Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter
Ruoyu Qin1,2 Weiran He1 Yaoyu Wang1 Zheming Li1 Xinran Xu1
Yongwei Wu2 Weimin Zheng2 Mingxing Zhang2
1Moonshot AI 2Tsinghua University Corresponding author: zhang_mingxing@mail.tsinghua.edu.cn
Abstract
Prefill-decode (PD) disaggregation has become the standard architecture for large-scale LLM serving, but in practice its deployment boundary is still determined by KVCache transfer. In conventional dense-attention models, prefill generates huge KVCache traffics that keep prefill and decode tightly coupled within a single high-bandwidth network domain, limiting heterogeneous deployment and resource elasticity. Recent hybrid-attention architectures substantially reduce KVCache size, making cross-cluster KVCache transport increasingly plausible. However, smaller KVCache alone does not make heterogeneous cross-datacenter PD serving practical: real workloads remain bursty, request lengths are highly skewed, prefix caches are unevenly distributed, and inter-cluster bandwidth fluctuates. A naive design that fully externalizes prefill can therefore still suffer from congestion, unstable queueing, and poor utilization.
We present Prefill-as-a-Service (PrfaaS), a cross-datacenter serving architecture that selectively offloads long-context prefill to standalone, compute-dense prefill clusters and transfers the resulting KVCache over commodity Ethernet to local PD clusters for decode. Rather than treating reduced KVCache as sufficient, PrfaaS combines model-side KV efficiency with system-side selective offloading, bandwidth-aware scheduling, and cache-aware request placement. This design removes the requirement that heterogeneous accelerators share the same low-latency RDMA fabric, enabling independent scaling of prefill and decode capacity across loosely coupled clusters. In a case study using an internal 1T-parameter hybrid model, a PrfaaS-augmented heterogeneous deployment achieves 54% and 32% higher serving throughput than homogeneous PD and naive heterogeneous baselines, respectively, while consuming only modest cross-datacenter bandwidth.
1 Introduction
Prefill-decode (PD) disaggregation has become the dominant deployment paradigm for large-scale LLM serving because it separates two fundamentally different phases of inference: prefill is primarily compute-intensive, whereas decode is primarily memory-bandwidth-intensive. At Moonshot AI, Mooncake [22] helped push this shift into practice by treating KVCache as a first-class systems resource, a direction that has since propagated across the broader serving ecosystem via our collaboration with open frameworks such as vLLM [29], SGLang [7], and Dynamo [20]. In principle, PD disaggregation should also unlock a more ambitious goal: heterogeneous serving, in which prefill runs on compute-dense accelerators and decode runs on bandwidth-optimized accelerators. Hardware roadmaps are already moving in this direction. NVIDIA’s Rubin CPX [19] explicitly targets high-throughput long-context prefill, while architectures such as Groq’s Language Processing Unit (LPU) [1, 8] emphasize the extreme memory bandwidth required for decode.
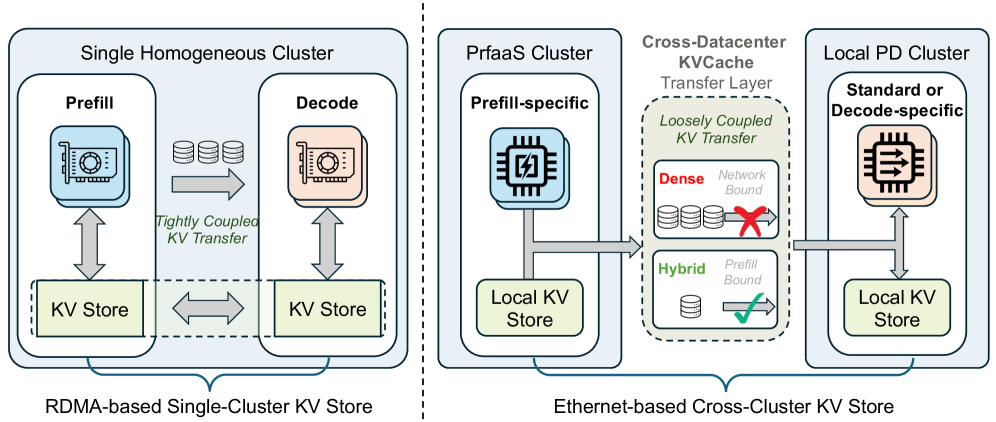
In practice, however, this heterogeneous vision remains difficult to realize because current PD disaggregation still relies on a strong networking assumption: when prefill and decode are placed on different nodes, the KVCache produced by prefill must be transferred quickly enough to avoid stalling computation. In conventional deployments, this effectively confines both phases to the same tightly coupled, high-bandwidth network domain, typically a single datacenter-scale RDMA fabric, where PD disaggregation works well inside a homogeneous cluster. The difficulty is that this single-datacenter paradigm does not extend naturally to heterogeneous serving. Accelerator resources are usually pooled by both chip type and physical location, so compute-oriented and inference-oriented hardware are often unavailable within the same tightly coupled domain. This creates a strong incentive to separate prefill from decode across cluster boundaries, which can reduce costs and latency for long-context requests by moving prefill to faster compute hardware. However, this advantage materializes only if KVCache transfer remains sufficiently cheap. Once prefill and decode no longer share the same high-bandwidth fabric, the generated KVCache must traverse a slower inter-cluster link. If that transfer cost is too high, it erases the prefill-side gain and becomes the new bottleneck. Even when two clusters are geographically close, requiring them to share a single RDMA-scale fabric is operationally rigid and often unrealistic. Worse, once heterogeneous deployment is forced into one tightly coupled cluster, its prefill-to-decode hardware ratio becomes difficult to adapt as traffic patterns evolve. As a result, current PD deployments still fall short of the flexibility that heterogeneous disaggregation is supposed to provide.
