18 days ago we open-sourced Agent Orchestrator. 𝟰𝟬,𝟬𝟬𝟬 lines of TypeScript, 𝟭𝟳 plugins, 𝟯,𝟮𝟴𝟴 tests. a system for managing fleets of AI coding agents in parallel, built in 8 days by the agents it orchestrates. if you haven't read that post, the short version: each agent gets its own git worktree, its own terminal session, its own task. AO tracks them all, monitors CI, handles PRs, and coordinates the chaos.
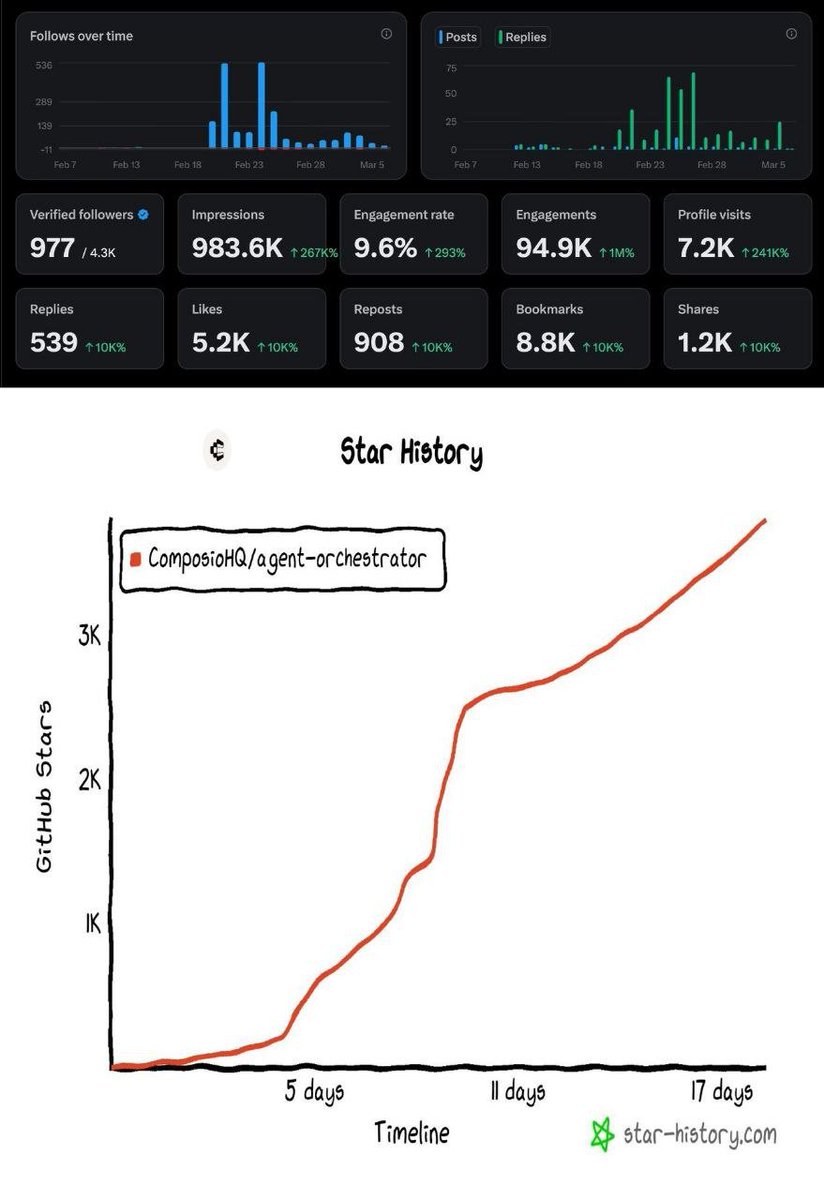
it hit 3,800+ GitHub stars in those 18 days.
