
What does it mean for agents to understand a company?
Not search across its tools. Not retrieve its documents. Understand it.
The way a great chief of staff understands the company after six months. They know who actually makes decisions, not just who's on the org chart. They know which Slack channel has the real conversation and which one is performative. They know the CRM says the deal closed in March but the handshake happened in January over a dinner nobody documented. They know what changed last week and why it matters this week.
That understanding comes from synthesis. Watching hundreds of signals across dozens of sources and building a model of reality that's more accurate than any single source.
No agent does this today.
You deploy agents across your company. You connect them to your tools with MCP servers or API integrations. Your agents can search Slack, read Google Drive, query your CRM. You've given them access to everything.
They still don't understand anything.
Ask your agent who owns the relationship with your biggest customer. It searches Gmail, finds a recent thread, gives you a name. Ask it again from a different tool and you get a different name. Ask about your top priorities this quarter and it pulls from whatever strategic document it finds first, even if that document is six months old and three pivots behind.
The failure mode is not that the agent can't find information. The failure mode is that it finds too much, can't tell what's current, can't resolve conflicts between sources, and confidently presents a fragment as the whole truth.
Access means the agent can reach your data. Understanding means the agent knows what that data means in the context of everything else. A new employee with access to your Google Drive, Slack, and CRM has access. After six months of absorbing context, attending meetings, hearing the stories behind decisions, learning which sources matter and which are outdated, they have understanding.
That transition is the entire game. Nobody is building it.
The reason is that the industry framed the problem wrong.
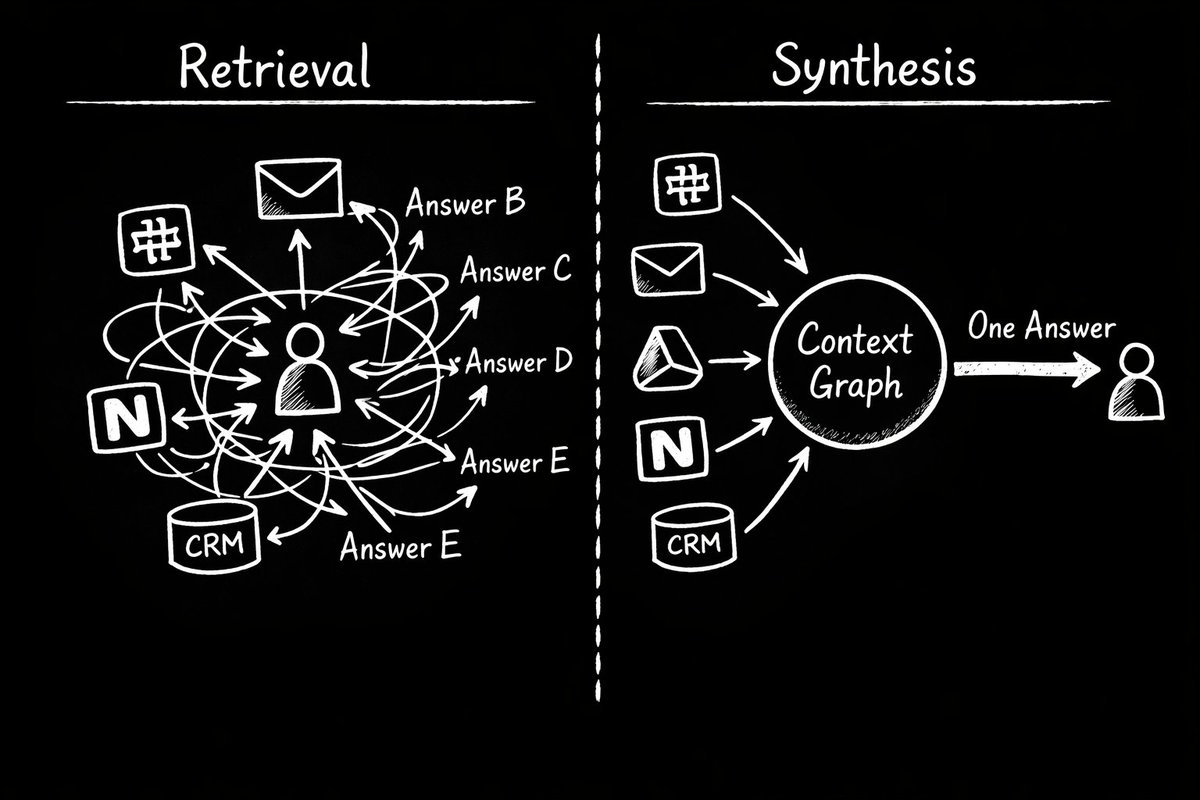
The current framing is about retrieval. How do we get the right information to the agent at the right time? RAG pipelines, vector databases, semantic search, MCP servers. All retrieval infrastructure. All variations on the same idea: when the agent needs something, go find it.
