你爱 Claude,你的钱包却不爱。下面教你如何用更低成本,继续拿到前沿级质量的答案。
问题:Claude 很强,但很贵
如果你在用 Anthropic API 做产品,你肯定已经知道:Claude 是目前最强的推理模型之一。
-
Opus 4.6:每百万 token $5/$25。
-
Sonnet:每百万 token $3/$15。
-
就连 Haiku 也要:每百万 token $1/$5。
但有件事,大多数开发者不太愿意承认:你绝大多数的 API 调用其实并不需要 Claude。
想想你日常的工作负载。你在做一个 SaaS 应用。有些请求确实需要 Claude 的推理能力——调试复杂代码、分析长文档、编排多步骤的智能体工作流。但更多请求其实很“日常”:从文本里抽取 JSON、回答简单用户问题、翻译一段字符串、总结一段话。
你在为每百万 token $3–$25 的价位买单,而这些活儿用一个 $0.10 的模型做出来几乎一模一样。
问题很简单:你把 Claude 的价格用在了 100% 的请求上,但真正需要 Claude 的可能只有大约 30%。
典型开发者的工作负载是什么样的?
https://github.com/blockrunai/ClawRouter
日常任务(约 70% 的请求)
这些请求你会不停地发,甚至都不怎么需要动脑:
-
“从这段文字里抽取姓名和邮箱并返回 JSON” —— 任何模型都能做。你却在为结构化抽取付 Claude 的 $15/M 输出 token,而一个 $0.40 的模型也能做得完全没问题。
-
“把这条客服工单用两句话总结” —— 总结早就是成熟题了,这里不需要前沿级推理。
-
“把这条报错信息翻译成西班牙语” —— 翻译是典型的商品化任务。用 Claude 的价格做翻译,就像开着兰博基尼去买菜。
-
“useEffect 和 useLayoutEffect 有什么区别?” —— 事实性问答。基本所有模型都能答对。
-
“把这份 CSV 数据转换成 markdown 表格” —— 纯格式转换。免费模型也能做到一模一样。
真正需要 Claude 的任务(约 30% 的请求)
这里你付的钱才是在买真正的价值:
-
复杂代码生成 —— “把这个认证模块重构为支持 OAuth2 + PKCE,处理 token refresh,并加上限流。”这是多文件、多约束的推理工作,Claude 在这里确实值回票价。
-