18 days of AO: 983K impressions on X, 94.9K engagements, 9.6% engagement rate, and 0 to 3,800+ GitHub stars.
somewhere around day 3 after launch, i noticed something i hadn't planned for. i was using AO to develop AO. not in the "we eat our own dog food" sense. in the literal sense. i'd create a task describing a feature AO needed. AO would spin up a coding agent, give it context about the codebase, and let it work. the agent would write code, write tests, open a PR. another agent would review it. if everything passed, it'd get merged. AO would restart with the new code. the next task would run on the improved version.
step by step, the system that managed agents was being improved by the agents it managed.
one agent found a race condition not because it was looking for bugs, but because it hit the bug while working on something else. it filed an issue. another agent fixed it. after that, every subsequent session ran smoother. cleaner PRs, better reviews, higher quality improvements. small fix, cascading effects. in another session, i asked the orchestrator to analyze its own codebase and recommend improvements. it came back with genuinely insightful observations. agent specialization, pattern analysis on recurring failures, parallelizing review bottlenecks. things i hadn't noticed. three of those recommendations became tasks. agents implemented them. AO got better.
that's the clean version of the self-improvement loop. the version where everything works and each cycle produces something better than the last.
but i had a problem. AO has a full web dashboard with live terminals, kanban boards, session management. it's genuinely powerful. but the terminals don't scroll properly on mobile. the interface is technical: you're opening a browser, navigating to a URL, clicking into a terminal pane, running commands. when a session fails at 2 AM, you have to get up, open your laptop, pull up the dashboard, figure out what happened. it's not something you can casually check from your phone on Telegram. i was already spending most of my day talking to a different system entirely.
why connect OpenClaw to orchestrator
every AI system has an unsolved last-mile problem: the human interface.
tools keep building their own dashboards, their own CLIs, their own web apps. each one requires a context switch. open a browser. navigate to a URL. learn the UI. remember the commands. AO is no exception. it has a great dashboard with kanban views, live terminals, session management, PR tracking. it has its own orchestrator agent that spawns sessions, assigns tasks, monitors CI. AO is a complete system. it handles orchestration on its own.
but it still lives behind a URL. and i'm not always at my laptop.
OpenClaw inverts this. 278K GitHub stars. but here's the thing: there are plenty of AI chatbots integrated into WhatsApp and Telegram. you can talk to ChatGPT in a messaging app right now. that's not what makes OpenClaw different.
OpenClaw won because it treated the problem as infrastructure, not as a chat feature.
a chatbot is stateless request-response. you type, it replies, the context evaporates. OpenClaw is an always-running process on your own machine with persistent sessions, memory files, tool access, file system access, sandboxed code execution. the Gateway is the single authority over sessions, routing, tool invocation, and state. it's not "AI in Telegram." it's an operating system for AI agents that happens to be accessible through Telegram.
the engineering differences matter. OpenClaw executes, it doesn't just generate text. it runs shell commands, reads files, makes API calls, deploys code. the LLM becomes the operator, not the responder. it's event-driven, not just request-driven: it reacts to crons, webhooks, email arrivals, heartbeats. it notices things and acts without being asked. it supports multi-agent routing: one gateway, multiple agents with different workspaces and skills. and everything runs local-first on your hardware, with full system access. a Telegram chatbot running on someone else's cloud can't SSH into your server or read your codex auth file.
i've been running it for months. it manages my finances, tracks contacts, writes journal entries, monitors my email, deploys code, runs scripts. it's the single interface through which i interact with everything in my digital life.
for agent orchestration specifically, four things matter:
ambient availability. AO's dashboard requires intentional access. OpenClaw is in Telegram, which is already open. when a session fails at 2 AM, i don't need to find my laptop.
natural language as the universal API. AO's CLI has ao spawn, ao send, flags, arguments. OpenClaw translates "fix the terminal bug" into the right sequence of commands.
persistent context across sessions. OpenClaw carries memory between conversations. it knows what ao-12 was working on yesterday, what failed last night, what the priorities are this week. AO's dashboard shows current state. OpenClaw knows history and intent.
multi-system reach. OpenClaw doesn't just talk to AO. it manages my server, my blog, my email, my finances. when i say "deploy the blog post and then create the social media drafts," that crosses AO, Caddy, the blog renderer, the static file server, and the writing voice system. no single tool's dashboard spans all of that.
so the connection was natural. but here's the key architectural decision: i'm not building OpenClaw as a notification layer that talks to AO's orchestrator. i'm building a connector that lets OpenClaw take over the orchestrator role directly.
AO has always been designed for human-in-the-loop operation. the standalone orchestrator agent (a codex or claude-code session) was always a stand-in for the human, making decisions the human would make if they were watching. with the OpenClaw connector, the actual human IS watching, through OpenClaw. the stand-in becomes unnecessary.
