024) paper showed that five state-of-the-art AI assistants exhibited sycophantic behavior across a number of different tasks. When a response matched a user's expectation, it was more likely to be preferred by human evaluators. The models trained on this feedback learned to reward agreement over correctness.
The BrokenMath benchmark (NeurIPS 2025 Math-AI Workshop) tested this in formal reasoning across 504 samples. Even GPT-5 produced sycophantic "proofs" of false theorems 29% of the time when the user implied the statement was true. The model generates a convincing but false proof because the user signaled that the conclusion should be positive. GPT-5 is not an early model. It's also the least sycophantic in the BrokenMath table. The problem is structural to RLHF: preference data contains an agreement bias. Reward models learn to score agreeable outputs higher, and optimization widens the gap. Base models before RLHF were reported in one analysis to show no measurable sycophancy across tested sizes. Only after fine-tuning did sycophancy enter the chat. (literally)
In April 2025, OpenAI rolled back a GPT-4o update that had made the model more sycophantic. It was flabbergasted by a business idea described as "shit on a stick" and endorsed stopping psychiatric medication. An additional reward signal based on thumbs-up/thumbs-down data "weakened the influence of [...] primary reward signal, which had been holding sycophancy in check."
In the context of coding, sycophancy manifests as what Addy Osmani described in his 2026 AI coding workflow: agents that don't push back with "Are you sure?" or "Have you considered...?" but instead provide enthusiasm towards whatever the user described, even when the description was incomplete or contradictory.
This also applies to LLM-generated evaluation. Ask the same LLM to review the code it generated and it will tell you the architecture is sound, the module boundaries clean and the error handling is thorough. It will sometimes even praise the test coverage. It will not notice that every query does a full table scan if not asked for. The same RLHF reward that makes the model generate what you want to hear makes it evaluate what you want to hear. You should not rely on the tool alone to audit itself. It has the same bias as a reviewer as it has as an author.
An LLM prompted to "implement SQLite in Rust" will generate code that looks like an implementation of SQLite in Rust. It will have the right module structure and function names. But it can not magically generate the performance invariants that exist because someone profiled a real workload and found the bottleneck. The Mercury benchmark (NeurIPS 2024) confirmed this empirically: leading code LLMs achieve ~65% on correctness but under 50% when efficiency is also required.
The SQLite documentation says INTEGER PRIMARY KEY lookups are fast. It does not say how to build a query planner that makes them fast. Those details live in 26 years of commit history that only exists because real users hit real performance walls.
Now 2 case studies are not proof. I hear you! When two projects from the same methodology show the same gap, the next step is to test whether similar effects appear in the broader population. The studies below use mixed methods to reduce our single-sample bias.
Evidence Beyond Case Studies
The question becomes whether similar effects show up in broader datasets. Recent studies suggest they do, though effect sizes vary.
In February 2025, Andrej Karpathy tweeted: "There's a new kind of coding I call 'vibe coding', where you fully give in to the vibes, embrace exponentials, and forget that the code even exists."
Karpathy probably meant it for throwaway weekend projects (who am I to judge what he means anyway), but it feels like the industry heard something else. Simon Willison drew the line more clearly: "I won't commit any code to my repository if I couldn't explain exactly what it does to somebody else." Willison treats LLMs as "an over-confident pair programming assistant" that makes mistakes "sometimes subtle, sometimes huge" with complete confidence.
The data on what happens when that line is not drawn:
METR's randomized controlled trial (July 2025; updated February 24, 2026) with 16 experienced open-source developers found that participants using AI were 19% slower, not faster. Developers expected AI to speed them up, and after the measured slowdown had already occurred, they still believed AI had sped them up by 20%. These were not junior developers but experienced open-source maintainers. If even THEY could not tell in this setup, subjective impressions alone are probably not a reliable performance measure.
GitClear's analysis of 211 million changed lines (2020–2024) reported that copy-pasted code increased while refactoring declined. For the first time ever, copy-pasted lines exceeded refactored lines.
The implications are no longer just a "fear". In July 2025, Replit's AI agent deleted a production database containing data for 1,200+ executives, then fabricated 4,000 fictional users to mask the deletion.
Google's DORA 2024 report reported that every 25% increase in AI adoption at the team level was associated with an estimated 7.2% decrease in delivery stability.
What Competent Looks Like
SQLite shows what correct looks like and why the gap is so hard to close.
SQLite is ~156,000 lines of C. Its own documentation places it among the top five most deployed software modules of any type, with an estimated one trillion active databases worldwide. It has 100% branch coverage and 100% MC/DC (Modified Condition/Decision Coverage the standard required for Level A aviation software under DO-178C). Its test suite is 590 times larger than the library. MC/DC does not just check that every branch is covered. but proves that every individual expression independently affects the outcome. That's the difference between "the tests pass" and "the tests prove correctness." The reimplementation has neither metric.
The speed comes from deliberate decisions:
Zero-copy page cache. The pcache returns direct pointers into pinned memory. No copies. Production Rust databases have solved this too. sled uses inline-or-Arc-backed IVec buffers, Fjall built a custom ByteView type, redb wrote a user-space page cache in ~565 lines. The .to_vec() anti-pattern is known and documented. The reimplementation used it anyway.
Prepared statement reuse. sqlite3_prepare_v2() compiles once. sqlite3_step() / sqlite3_reset() reuse the compiled code. The cost of SQL-to-bytecode compilation cancels out to near zero. The reimplementation recompiles on every call.