长文档分析 —— “读完这份 50 页的合同,找出所有可能让我们承担超过 $1M 责任的条款。”上下文窗口与推理质量在这里至关重要。
-
多步骤智能体编排 —— “扫描这 5 个 API,交叉核对数据,并生成带建议的报告。”这类智能体工作流要求模型在许多步骤中持续维护计划。
-
高级推理 —— “调试我们分布式系统里的竞态条件”或“证明这个算法是 O(n log n)。”便宜模型在这种任务里很容易跟丢线索。
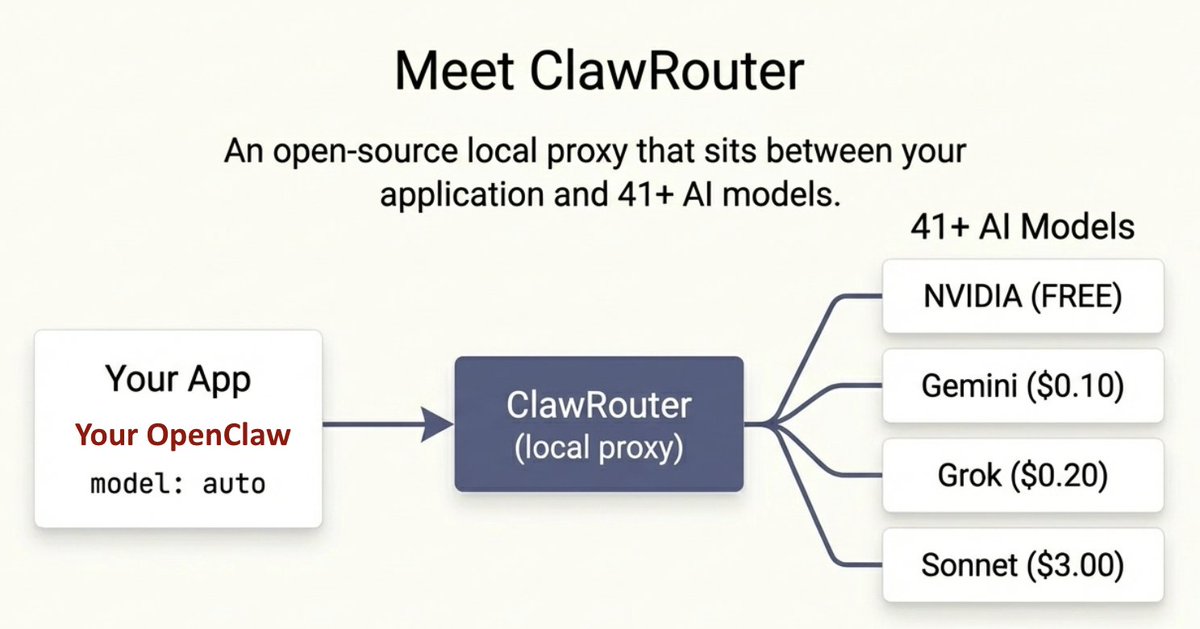
解决方案:ClawRouter
ClawRouter 是一个开源的本地代理,位于你的应用与 41+ 个 AI 模型之间。它通过三种方式帮你省钱:智能路由、token 优化、以及响应缓存。上线 1 个月在 Github 拿到 5K stars。https://github.com/BlockRunAI/clawrouter
你如何省钱:三层机制
第一层:智能路由(收益最大)
ClawRouter 会在 <1ms 内从 14 个维度为每条提示词打分,并把它路由到能胜任任务的最便宜模型。
结果:77% 的请求会被分配到比 Sonnet 便宜 5–150 倍的模型上。只有真正需要 Claude 的那约 23% 才仍然交给 Claude。
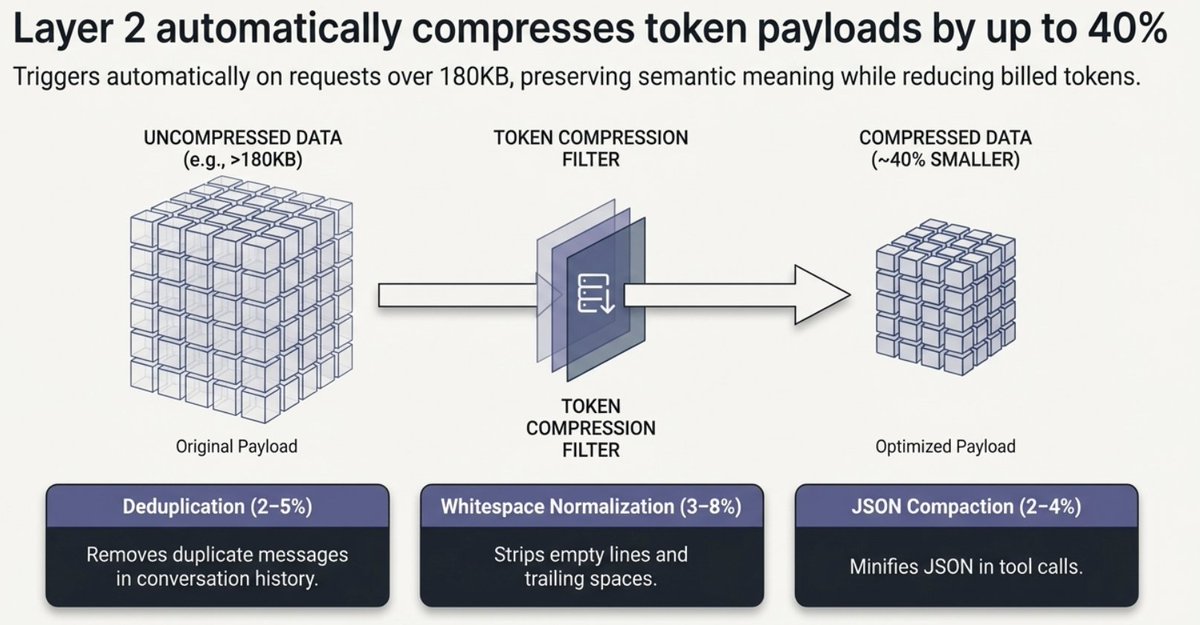
第二层:Token 压缩(每次请求都省)
即便请求确实需要发给 Claude,ClawRouter 也会减少你需要付费的 token 数。代理会在把请求发给提供方之前,对你的请求运行多层压缩流水线——而你的计费以压缩后的 token 数为准,而不是原始 token 数。
这三层机制都默认开启,并且完全安全——不会改变语义含义。压缩会在请求大于 180KB 时自动触发(在智能体工作流和长对话里非常常见)。
对于智能体占比高的负载(长工具输出、多轮对话),节省会更大。一个可选的观测压缩层最多可以把巨大的工具输出压缩 97%——把 10KB 的冗长日志输出变成 300 个字符的关键信息。
典型叠加节省:每次请求少 7–15% 的 token。在长上下文的智能体负载中:20–40%。
这在昂贵模型上最关键。如果你把一段 50K token 的智能体对话发给 Claude Sonnet,15% 的压缩每次请求能省大约 ~$0.03——规模化之后就是实打实的钱。
第三层:响应缓存 + 请求去重(省 100%)