OpenClaw with the connector uses AO's infrastructure directly: worktrees, tmux sessions, CI monitoring, session management, the dashboard. but the orchestration decisions, what to build, when to kill a stuck session, how to decompose a problem, come from OpenClaw itself, with the human right there on Telegram to weigh in. no redundant LLM layer translating intent twice. the orchestrator has human context, persistent memory, multi-system reach. escalation is instant because the human is already in the conversation.
the standalone AO orchestrator still works exactly as before, it's also human-in-the-loop, not autonomous. the difference is which agent handles the orchestration responsibilities. without the connector, a dedicated codex or claude-code session acts as orchestrator. with the connector, OpenClaw takes over that role through a plugin, bringing its persistent memory, multi-system reach, and the fact that the human is already in the conversation.
and then the recursive idea: have OpenClaw use Agent Orchestrator to build the OpenClaw-AO connector, then point Agent Orchestrator back at its own codebase in the same run. the human interface building a better version of itself.
what actually shipped in the connector
ao-12's writeup made one thing obvious: speed came from refusing to over-design transport.
i considered deeper peer-protocol ideas first. interesting, but slow. the move that shipped was simple: build a notifier plugin and route into OpenClaw's existing hook ingress.
• AO notifier plugin: @composio/ao-plugin-notifier-openclaw
• OpenClaw ingress: POST /hooks/agent
• local transport: 127.0.0.1 + token auth
• session mapping: hook:ao:
• delivery hardening: exponential backoff on 429/5xx
the highest leverage testing move was external operator validation, not just local green tests. separate OpenClaw instance, fresh checkout, build from source, hook config, token rotation, burst traffic, and live channel rendering.
• passed: ingress, session isolation, token rotation, burst handling, and clean deliver: true rendering
• gaps: no idempotent dedupe, same-session ordering can drift by completion timing, reverse command path still needs full runtime smoke validation
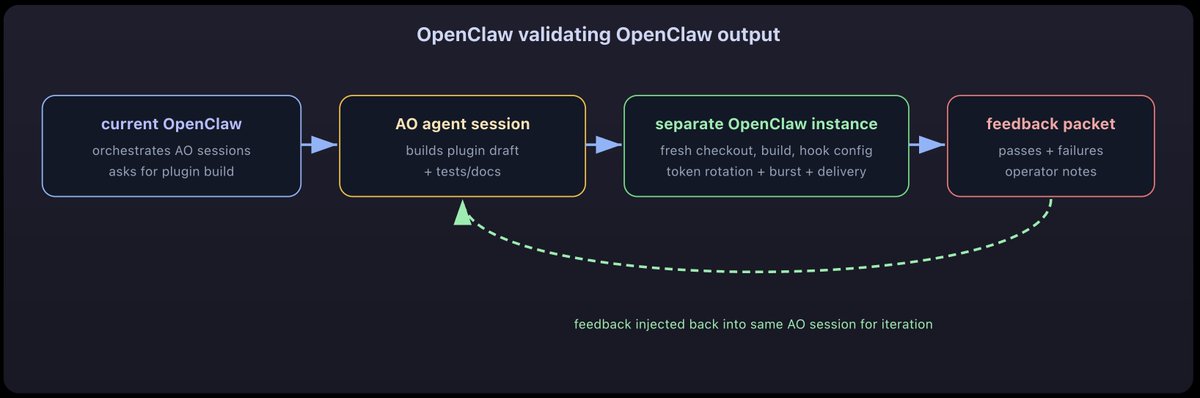
the mind-bending feedback loop that made this actually work
the loop we actually ran: OpenClaw used AO to build the plugin, another OpenClaw tested it like a customer, feedback went back into the same agent session.
15 parallel sessions. one overnight run. here's what actually happened.
15 sessions, one night
i want to be clear about what "self-improving" means here, because it's easy to overstate. the agents write code autonomously. they run tests, iterate on CI failures, push commits. that part is genuinely hands-off. but the orchestration layer, deciding what to build, which sessions to spawn, what context to inject, when to kill a stuck session and start over, that was me. i was on Telegram the whole night, directing OpenClaw, which was directing AO, which was directing the agents. three layers of intelligence, but the strategic decisions were still human.
the overnight run wasn't "set it and forget it." it was more like managing a team of very fast junior engineers over chat at 2 AM.
here's what the night actually looked like.