Retrieval is a scavenger hunt. Every time your agent needs context, it searches your tools from scratch. No prior understanding, no accumulated knowledge, no sense of what's changed since the last time it looked. Starting from zero, every single time.
Imagine hiring a new employee every morning, giving them full access to every system, and asking them to make decisions by lunch. They'll find things. They'll be confidently wrong about half of it. You'll spend your afternoon correcting them.
The alternative is synthesized understanding. A company brain. Instead of searching at runtime, you build a persistent model of the company that stays current as sources change. The agent doesn't search. It reads. It already knows.
Retrieval says: find the answer when someone asks the question. Synthesized understanding says: maintain a continuously updated representation of reality so the answer already exists before anyone asks.
The difference sounds subtle. In practice, it changes everything. Retrieval gives you fragments. Synthesis gives you a worldview.
Building that worldview requires solving several problems that the industry has mostly ignored.
Your company's data contradicts itself constantly. Slack says the project deadline is Friday. The Linear board says next Wednesday. The last meeting recording has the PM saying "end of month." A retrieval system returns whichever it finds first. An understanding system resolves the conflict, determines which source is most authoritative, and presents a single answer with its reasoning.
Sarah Chen appears in your data as sarah.chen@acme.com in email, @sarah in Slack, "Sarah Chen" in the CRM, "Sarah from Acme" in a meeting transcript, and "S. Chen" on a calendar invite. To a retrieval system, those are five unrelated text strings. To an understanding system, they're the same person, and everything she's said across every channel gets unified under one identity.
Information decays. The strategy doc from January is outdated. The team page hasn't been updated since the last reorg. The project status in the wiki was accurate two sprints ago. A retrieval system treats a six-month-old document with the same confidence as a message sent ten minutes ago. An understanding system tracks when information was last confirmed and knows what might be stale.
Not all sources are equal. When the CEO's email says one thing and a random Slack thread says another, the email wins. When the signed contract says one thing and the CRM field says another, the contract wins. An understanding system needs a hierarchy of source authority. A retrieval system has no concept of this.
And then there's the hardest problem: combining multiple sources into something none of them say individually. Nobody wrote a document that says "the infrastructure migration is at risk because the lead engineer is out next week, the dependency on the payments team is unresolved, and the original timeline assumed we'd have the new hire onboarded by now." That understanding only exists when you combine the project tracker, the calendar, the hiring pipeline, and last week's standup notes.
These problems are not new. Intelligence analysts and investigative journalists do this work every day. Language models make it possible to do it computationally. Not perfectly, but well enough to be useful and improving fast.
The delivery mechanism matters more than people think.
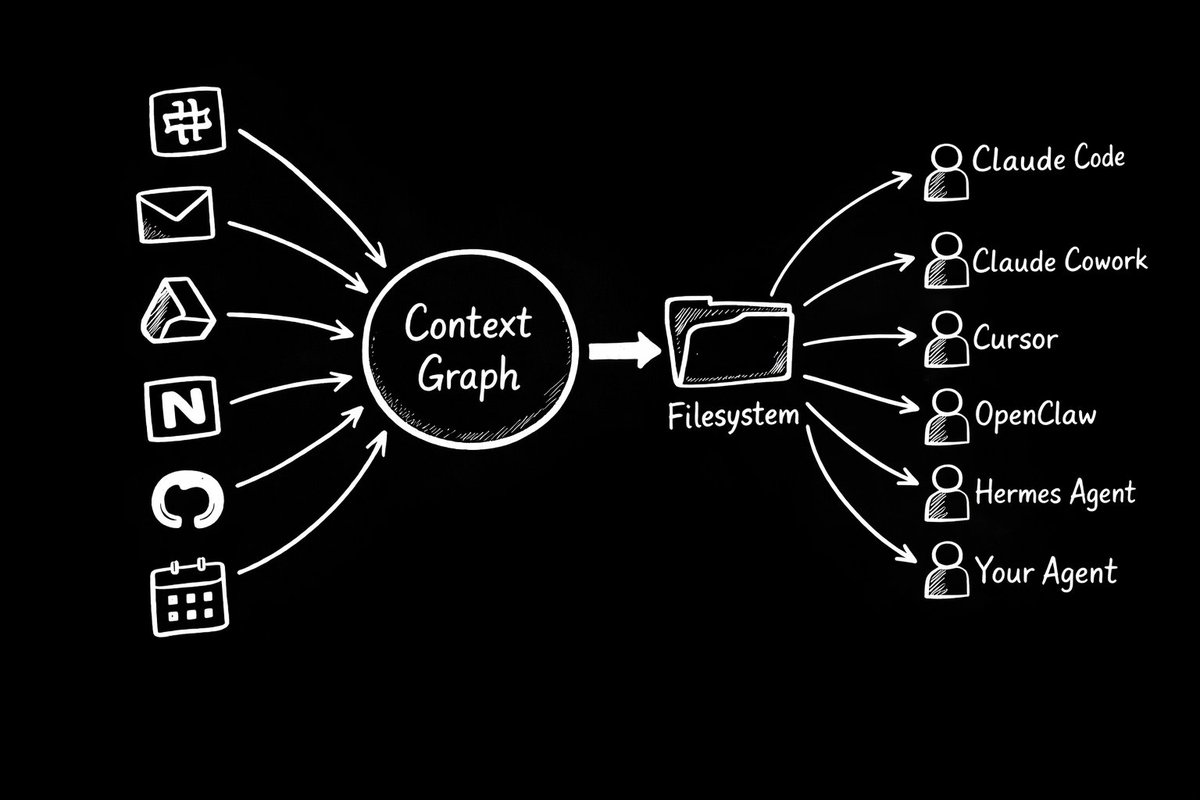
Once you've built a context graph, a synthesized, conflict-resolved, source-tracked representation of a company, how do you get it to agents?