The central obstacle, therefore, is KVCache transfer. Recent hybrid-attention architectures change this picture in an important way. Emerging models [26, 27, 31, 3, 11, 2, 18] interleave a small number of full-attention layers with a larger number of linear-complexity or bounded-state layers, such as Kimi Delta Attention (KDA) [26], Sliding Window Attention (SWA) [5], and related mechanisms. This design substantially reduces KVCache growth relative to dense-attention architectures, often by an order of magnitude, thereby making cross-datacenter KVCache transfer plausible. But plausibility is not yet practicality: a naive design that externalizes all prefills would still suffer from bursty arrivals, skewed request lengths, uneven prefix-cache distribution, and fluctuating inter-cluster bandwidth. Hybrid architectures relax the KVCache bottleneck, but they do not eliminate the need for system design; rather, they create the opportunity that system design must exploit.
(a) Status quo: Tightly coupled single-cluster inference.
(b) PrfaaS: Multi-cluster disaggregated inference via cross-datacenter KVCache.
Figure 1: Comparison of two deployment paradigms for PD-disaggregated LLM serving.
This observation leads to the key design principle of this paper: Prefill-as-a-Service (PrfaaS) via cross-datacenter KVCache. As illustrated in Figure 1, instead of forcing heterogeneous accelerators into a single RDMA island, PrfaaS constructs standalone clusters dedicated to long-context prefill using inexpensive, high-throughput compute. Besides, rather than fully separating every request, PrfaaS offloads only long uncached prefills to these compute-dense prefill clusters, while short requests remain on the local PD path. The resulting KVCache is then transferred over commodity Ethernet to decode-capable PD clusters. This design reflects the underlying systems reality: the motivation to split prefill is strong, but the reduced KVCache of hybrid models is still not cheap enough to justify indiscriminate transfer. What makes the design feasible is selective offloading, which concentrates cross-cluster transfer on the requests for which prefill acceleration matters most, while avoiding the inefficiency of sending short requests through a bandwidth-constrained path.
Making this design work requires scheduling and cache management that explicitly address the remaining systems challenges. Considering that bandwidth remains constrained even after KVCache reduction, PrfaaS uses length-based threshold routing to offload only sufficiently long requests, a bandwidth-aware scheduler to react to fluctuating link conditions before congestion accumulates, and a global KVCache manager with a hybrid prefix-cache pool to account jointly for request length, cache placement, and available cross-cluster bandwidth. These mechanisms make cross-cluster heterogeneous serving viable in realistic environments: they preserve the benefits of PD disaggregation without requiring heterogeneous accelerators to share the same low-latency RDMA fabric, and they allow compute-oriented prefill capacity and bandwidth-oriented decode capacity to scale independently across loosely coupled clusters, datacenters, or regions.
This flexibility directly addresses deployment constraints that are otherwise difficult to resolve in practice, including non-colocated accelerator classes, hardware asymmetry across cloud regions, and opportunistic remote capacity. We evaluate this idea through a case study using an internal 1T-parameter hybrid model following the Kimi Linear architecture [26]. With a heterogeneous deployment consisting of a standalone PrfaaS cluster for long-context prefill and a conventional PD cluster for decode and short prefills, the system achieves 54% and 32% higher serving throughput than homogeneous PD and naive heterogeneous baselines, respectively, while consuming only modest cross-datacenter bandwidth per machine. These results show that KVCache-efficient model architectures are necessary but not sufficient for cross-datacenter heterogeneous serving. What makes the deployment practical is the combination of model-side KVCache reduction with system-side selective offloading and bandwidth-aware scheduling. Together, they turn cross-datacenter PD disaggregation from an appealing idea into a realistic serving architecture.
2 Background
2.1 The Bandwidth Wall in Conventional PD Disaggregation
Prefill-decode (PD) disaggregation has become the standard systems abstraction for large-scale LLM serving because it cleanly separates two fundamentally different phases of inference: prefill is dominated by arithmetic throughput, while decode is dominated by memory bandwidth. That separation improves utilization and enables phase-specific optimization. But it does not come for free. Once prefill and decode are placed on different nodes, every request must export its KVCache from the prefill side to the decode side, turning what was previously an on-device state transition into a cross-node transport problem. In practice, that transport requirement is what keeps today’s PD deployments confined to a single data center and attached to RDMA-class scale-out networks.
Table 1: Configurations of representative models. Type A denotes the linear-complexity block, and Type B denotes the quadratic-complexity full attention block. Model Attention Type A Attention Type B A:B Ratio Model Params Kimi Linear [26] KDA [26] MLA [12] 3:1 48B MiMo-V2-Flash [31] SWA [5] GQA [4] 5:1 309B Qwen3.5-397B [27] GDN [33] GQA 3:1 397B Ring-2.5-1T [3] Lightning [23] MLA 7:1 1T MiniMax-M2.5 [16] – GQA – 229B Qwen3-235B [32] – GQA – 235B
Under latency-sensitive serving constraints, KVCache produced by prefill instances can be shipped asynchronously to maximize compute utilization. To avoid GPU idling, the egress bandwidth BoutB_{\text{out}} of a prefill cluster must exceed the aggregate rate at which the cluster produces KVCache. Because this aggregate rate scales linearly with the number of instances, the binding constraint reduces to the KV throughput of a single model instance, which we define as
Φkv(l)=Skv(l)Tprefill(l),\Phi_{\text{kv}}(l)=\frac{S_{\text{kv}}(l)}{T_{\text{prefill}}(l)}, (1)
where Skv(l)S_{\text{kv}}(l) is the KVCache size for a request of length ll and Tprefill(l)T_{\text{prefill}}(l) is the corresponding prefill latency. The value of this metric depends largely on model architecture. Table 1 summarizes the configurations considered in this paper. For conventional dense-attention architectures, this transport demand is a dominant systems constraint. In standard Transformer-style attention, KVCache grows linearly with context length and can reach tens of gigabytes. Figure 2 shows the KV throughput of MiniMax-M2.5, a representative dense model with GQA, at various input lengths. The bottleneck is stark: for a 32K-token request, a single MiniMax-M2.5 instance produces KVCache at roughly 60 Gbps, requiring egress bandwidth that far exceeds the cross-datacenter Ethernet capacity of a typical machine. This is precisely why conventional PD disaggregation remains operationally tied to tightly integrated network domains. The network budget is so large that moving prefill and decode across looser interconnects, let alone across data centers, is simply not realistic.