https://x.com/agent_wrapper/status/2025986105485733945?s=20
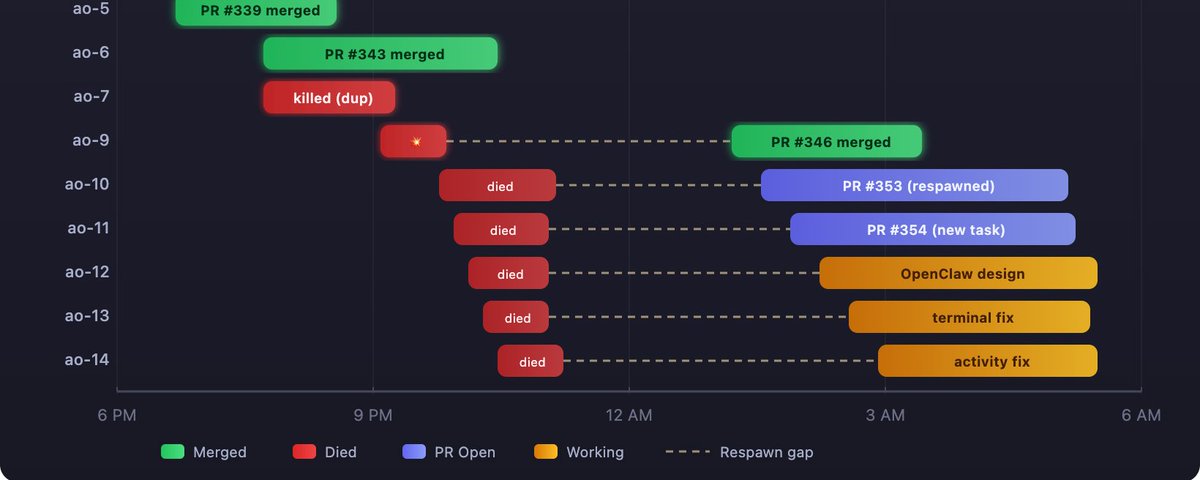
every session that ran last night. green merged, red died, purple has an open PR, amber still working. the dashed lines are the gaps where sessions were dead before being respawned.
the first wave: things work
sessions ao-3 through ao-6 were clean. i'd notice a bug while using AO, describe it to OpenClaw on Telegram, and tell it to spawn a session. OpenClaw would run ao spawn, then ao send to inject the task description. each session got its own git worktree branched off main, a codex instance running inside tmux, and the task i'd described.
ao-3 fixed codex suppressing update prompts. PR #338, merged. ao-4 fixed a permissions flag that was being ignored. PR #337, merged. ao-5 bumped the version to 0.1.1. PR #339, merged. ao-6 fixed PATH ordering so the gh CLI wrapper would resolve correctly. PR #343, merged.
four sessions, four PRs, four merges. clean. textbook self-improvement loop. the system was building itself and each merge made the next session slightly smoother.
ao-7 was the first sign of trouble. it was working on the same issue as ao-6 but took a different approach. two agents, same bug, two PRs. i killed ao-7 and merged ao-6's PR. not a disaster, but a coordination failure. the orchestrator should have detected the duplicate. it didn't, because duplicate detection wasn't built yet.
so i made a mental note: build duplicate detection. that note became a task. that task would eventually become another agent session. the system was already surfacing its own gaps.
the crash
then came ao-9. this is where the night got interesting.
ao-9 was supposed to fix WebSocket URL routing for the terminal component. a 15-line change. simple enough that i didn't even bother spawning an agent for it. i just made the edit myself, committed, pushed, and opened PR #346.
this was a mistake. not because the code was wrong. the code was fine. the mistake was that ao-9 existed in AO's session list but had no tmux session behind it. every other session had a live codex process running in tmux. ao-9 had nothing. when you opened ao-9 on the dashboard, the terminal component tried to connect to a tmux pane that didn't exist. it flickered endlessly. reconnect, fail, reconnect, fail.
i tried to fix this by spawning a real agent into ao-9's slot. but the worktree was already checked out on a different branch. so i killed ao-9, created ao-8 to take over, realized that was worse because now i had two sessions for one PR, killed ao-8, recreated the worktree for ao-9, and tried to start codex manually.