ClawRouter 会在本地缓存响应。如果你的应用在 10 分钟内发送了同样的请求,你会立即拿到响应,并且零成本——不发 API 调用,也不会计费 token。
这种情况比你想象得更常见:
-
重试逻辑 —— 应用超时会重试。没有去重就会付两次钱;有了 ClawRouter,重试会直接从缓存命中并立刻返回。
-
冗余请求 —— 多个用户或进程问同一个问题?一次 API 调用,多次复用响应。
-
智能体循环 —— 智能体框架经常带着相同上下文重复查询。缓存可以抓住这些。
Request 1: "Summarize this document" → API call → $0.02 → cached
Request 2: "Summarize this document" → cache hit → $0.00 → instant
Request 3: "Summarize this document" → cache hit → $0.00 → instant
去重器还会捕捉“飞行中”的重复请求:如果两条完全相同的请求同时到达,只有一条会发给提供方。两位调用方都会拿到同一份响应。
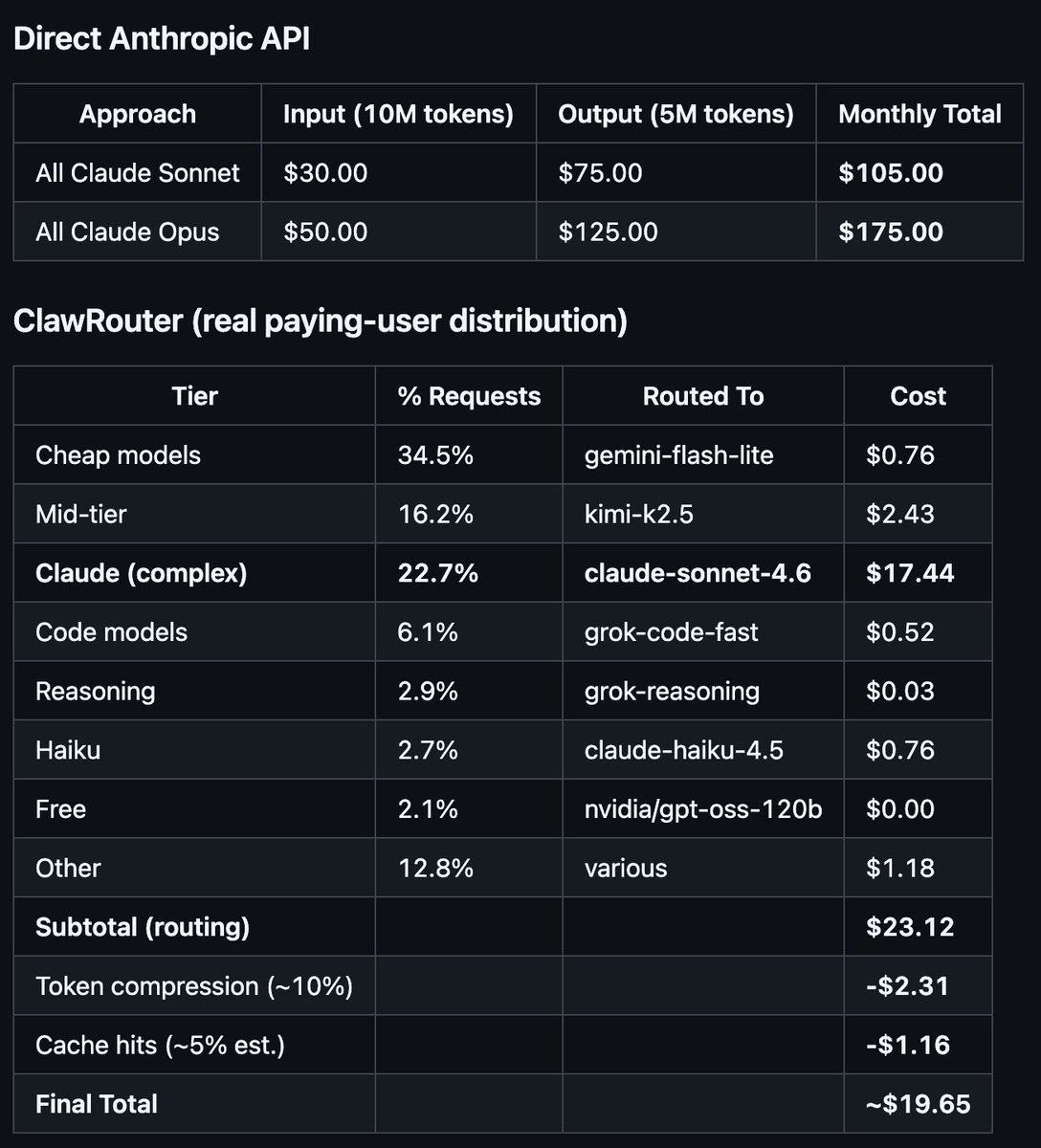
成本测算(诚实数字)
每月 10,000 个混合请求,平均每个请求 1,000 input tokens 和 500 output tokens。
https://github.com/blockrunai/ClawRouter
快速开始:3 分钟
1. 安装并启用智能路由
curl -fsSL https://blockrun.ai/ClawRouter-update | bash
openclaw gateway restart
2. 在 Base 或 Solana 上用 USDC 给你的钱包充值(安装时会打印地址)
$5 足够支撑成千上万次请求
链接:
-
GitHub 上的 ClawRouter — MIT 许可证
-
BlockRun — AI 模型市场
成本数据来自真实生产环境中付费用户的流量,覆盖 20,000+ 次请求,时间为 2026 年 3 月。节省幅度因负载而异——智能体更重、上下文更长的负载会获得更大的压缩收益。ClawRouter 是开源项目,也是 BlockRun 生态的一部分。







Link: http://x.com/i/article/2030130545158402048