That network coupling also prevents heterogeneous serving from scaling cleanly. Specialized chips already exist for each phase: hardware such as Rubin CPX targets prefill throughput, while LPU-style designs target decode bandwidth. Yet high-performance interconnects remain tightly coupled to machine form factors and deployment environments, so connecting unlike hardware at RDMA-class bandwidth generally requires bespoke engineering. Worse, once heterogeneous hardware is forced into a single tightly coupled cluster, the system inherits a fixed prefill-to-decode hardware ratio. In production traffic, request mix, request volume, and prefix-cache hit rate fluctuate continuously, so one side of the pipeline inevitably becomes overprovisioned while the other becomes the bottleneck. In a homogeneous cluster, any machine can be dynamically reassigned between prefill and decode roles as load shifts. A heterogeneous cluster offers no such flexibility: a chip specialized for prefill cannot serve decode and vice versa, leading to severe load imbalance and stranded capacity. The result is higher operational complexity and limited real-world adoption of heterogeneous PD beyond bespoke or low-throughput scenarios.
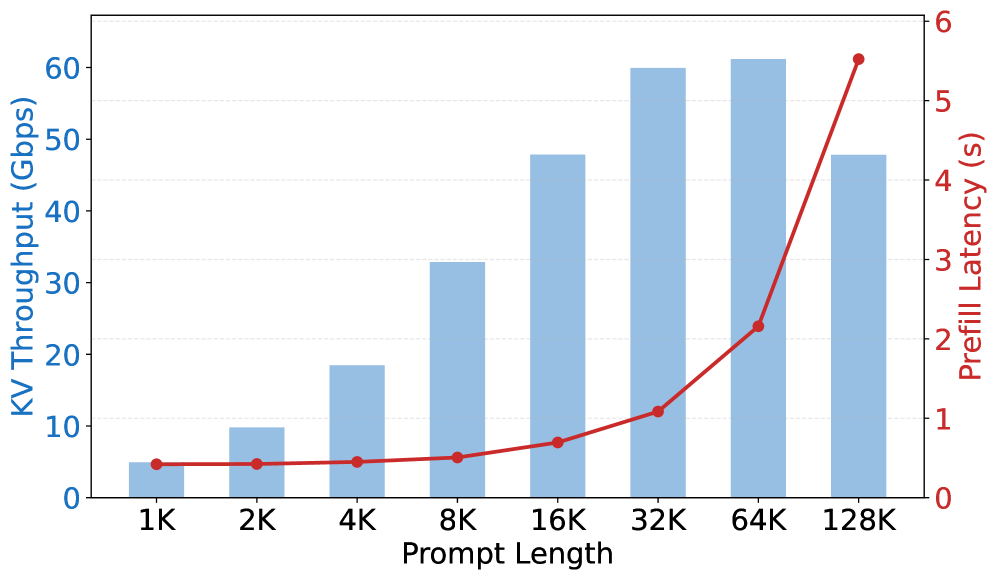
Figure 2: KV throughput of MiniMax-M2.5 on an 8×\timesH200 instance at various input lengths. Mechanism Prefill Latency KV Throughput GQA High High MLA High Low Sparse Attention Low High SWA Low Low Linear Attention Low Low Table 2: Prefill latency and KV throughput characteristics of different attention mechanisms. Lower is better for both metrics.
2.2 Hybrid Attention Changes the PD Deployment Boundary
Table 3: KV throughput Φkv\Phi_{\text{kv}} (Gbps) at various input lengths. All models are benchmarked on 8×\timesH200 with SGLang v0.5.9 [7]. Hybrid Dense Seq Len Kimi Linear MiMo-V2-Flash Qwen3.5-397B Ring-2.5-1T MiniMax-M2.5 Qwen3-235B 1K 1.19 0.82 4.13 7.27 4.94 4.12 8K 2.29 2.85 6.28 4.47 32.87 22.42 32K 3.87 4.66 8.25 2.59 59.93 33.35 128K 4.88 4.71 7.47 1.46 47.82 21.50
What changes this picture is not a new scheduler alone, but a shift in model architecture. As LLMs move toward longer contexts, the cost of conventional MHA becomes increasingly untenable, prompting a broad transition toward KVCache-friendly designs. Table 2 categorizes mainstream attention improvements along two dimensions: prefill latency (TprefillT_{\text{prefill}}) and KV throughput (Φkv\Phi_{\text{kv}}). Under long-context workloads, full attention mechanisms such as GQA and MLA retain quadratic complexity, resulting in high prefill cost. Sparse attention [6] reduces the amount of computation and can lower prefill latency, but it still requires transferring sequence-length-dependent KVCache to decode instances, leaving KV throughput as the dominant bottleneck. By contrast, linear attention and SWA maintain linear computation cost, while their bounded state size substantially reduces KV throughput.