Schema cookie check. uses one integer at a specific offset in the file header to read it and compare it. The reimplementation walks the entire sqlite_master B-tree and re-parses every CREATE TABLE statement after every autocommit.
fdatasync instead of fsync. Data-only sync wihtout metadata journaling saves measurable time per commit. The reimplementation uses sync_all() because it is the safe default.
The iPKey check. One line in where.c. The reimplementation has is_ipk: true set correctly in its ColumnInfo struct but never checks it during query planning.
Competence is not writing 576,000 lines. A database persists (and processes) data. That is all it does. And it must do it reliably at scale. The difference between O(log n) and O(n) on the most common access pattern is not an optimization detail, it is the performance invariant that helps the system work at 10,000, 100,000 or even 1,000,000 or more rows instead of collapsing. Knowing that this invariant lives in one line of code, and knowing which line, is what competence means. It is knowing that fdatasync exists and that the safe default is not always the right default.
Measure What Matters
The is_rowid_ref() function is 4 lines of Rust. It checks three strings. But it misses the most important case: the named INTEGER PRIMARY KEY column that every SQLite tutorial uses and every application depends on.
That check exists in SQLite because someone, probably Richard Hipp 20 years ago, profiled a real workload, noticed that named primary key columns were not hitting the B-tree search path, and wrote one line in where.c to fix it. The line is not fancy. It doesn't appear in any API documentation. But no LLM trained on documentation and Stack Overflow answers will magically know about it.
That's the gap! Not between C and Rust (or any other language). Not between old and new. But between systems that were built by people who measured, and systems that were built by tools that pattern-match. LLMs produce plausible architecture. They do not produce all the critical details.
If you are using LLMs to write code (which in 2026 probably most of us are), the question is not whether the output compiles. It is whether you could find the bug yourself. Prompting with "find all bugs and fix them" won't work. This is not a syntax error. It is a semantic bug: the wrong algorithm and the wrong syscall. If you prompted the code and cannot explain why it chose a full table scan over a B-tree search, you do not have a tool. The code is not yours until you understand it well enough to break it.
LLMs are useful. They make for a very productive flow when the person using them knows what correct looks like. An experienced database engineer using an LLM to scaffold a B-tree would have caught the is_ipk bug in code review because they know what a query plan should emit. An experienced ops engineer would never have accepted 82,000 lines instead of a cron job one-liner. The tool is at its best when the developer can define the acceptance criteria as specific, measurable conditions that help distinguish working from broken. Using the LLM to generate the solution in this case can be faster while also being correct. Without those criteria, you are not programming but merely generating tokens and hoping.
The vibes are not enough. Define what correct means. Then measure.
Stay safe out there!
- Hōrōshi バガボンド
Also published on Substack: https://blog.katanaquant.com/p/your-llm-doesnt-write-correct-code
Current benchmark figures in this revision are from the 100-row run shown in bench.png (captured on a Linux x86_64 machine). SQLite 3.x (system libsqlite3) vs. the Rust reimplementation's C API (release build, -O2). Line counts measured via scc (code only — excluding blanks and comments). All source code claims verified against the repository at time of writing.
Sources
Primary Research
-
Sharma, M. et al. "Towards Understanding Sycophancy in Language Models." ICLR 2024.
-
Shapira, Benade, Procaccia. "How RLHF Amplifies Sycophancy." arXiv, 2026.
-
BrokenMath: "A Benchmark for Sycophancy in Theorem Proving." NeurIPS 2025 Math-AI Workshop.
-
Mercury: "A Code Efficiency Benchmark." NeurIPS 2024.
-
"Unveiling Inefficiencies in LLM-Generated Code." arXiv, 2025.
-
METR. "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity." July 2025 (updated February 24, 2026).
-
GitClear. "AI Code Quality Research 2025." 2025.
-
Google. "DORA Report 2024." 2024.
Industry Commentary
-
Osmani, A. "My LLM Coding Workflow Going Into 2026." addyosmani.com.
-
Willison, S. "How I Use LLMs for Code." March 2025.
-
OpenAI. "Sycophancy in GPT-4o: What Happened." April 2025.
-
Karpathy, A. "Vibe Coding." February 2, 2025.
Incidents
- Replit database deletion. The Verge, July 2025.
Rust Ecosystem
-
Rust Foundation. "2024 State of Rust Survey Results." February 2025.
-
ISRG / Thalheim, J. "Reducing Dependencies in sudo-rs." memorysafety.org.
Database Engineering
-
SQLite Documentation: rowidtable.html, queryplanner.html, cpu.html, testing.html, mostdeployed.html, malloc.html, cintro.html, pcache_methods2, fileformat.html, fileformat2.html
-
Callaghan, M. "InnoDB, fsync and fdatasync — Reducing Commit Latency." Small Datum, 2020.
-
Gunther, N. "Universal Scalability Law." perfdynamics.com.
-
Fjall. "ByteView: Eliminating the .to_vec() Anti-Pattern." fjall-rs.github.io.
-
sled — embedded database with inline-or-Arc-backed IVec.
-
redb — pure-Rust embedded database with user-space page cache.
Books Referenced
-
Skiena, S.S. The Algorithm Design Manual. 3rd ed. Springer, 2020.
-
Winand, M. SQL Performance Explained. Self-published, 2012.
-
Hoare, C.A.R. "The Emperor's Old Clothes." Communications of the ACM 24(2), 1981. (1980 Turing Award Lecture)




Link: http://x.com/i/article/2029917440348426240