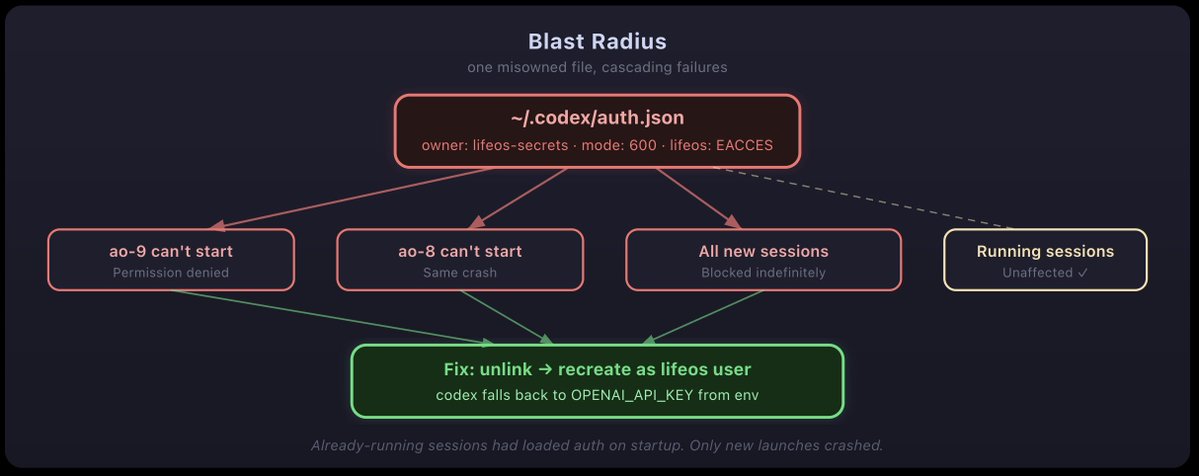
codex crashed immediately.
one line. no stack trace. no explanation. just "permission denied."
i ran strace to figure out what file it was trying to read.
the auth.json file was owned by lifeos-secrets:lifeos-secrets with 600 permissions. the codex process was running as lifeos. it couldn't read its own authentication file.
how did this happen? earlier that day, i'd been hardening the gh CLI to prevent the AI from accessing unauthorized GitHub repos. part of that work involved moving credentials to a separate system user called lifeos-secrets. the auth.json file got caught in that sweep. a security improvement in one part of the system had silently broken a completely different part.
https://github.com/openclaw/openclaw
the fix was simple once i found it. delete the file (the directory was owned by lifeos, so unlinking worked even though the file wasn't), create a fresh empty one, and let codex fall back to the OPENAI_API_KEY environment variable. but finding the cause took 20 minutes of strace and confusion.
this is the kind of failure that doesn't show up in theory papers about self-improving systems. a security improvement in one subsystem silently breaks an authentication path in another. no test caught it because the tests don't run as a different user. the blast radius was invisible until someone tried to start a new session.
the mass death
while i was debugging the auth crash, i had a bigger problem. sessions ao-10 through ao-14 were all dead.
these five sessions had been spawned using the wrong method. OpenClaw used its exec tool (a background shell process) instead of ao spawn. i didn't catch the mistake until they were all dead. the difference matters. ao spawn creates a detached tmux session that lives independently. exec creates a child process of OpenClaw's shell session. when that shell session times out after 600 seconds, the child process gets SIGTERM'd. the codex process dies.
five sessions, five tasks, all gone. no work saved. no partial progress. the worktrees existed but had zero commits beyond the base branch. this was an operator error. i should have told OpenClaw to use ao spawn from the start. i didn't, and i lost hours of agent work.
i told OpenClaw to respawn them through ao spawn this time, but AO reuses session IDs sequentially. so when i spawned replacements, they got IDs ao-10 through ao-14, but with different tasks than the originals. ao-11 was originally "fix mobile terminal scrolling." the respawned ao-11 got "CI auto-injection with retry escalation." total confusion about which session was doing what.
this is a session identity problem. the sessions are identified by sequential numbers, not by their task or purpose. when ao-11 dies and gets respawned, it should still be "the mobile terminal scroll session." instead, it became a completely different session that happened to have the same number.
the recursion gets deeper
here's where it gets properly weird.