A growing number of flagship open-source models adopt linear attention [26, 27, 3, 18] or SWA [31, 11, 2], combining these mechanisms into hybrid stacks that interleave a small number of full-attention layers with a larger number of linear-complexity layers. Representative examples include Qwen3.5-397B at a 3:1 linear-to-full ratio, MiMo-V2-Flash at a 5:1 SWA-to-full ratio, and Ring-2.5-1T at a 7:1 linear-to-full ratio. In these architectures, only the full-attention layers produce KVCache that scales with sequence length, while the linear-complexity layers maintain fixed-size recurrent state whose footprint becomes negligible in the long-context regime.
Equation (1) quantifies how model architecture governs the bandwidth demand of PD disaggregation. Table 3 benchmarks Φkv\Phi_{\text{kv}} for several recent open-source dense and hybrid models. Compared with dense models of similar size, hybrid models exhibit a sharp reduction in Φkv\Phi_{\text{kv}}, meaning that each unit of compute generates far less state that must later traverse the network. At 32K tokens, MiMo-V2-Flash achieves a KV throughput of 4.66 Gbps versus 59.93 Gbps for MiniMax-M2.5, a 13×\times reduction. Qwen3.5-397B reaches 8.25 Gbps versus 33.35 Gbps for Qwen3-235B, a 4×\times reduction. The paper further notes that for Ring-2.5-1T, MLA contributes roughly a 4.5×\times compression over GQA, while the 7:1 hybrid ratio contributes another ∼{\sim}8×\times reduction, yielding an overall KV memory saving of roughly 36×\times.
The key systems implication is not merely lower inference cost, but a reduced KV throughput that shifts the deployable network boundary of PD disaggregation from RDMA-class fabrics to commodity Ethernet. In dense-attention models, prefill emits too much state too quickly, so the network becomes the hard coupling between phases. In hybrid models, prefill still performs substantial work, but the emitted KVCache is dramatically smaller. This does not make cross-datacenter PD free enough for indiscriminate transfer. Rather, it opens a qualitatively different operating regime in which cross-cluster KVCache transport becomes plausible for selected requests and therefore worth optimizing at the system level.
2.3 From Intra-Datacenter PD to Prefill-as-a-Service Paradigm
In intra-datacenter PD deployments, prefill and decode nodes communicate over high-bandwidth, fully meshed networks such as RDMA, so the network is far from being a bottleneck relative to prefill computation. In cross-cluster PD, however, the relationship between inter-cluster bandwidth and model KV throughput directly determines whether cross-datacenter KVCache is feasible. The cluster-level bandwidth requirement follows from the per-instance KV throughput. For an NN-GPU prefill cluster, the minimum egress bandwidth is
Bout=NP⋅𝔼[Skv]𝔼[Tprefill]≈NP⋅Φkv(Lavg),B_{\text{out}}=\frac{N}{P}\cdot\frac{\mathbb{E}[S_{\text{kv}}]}{\mathbb{E}[T_{\text{prefill}}]}\approx\frac{N}{P}\cdot\Phi_{\text{kv}}(L_{\text{avg}}), (2)
where PP is the parallelism degree (GPUs per instance) and LavgL_{\text{avg}} is the average uncached input length of the requests actually offloaded to the PrfaaS cluster. Notably, BoutB_{\text{out}} depends not only on Φkv\Phi_{\text{kv}}, which is governed by model architecture and hardware, but also on LavgL_{\text{avg}}, which is shaped by request length distribution, prefix-cache hit rate, and routing policy. This dependence is exactly why hybrid models alone are not enough. On the model side, adopting KVCache-friendly architectures reduces Φkv\Phi_{\text{kv}}. On the system side, selective offloading and a bandwidth-aware scheduler that accounts for bandwidth constraints and KVCache locality (§3.4) determine which requests consume the cross-datacenter budget in the first place, keeping BoutB_{\text{out}} within the available inter-datacenter bandwidth envelope.
To make the analysis concrete, we consider a prefill cluster comprising 512 H200 GPUs with Lavg=32KL_{\text{avg}}=32\text{K}. Under this configuration, MiniMax-M2.5 and Qwen3 respectively require 3.8 Tbps and 2.1 Tbps of egress bandwidth, which effectively locks deployment into a tightly integrated single-cluster fabric. By contrast, models that employ hybrid architectures see their KV throughput drop by an order of magnitude, bringing the bandwidth demand to a level that modern inter-datacenter links can sustain. Ring-2.5-1T requires roughly 170 Gbps of dedicated line capacity. Moreover, by routing even longer requests (e.g., 128K tokens) to the PrfaaS cluster for processing, the bandwidth demand falls further to below 100 Gbps. Even at the scale of a 10,000-GPU datacenter, the aggregate egress bandwidth totals only about 1.8 Tbps, well within the capacity of physical inter-datacenter links.
That is the systems turning point described before. Once KV throughput falls far enough, heterogeneous serving no longer has to be implemented solely as an awkward co-location of unlike accelerators behind the same RDMA island. Instead, prefill can be selectively externalized into standalone, compute-dense Prefill-as-a-Service clusters, while decode remains in conventional bandwidth-optimized PD clusters. The problem then shifts from “how do we force heterogeneous hardware into one tightly coupled deployment?” to “how do we identify the requests worth offloading and transport their KVCache across loosely coupled clusters efficiently?” In that sense, KVCache-friendly model architectures, together with selective offloading and bandwidth-aware scheduling, jointly enable heterogeneous PD disaggregation to scale beyond a single datacenter.