Files.
Every agent already knows how to read files. Claude Code reads from a project directory. Cursor reads from your codebase. OpenClaw reads from its local filesystem. The filesystem is the one interface every agent already supports.
A context graph that surfaces as a filesystem means any agent, from any vendor, using any framework, can read from it without custom integration. Just files on disk, structured and current, that the agent reads when it boots up.
The filesystem is an architectural choice, not just a delivery mechanism. The context layer is decoupled from any specific agent, vendor, or workflow. Your company's understanding of itself lives in one place. Every agent reads from it. When you switch agents, add new tools, or change your stack, the context persists.
But a filesystem full of static snapshots is a diary, not a brain. What makes it a brain is what happens before the files are written. The synthesis layer takes raw, messy, contradictory signal from Slack threads and email chains and meeting transcripts and does the interpretive work that previously only happened inside a person's head. It resolves conflicts, ranks sources, tracks what's current, builds identity across fragmented mentions. That interpretation is the product. The files are just the output.
The ground truth of a company today lives in people's heads. Digital systems are the closest sensor layer we have. When the context graph does the synthesis work that used to require a person with six months of tenure, the map stops being a representation of the company. It becomes the thing that knows.
If understanding your company is the goal, there should be a way to test how well a system does it. There isn't.
We have benchmarks for code generation, mathematical reasoning, long-context recall, tool use, instruction following. No benchmark asks: given a company's real data across its real tools, can this system accurately answer basic questions about the company?
Who's on the engineering team? What are the active projects? Who owns the Acme relationship? What changed in the last week? What's the current status of the infrastructure migration? Which source is correct when Slack and the CRM disagree?
Any competent employee could answer these after a few weeks. No agent can answer them reliably today, because none of them are doing the synthesis work required.
We're building a benchmark to test this. Not a memory benchmark that tests whether a system can recall facts from conversations. A context benchmark that tests whether a system can synthesize fragmented, contradictory, multi-source company data into accurate answers.
Early results are humbling. For everyone, including us. But at least now there's a way to measure progress.
A context graph gets better every day it runs. Day one, it knows a little. Day thirty, it has absorbed thousands of messages, hundreds of documents, dozens of meetings. It has resolved conflicts, built identity maps, tracked what changed and what didn't. The understanding on day thirty is qualitatively different from day one.
Every new data point makes the existing graph more valuable. A new Slack message doesn't just add one fact. It might confirm a project status, update a relationship, reveal a priority shift, and resolve a conflict between two older sources.
You can't fast-forward this. You can't write a check and skip to month six. The understanding has to accumulate.
The cost of waiting is not "we don't have it yet." It's "we're falling further behind every day we don't start." The company that starts building today will have six months of compounded understanding that no amount of money can buy later.
That's the real moat. Not the technology, which can be replicated. The accumulated understanding of your specific company. That's proprietary. That compounds. And it only grows with time.
The industry spent 2025 giving agents access. Connectors, MCP servers, tool integrations. That work was necessary. Access turned out to be the easy part.
2026 is about understanding. Synthesizing what's in those tools into a coherent, current, trustworthy representation of reality. A representation every agent can read from. One that resolves conflicts instead of ignoring them, tracks sources instead of hallucinating them, stays current instead of going stale.
Your company needs a brain.
A continuously updated, source-grounded, conflict-resolved understanding of who you are, what you're doing, and how you work. Delivered as files any agent can read. Compounding every day.
That's what we're building at Hyperspell.
If you want to see what your company's context graph looks like, we can show you in fifteen minutes.
hyperspell.com