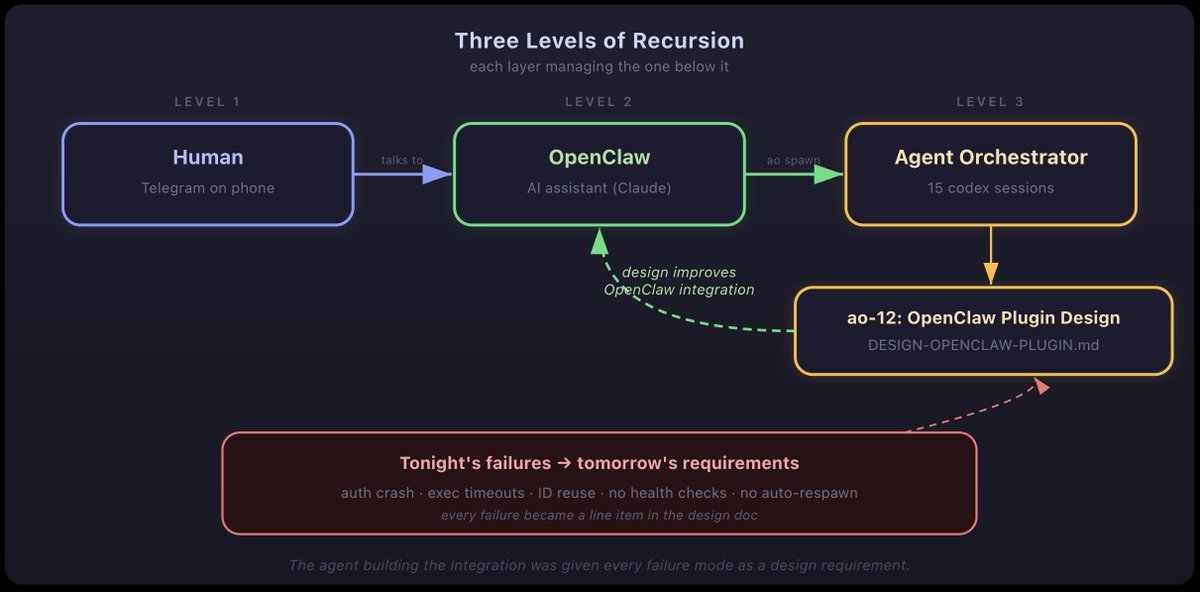
one of the respawned sessions, ao-12, got a task that i've been thinking about for a while: design the integration between OpenClaw and AO. the system that manages my life (OpenClaw) using the system that manages coding agents (AO) to build the bridge between them.
let me say that again because it's important. i'm talking to an AI assistant on Telegram. the assistant is using an agent orchestrator to spawn coding agents. one of those agents is designing how the assistant should integrate with the orchestrator. the agent is writing a design document for the system that will eventually replace the manual process by which it was created.
three levels of recursion:
• human talks to OpenClaw
• OpenClaw uses AO to spawn agents
• agent designs the OpenClaw-AO integration
and here's what made it interesting. i'd been hitting failures all night, getting frustrated, fixing things manually. at some point i told OpenClaw: "give ao-12 all the context about what went wrong tonight so it can design around these problems." OpenClaw packaged up every failure i'd hit, sessions dying silently, messages not submitting, IDs getting reused, no health monitoring, no auto-respawn, and injected it into the agent as design requirements.
the agent didn't discover these requirements. i did, by operating the system badly and noticing what broke. then i fed those observations into an agent that could turn them into a design. the insight was human. the execution was automated.
the meta-structure: i talk to OpenClaw, which uses AO to spawn agents, one of which is designing how OpenClaw should integrate with AO. tonight's failures become the requirements for that design.
this is the self-improvement loop, but it's not the clean version i described in the first blog. it's messy. the improvements come from crashes and confusion, not from elegant meta-analysis sessions. the system learns from breaking.
three tiers of "fix it yourself"
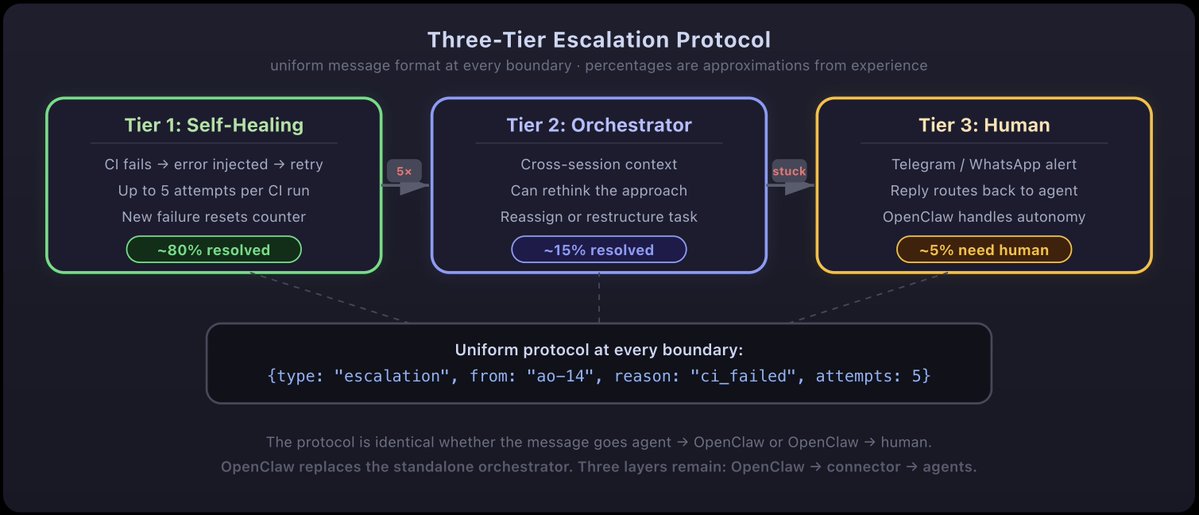
the failures from that night crystalized into an architecture. i call it the three-tier escalation protocol.