3 Disaggregation over Cross-Datacenter KVCache
3.1 Overview
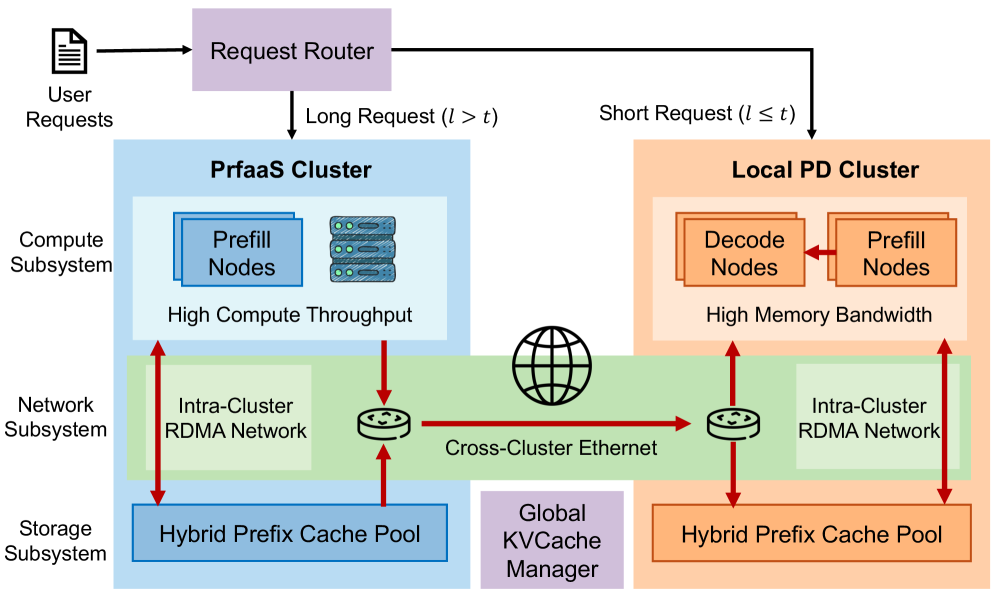 Figure 3: Deployment topology of the PrfaaS-PD architecture.
Figure 3: Deployment topology of the PrfaaS-PD architecture.
The core idea of cross-datacenter KVCache is not to externalize every prefill, but to selectively extend disaggregated LLM serving beyond the boundary of a single cluster when remote prefill acceleration is worth the transfer cost. We realize this vision through the PrfaaS-PD architecture, which leverages cross-datacenter KVCache to decouple prefill and decode across loosely connected clusters for requests whose long uncached prefills benefit most from faster compute. As shown in Figure 3, dedicated PrfaaS clusters perform compute-intensive long-context prefill on cost-effective, high-throughput accelerators and stream the resulting KVCache to local PD clusters via commodity Ethernet, while short or bandwidth-unfriendly requests remain on the local PD path.
The PrfaaS-PD architecture comprises three subsystems: compute, network, and storage. The compute subsystem consists of multiple clusters, each containing only homogeneous hardware, as different chip types are typically difficult to co-locate within the same facility. Clusters fall into two categories. Local PD clusters perform PD-disaggregated serving and can complete inference for a request end to end. PrfaaS clusters provide selective remote prefill capacity for requests whose incremental uncached length exceeds a routing threshold. After prefill, the resulting KVCache is transferred to a local PD cluster for decode. The network subsystem spans two tiers: intra-cluster networks use RDMA for latency-sensitive collective communication and PD KVCache transfers, while inter-cluster links rely on VPC peering or dedicated lines for cross-datacenter KVCache transfer. The storage subsystem resides within each cluster, building a distributed hybrid prefix cache pool (§3.2) across all machines. A global KVCache manager maintains KVCache metadata across all clusters. On top of these infrastructure components, a global scheduler routes requests to clusters and nodes based on request characteristics, network conditions, and cache distribution, maximizing end-to-end throughput under cross-cluster bandwidth constraints, as detailed in §3.4.
3.2 Hybrid Prefix Cache Pool
Prefix cache pools allow the serving system to offload KVCache to distributed host memory and SSDs within a cluster, substantially increasing the prefix cache hit rate. Conventional prefix cache pools, however, are designed for a single KVCache type and perform matching and eviction at the token or block level. In hybrid models, the recurrent states of linear attention or SWA layers are request-level: their size is independent of input length, and they can only be reused when the cached length matches exactly. In contrast, the KVCache of full attention layers are block-level: they grow linearly with input length and support partial prefix matching. This heterogeneity challenges the conventional all-layer-uniform KVCache storage paradigm.
Based on vLLM’s hybrid KVCache manager [28], we build a hybrid prefix cache system tailored for cross-cluster KVCache transfer, as shown in Figure 4. Linear states and full-attention KVCache are managed by separate KVCache groups with aligned block sizes, allowing all groups to allocate and free blocks from a shared KVCache pool. On top of this shared pool, we partition cache blocks into two categories: prefix-cache blocks and transfer-cache blocks. Prefix-cache blocks must be fully populated before they can be reused across requests. Transfer-cache blocks hold the KVCache produced at the tail of a prefill request for PD-disaggregated transfer, and the cache pool discards them once the transfer completes.
When a new request arrives, the global KVCache manager computes prefix-match information for every cluster, and the request router uses this information to select the prefill cluster and the cache-affine node within it. Beyond routing, the KVCache manager also performs cache rebalancing to mitigate hotspots. When sufficient inter-cluster bandwidth is available, cross-cluster cache transfer is feasible as well, as discussed in §3.4.3.
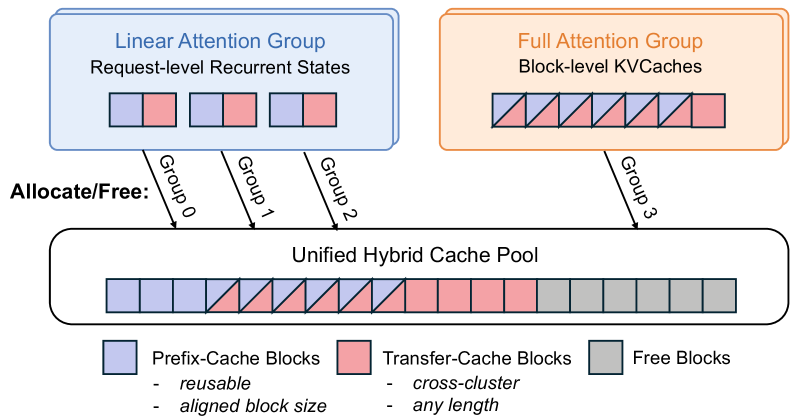 Figure 4: Hybrid prefix cache pool. Linear states and full-attention KVCache are managed by separate groups backed by a unified block pool. Blocks are categorized as prefix-cache (intra-cluster only, block-aligned) or transfer-cache (cross-cluster, discarded after transfer).
Figure 4: Hybrid prefix cache pool. Linear states and full-attention KVCache are managed by separate groups backed by a unified block pool. Blocks are categorized as prefix-cache (intra-cluster only, block-aligned) or transfer-cache (cross-cluster, discarded after transfer).
3.3 PrfaaS-PD Disaggregation
Building on conventional intra-cluster PD disaggregation, we introduce PrfaaS clusters as a selective extension that increases deployment scalability and lowers cost without forcing all requests onto the cross-cluster path. A PrfaaS-PD system may contain several PrfaaS and local PD clusters, whose sizes and ratios are determined by hardware capabilities, network bandwidth, and request traffic.
Each PrfaaS cluster functions as a stateless KVCache producer whose effective throughput equals the minimum of its prefill computation rate and its network egress bandwidth. Not all requests benefit equally from being offloaded to a PrfaaS cluster. Short-context prefill is typically memory- or communication-bound rather than compute-bound, resulting in low arithmetic utilization that cannot fully exploit the compute-dense accelerators in PrfaaS clusters. We therefore retain prefill nodes within the local PD cluster and apply a length-based routing policy. Let ll denote the incremental prefill length of a request (excluding any cached prefix) and tt a routing threshold. When ltlt, the request is routed to a PrfaaS cluster, and the resulting KVCache is transferred to a decode node upon completion. When l≤tl\leq t, the request is handled by a prefill node within the PD cluster. With the growing adoption of agentic workloads, the majority of requests are incremental prefills with prefix cache hits. For such requests, the global KVCache manager tracks the storage locations of all cached entries, ensuring that only the incremental portion is transferred across clusters. The scheduler must jointly consider cache affinity and cluster bandwidth when making routing decisions, as discussed in §3.4.3.
Realizing PrfaaS-PD disaggregation in practice requires stable, high-throughput Ethernet transport. Although hybrid model architectures substantially reduce the nominal bandwidth requirement, bursty traffic and uneven link utilization can still cause congestion, increasing queuing delay and degrading KVCache delivery efficiency. Our design therefore aims to smooth transfer traffic and sustain high link utilization without inducing persistent congestion. To this end, we combine layer-wise prefill pipelining to overlap KVCache generation with transmission, multi-connection TCP transport to fully utilize the available bandwidth, and congestion monitoring integrated with the scheduler to detect loss and retransmission signals early and prevent congestion accumulation.
3.4 Modeling and Scheduling
A PrfaaS-PD system comprises three roles: PrfaaS prefill, PD-P (the prefill nodes within a PD cluster), and PD-D (the decode nodes within a PD cluster). To derive scheduling policies, we construct an analytical throughput model that captures the compute and bandwidth constraints of each role and use it to guide both short-term routing and long-term resource allocation.
3.4.1 Throughput Model
Table 4: Notation used in the PrfaaS-PD throughput model. Traffic System Λ\Lambda Request arrival rate (throughput) NprfaasN_{\text{prfaas}} PrfaaS prefill instances LL Uncached input length (r.v.) NpN_{p}, NdN_{d} PD-P / PD-D instances tt Routing threshold BoutB_{\text{out}} PrfaaS egress bandwidth llongl_{\text{long}} 𝔼[L∣Lt]\mathbb{E}[L\mid Lt], mean PrfaaS length 𝐵𝑆max\mathit{BS}{\max} Max decode batch size lshortl PD-P / PD-D throughput (req/s) }} 𝔼[L∣L≤t]\mathbb{E}[L\mid L\leq t], mean PD-P length Tprefill(l)T_{\text{prefill}}(l) Prefill time for length ll pp P(Lt)P(Lt), fraction to PrfaaS TdecodeT_{\text{decode}} Per-step decode time LoutL_{\text{out}} Mean output length Θprfaas\Theta_{\text{prfaas}} PrfaaS throughput (req/s) Skv(l)S_{\text{kv}}(l) KVCache size for length ll Θpd-p\Theta_{\text{pd-p}}, Θpd-d\Theta_{\text{pd-d}
We model the steady-state throughput of the PrfaaS-PD system using the notation in Table 4. For tractability, we approximate all PrfaaS requests by a representative length llong=𝔼[L∣Lt]l_{\text{long}}=\mathbb{E}[L\mid Lt] with service time Tprefill(llong)T_{\text{prefill}}(l_{\text{long}}), and all PD-P requests by lshort=𝔼[L∣L≤t]l_{\text{short}}=\mathbb{E}[L\mid L\leq t] with service time Tprefill(lshort)T_{\text{prefill}}(l_{\text{short}}). Requests arrive uniformly at aggregate rate Λ\Lambda. A fraction p=P(Lt)p=P(Lt) of requests are routed to PrfaaS, and the remaining 1−p1-p are handled by PD-P.