tier 1: agent self-healing. when CI fails on a PR, the failure output gets automatically injected back into the agent session. the agent reads the error, fixes the code, pushes again. up to 5 times before giving up. no human involved. session ao-11 built this and filed PR #354. this is the only tier that's actually implemented right now.
tier 2: orchestrator mediation. if the agent can't fix it after 5 tries, escalate to the orchestrator session. the orchestrator is itself a codex instance with context about all active sessions. it can look at the failing agent's code, understand the broader picture, and either suggest a fix or rethink the approach. this tier is designed but not built yet.
tier 3: human escalation via OpenClaw. if the orchestrator can't handle it, send a message to my Telegram. something like: "ao-14 failed CI 5 times on the activity state fix. error is a type mismatch in the codex plugin." i reply in chat and the response gets routed back to the agent. this is what ao-12 is designing right now. also not built yet.
the escalation architecture. same message format at every boundary. OpenClaw replaces the standalone orchestrator entirely. three layers remain: OpenClaw, the connector plugin, and the individual coding agents.
the key design decision: the protocol is uniform. the message format is identical whether it goes from agent to OpenClaw or from OpenClaw to me. OpenClaw replaces the standalone orchestrator entirely. three layers remain: OpenClaw at the top (with the human right there in the conversation), the connector plugin that bridges to AO's infrastructure, and the individual coding agents. OpenClaw isn't a notification sidebar. it's a peer in the escalation protocol, capable of both autonomous resolution and human handoff.
the scoreboard
by 6 AM, the overnight session had produced:
• 6 merged PRs (#337, #338, #339, #343, #346, and one from before)
• 2 open PRs (#353 for dashboard enrichment, #354 for CI auto-injection)
• 4 sessions actively working (OpenClaw integration design, terminal fixes, activity state fix, navbar fix)
• 6 sessions that died and were respawned
• 1 authentication crash that blocked all new sessions for 20 minutes
• 1 duplicate work incident (ao-6 and ao-7 on the same bug)
• 0 regressions introduced to the main branch
the system that ran at 6 AM was meaningfully better than the one at 6 PM. not because of any single change, but because of all of them together. the codex plugin handled permissions correctly. PATH resolution worked. the version was bumped. the terminal WebSocket connected through the reverse proxy. the dashboard showed live PR data.
and three sessions were still running. whether they'd produce something useful or crash silently, i wouldn't know until i checked in the morning.
what self-improvement actually looks like
the first blog walked through the loop in detail. the 8 steps, the file-locking example, session ao-52's self-analysis. real code, real sessions, real improvements. all of that was true and still is.
but running the loop at scale, overnight, with 15 sessions in parallel? that's a different animal.
sessions die because i told OpenClaw to use the wrong spawn method. a security change i made breaks authentication for a different tool. messages get pasted into codex's input buffer but the Enter key never fires, and i have to notice the agent is stuck and manually press Enter on the server. session IDs get reused and i lose track of which agent is doing what.
the self-improvement still happens. but it's not automatic. i notice the failure. i understand what went wrong. i tell OpenClaw to feed that failure back as a requirement. the auth crash? i told ao-12 to include "crash forensics" in the design. the exec timeout? i told it to add "session health monitoring." the ID reuse? "session identity tied to task, not sequential numbers."
the system improves by being bad in informative ways. but the "informative" part requires a human paying attention at 2 AM.
what changes at scale
in the first blog, i described three phases: agents as tools, agents as workers, agents as self-improving systems. i walked through concrete examples of each. i said Phase 3 was "qualitatively different."