Each PrfaaS request undergoes two pipelined phases: prefill computation and KVCache transfer. Through layer-wise prefill pipelining, the PrfaaS cluster throughput is determined by the slower of compute and egress transfer:
Θprfaas=min(NprfaasTprefill(llong),BoutSkv(llong)).\Theta_{\text{prfaas}}=\min\!\left(\frac{N_{\text{prfaas}}}{T_{\text{prefill}}(l_{\text{long}})},\;\frac{B_{\text{out}}}{S_{\text{kv}}(l_{\text{long}})}\right). (3)
Since intra-cluster RDMA bandwidth is not a bottleneck, PD-P throughput is determined solely by compute capacity:
Θpd-p=NpTprefill(lshort).\Theta_{\text{pd-p}}=\frac{N_{p}}{T_{\text{prefill}}(l_{\text{short}})}. (4)
The decode-stage (PD-D) throughput is
Θpd-d=Nd⋅𝐵𝑆maxTdecode⋅Lout,\Theta_{\text{pd-d}}=\frac{N_{d}\cdot\mathit{BS}_{\max}}{T_{\text{decode}}\cdot L_{\text{out}}}, (5)
where 𝐵𝑆max\mathit{BS}{\max} and TdecodeT are treated as SLO-governed constants.}
PrfaaS and PD-P serve as upstream producers, each prefilling a disjoint subset of requests (fractions pp and 1−p1{-}p, respectively), while PD-D is the sole downstream consumer. Together, they form a converging pipeline:
RequestPrfaaS PrefillPD-P PrefillPD-D Decodepp1−p1{-}pEthernetRDMA
The end-to-end system throughput is limited by the slowest stage, accounting for the routing split:
Λmax=min(Θprfaasp,Θpd-p1−p,Θpd-d).\Lambda_{\max}=\min\!\left(\frac{\Theta_{\text{prfaas}}}{p},\;\frac{\Theta_{\text{pd-p}}}{1-p},\;\Theta_{\text{pd-d}}\right). (6)
3.4.2 Throughput-Optimal Configuration
Given fixed hardware resources (NprfaasN_{\text{prfaas}}, Np+NdN_{p}{+}N_{d}) and network bandwidth BoutB_{\text{out}}, we seek two decision variables that maximize Λmax\Lambda_{\max}: the routing threshold tt (which determines pp, llongl_{\text{long}}, and lshortl_{\text{short}}) and the PD-cluster prefill-to-decode ratio Np/NdN_{p}/N_{d}.
The threshold tt governs the trade-off between PrfaaS and PD-P load. Increasing tt restricts PrfaaS to longer requests, for which Tprefill(l)T_{\text{prefill}}(l) grows faster than Skv(l)S_{\text{kv}}(l) (near-quadratic prefill versus linear KVCache size). This lowers the per-instance KV throughput and eases bandwidth pressure. Conversely, decreasing tt floods PrfaaS with shorter requests whose high KV throughput is more likely to trigger the bandwidth bottleneck. The optimal tt balances PrfaaS and PD-P throughput so that both stages approach saturation simultaneously:
Θprfaasp=Θpd-p1−p.\frac{\Theta_{\text{prfaas}}}{p}=\frac{\Theta_{\text{pd-p}}}{1-p}. (7)
For a fixed cluster size Np+NdN_{p}+N_{d} (the number of machines in a datacenter is constant in the short term), the ratio Np/NdN_{p}/N_{d} should balance the aggregate producer throughput against the consumer throughput. Too few prefill nodes starve the decode stage of KVCache, while too many leave prefill capacity idle. The optimal ratio satisfies
Θprfaas+Θpd-p=Θpd-d.\Theta_{\text{prfaas}}+\Theta_{\text{pd-p}}=\Theta_{\text{pd-d}}. (8)
Equations (7) and (8) constrain two unknowns, tt and Np/NdN_{p}/N_{d}. Because Θprfaas/p\Theta_{\text{prfaas}}/p decreases monotonically with pp (and hence with decreasing tt) while Θpd-p/(1−p)\Theta_{\text{pd-p}}/(1{-}p) increases, a grid search over tt and Np/NdN_{p}/N_{d} efficiently finds the optimal operating point.
3.4.3 Dual-Timescale Scheduling
The scheduling is central to making cross-datacenter disaggregation practical rather than merely architecturally possible. In theory, hybrid model architectures reduce KV throughput enough that commodity Ethernet links can sustain cross-cluster transfers, and the steady-state analysis above can maximize cluster throughput by optimizing tt and Np/NdN_{p}/N_{d}. In practice, however, traffic variations and burstiness can cause transient congestion and queue buildup at the PrfaaS egress. Moreover, clusters maintain large prefix caches whose bulk transfers can further strain cross-cluster links. To handle this dynamic environment, we design a dual-timescale scheduling algorithm that treats cross-cluster bandwidth and throughput as the primary constraints, separating the factors governing request routing and resource allocation into short-term and long-term categories with a dedicated strategy for each.
Short-term: bandwidth- and cache-aware routing.
The PrfaaS cluster has a bandwidth-imposed throughput ceiling Bout/Skv(llong)B_{\text{out}}/S_{\text{kv}}(l_{\text{long}}). As the cluster approaches this ceiling, congestion builds at the egress link. The scheduler therefore continuously monitors the PrfaaS egress utilization and request queue depth. When utilization approaches a threshold or queuing surges, a short-term routing adjustment is triggered.