i was right, but the qualitative difference isn't what i expected. it's not that the system gets better faster. it's that the system generates its own improvement backlog.
when you use agents as workers (Phase 2), you tell them what to build. you maintain the backlog. you prioritize. you decide what matters. the agents are skilled labor, but the direction is entirely human.
in Phase 3, the system produces failures that reveal requirements that generate tasks that agents implement. i didn't plan to build session health monitoring. five sessions died silently at 2 AM and the need became obvious. but let me be honest: the requirement didn't "write itself." i noticed the problem, understood it, and turned it into a task. the system surfaced the failure. i did the interpretation. the agents did the implementation.
maybe that's still Phase 2.5. the fully autonomous version, where the system detects its own failures and spawns agents to fix them without a human noticing at 2 AM, is what the escalation protocol is designed to enable. i'm not there yet. but the infrastructure is being built by the same agents that need it, which is at least poetic.
the part that scares me
i'll be honest about something. at 3 AM, when i was watching ao-12 write a design document for the system that would eventually supervise all the other agents, including future versions of itself, i had a moment where i thought: i'm not sure i fully understand what i'm building.
not in a Terminator way. in an engineering complexity way. the system has three layers of AI (OpenClaw, AO orchestrator, individual agents), each with different models and contexts and failure modes. the interactions between these layers produce emergent behaviors i didn't predict. the auth crash was an emergent behavior. the exec timeout was an emergent behavior. the message delivery failure was an emergent behavior.
as these layers get more tightly integrated, the space of possible emergent behaviors grows combinatorially. i can test individual components. i can test pairwise interactions. but testing the full system requires running the full system, and the full system is the production environment.
this is why i'm building the escalation protocol. not because i think the system will go rogue. because i think the system will fail in ways i can't predict, and i need a reliable path from "something broke" to "a human knows about it" that doesn't itself break in novel ways.
the safety mechanism for a self-improving system isn't preventing change. it's ensuring visibility. if i can see every modification the system makes to itself, i can catch problems before they compound. if i lose visibility, i lose control. and in a system this complex, losing visibility is easier than it sounds.
this post is part of the loop
i should mention how this blog post was written. i told OpenClaw on Telegram: "write a blog about how i built the OpenClaw-AO integration by asking OpenClaw to build it using Orchestrator." it read the first blog for style reference, wrote a draft, saved it to the server, and sent me a link. i read it. it was wrong in places. it overstated how autonomous the system was. i told it to fix that. it fixed it. i told it the diagrams needed to be better. it redid them. i told it to include the star history image. it added it, broke the YAML config in the process, fixed that too, and sent me a new link.
this paragraph you're reading right now was written after i told OpenClaw: "the article makes it look like the system was a lot more autonomous than it actually was. be realistic." the AI wrote a more honest version. i'm reviewing it on the same server that hosts the AO dashboard that monitors the agents that are building the features i'm writing about.
it's recursive, yes. but at every level, a human is reading, judging, and redirecting. the automation handles the typing. the human handles the thinking.
the loop continues
it's Sunday morning now. the sessions are still running. ao-12 is writing the OpenClaw integration design. ao-13 is fixing the mobile terminal. ao-14 is patching the activity state bug. ao-15 is fixing the navbar links.
by the time i finish writing this post, some of those PRs will be merged. the system will be better. new bugs will have appeared. new sessions will be spawned to fix them.
the loop doesn't stop. it doesn't have a clean endpoint. there's no version 2.0 release where everything works perfectly. there's just continuous, incremental, chaotic improvement. the coding is automated. the direction is still me, on Telegram, at 3 AM, telling an AI assistant what to fix next.
i wrote in the first blog that the companies who figure out self-improving agentic systems first will have an absurd advantage. i walked through why: compound interest applied to engineering capability. i still believe every word.
but i'd add something i didn't appreciate before: the advantage isn't in having a clean self-improvement loop. it's in having a messy one that you can observe, debug, and steer.
the system that keeps building itself doesn't need to be perfect. it needs to be transparent.
Agent Orchestrator is open source at github.com/ComposioHQ/agent-orchestrator. the dashboard, session management, and escalation protocol are all in the repo. i work on AI agents at Composio. if you're building orchestration systems or thinking about self-improvement loops, find me on Twitter or GitHub.








Link: http://x.com/i/article/2031050661866221568