At initialization or upon a policy update, the scheduler profiles current compute capacity and egress bandwidth, then searches for the optimal threshold tt based on the incremental prefill-length distribution after prefix matching. By routing only sufficiently long requests to PrfaaS, the scheduler reduces per-request bandwidth demand and avoids congestion near the bandwidth ceiling.
For requests with prefix cache hits, the scheduler must jointly consider cache affinity and bandwidth availability. Let ltotall_{\text{total}} denote the total input length of a request, and let lprfaasl_{\text{prfaas}} and lpdl_{\text{pd}} denote the cached prefix lengths in the PrfaaS and PD clusters, respectively. The routing depends on whether bandwidth or compute is the binding constraint. When bandwidth is scarce, prefix caches in each cluster are evaluated independently: if ltotal−lpd≤tl_{\text{total}}-l_{\text{pd}}\leq t, the request is prefilled locally in PD-P, and otherwise offloaded to PrfaaS. When bandwidth is abundant, compute becomes the scarce resource, and cross-cluster cache transfer can reduce redundant computation. The scheduler considers the best cache across all clusters by letting lprefix=max(lprfaas,lpd)l_{\text{prefix}}=\max(l_{\text{prfaas}},\,l_{\text{pd}}); if ltotal−lprefix≤tl_{\text{total}}-l_{\text{prefix}}\leq t, the request is prefilled in PD-P; otherwise it goes to PrfaaS. When the cluster with the longer cache differs from the compute cluster, a cross-cluster cache transfer is performed.
Long-term: traffic-driven allocation re-optimization.
Over longer timescales, shifts in traffic volume create persistent imbalances between pipeline stages. When Θprfaas+Θpd-p≪Θpd-d\Theta_{\text{prfaas}}+\Theta_{\text{pd-p}}\ll\Theta_{\text{pd-d}}, prefill is the system bottleneck, and when Θprfaas+Θpd-p≫Θpd-d\Theta_{\text{prfaas}}+\Theta_{\text{pd-p}}\gg\Theta_{\text{pd-d}}, decode is. The scheduler identifies the binding constraint by monitoring queue depth and utilization at each stage. Since traffic variations at this timescale are gradual and often periodic, the scheduler periodically re-evaluates load balance and converts nodes between prefill and decode roles within the PD cluster, adjusting NpN_{p} and NdN_{d} to restore the optimality conditions of Equations (7) and (8). As instance counts change, the routing threshold tt is re-optimized accordingly.
4 Case Study: Bandwidth Demand of PrfaaS-PD Architecture
In this section, we use an internal 1T-parameter hybrid-architecture model as a case study to evaluate whether selective PrfaaS offloading can keep cross-datacenter KVCache transfer within a realistic bandwidth budget while improving system throughput under realistic hardware and deployment settings. Following the notation in Table 4, we apply the profiling-based throughput model from §3.4 to solve for two key parameters that maximize system throughput: the routing threshold tt and the prefill-to-decode instance ratio Np/NdN_{p}/N_{d} within the local PD cluster. Under the resulting configuration, the heterogeneous PrfaaS-PD deployment achieves 54% higher throughput and 64% lower P90 TTFT than a homogeneous PD-only baseline, and 32% higher throughput than a naive heterogeneous deployment without scheduling. The average PrfaaS cluster egress is only 13 Gbps, well within the Ethernet capacity.
4.1 Setup
Table 5: KVCache size SkvS_{\text{kv}}, prefill latency TprefillT_{\text{prefill}}, and KV throughput Φkv\Phi_{\text{kv}} of the internal 1T hybrid model at various input lengths. Prefill latency is benchmarked on 8×\timesH200 with in-house vLLM [29]. Seq Len KVCache Size Prefill Latency KV Throughput 1K 190.8 MiB 0.44 s 3.61 Gbps 8K 308.9 MiB 0.72 s 3.59 Gbps 32K 701.3 MiB 1.84 s 3.19 Gbps 128K 2316.3 MiB 7.40 s 2.62 Gbps
We deploy two clusters connected by a VPC network, providing an aggregate cross-cluster bandwidth of approximately 100 Gbps. The PrfaaS cluster consists of 32 H200 GPUs with higher compute throughput, dedicated to long-context prefill requests with LtLt. The local PD cluster consists of 64 H20 GPUs operating in conventional PD-disaggregated mode with 800 Gbps RDMA interconnect per node, where the prefill-to-decode ratio can be adjusted according to request traffic. Note that although H200 and H20 have different price points, the PrfaaS cluster only requires high compute throughput. In production deployments, cost-effective accelerators with comparable compute capability can serve as substitutes. As a baseline, we use a homogeneous PD cluster of 96 H20 GPUs.
To reflect realistic serving requirements, the workload uses an internal hybrid model with 1T parameters whose architecture follows Kimi Linear [26], employing an interleaved KDA:MLA layer structure at a 3:1 ratio. The model is deployed at 8 GPUs per instance and profiled separately for prefill and decode using in-house vLLM. Table 5 lists the KVCache size SkvS_{\text{kv}}, prefill latency TprefillT_{\text{prefill}}, and KV throughput Φkv\Phi_{\text{kv}} for this model at various input lengths.
Request input lengths follow a truncated log-normal distribution (μ=9.90\mu=9.90, σ=1.00\sigma=1.00, truncated to [128, 128K][128,\,128\text{K}]) with a mean of approximately 27K tokens, reflecting the long-context distribution characteristic of real-world workloads. The output length is fixed at 1024 tokens, and the SLO (excluding speculative decoding) is set to 40 tokens/s. All throughput and bandwidth results reported below are derived by feeding the measured profiling data into the throughput model of §3.4.
4.2 Throughput Modeling and Solution
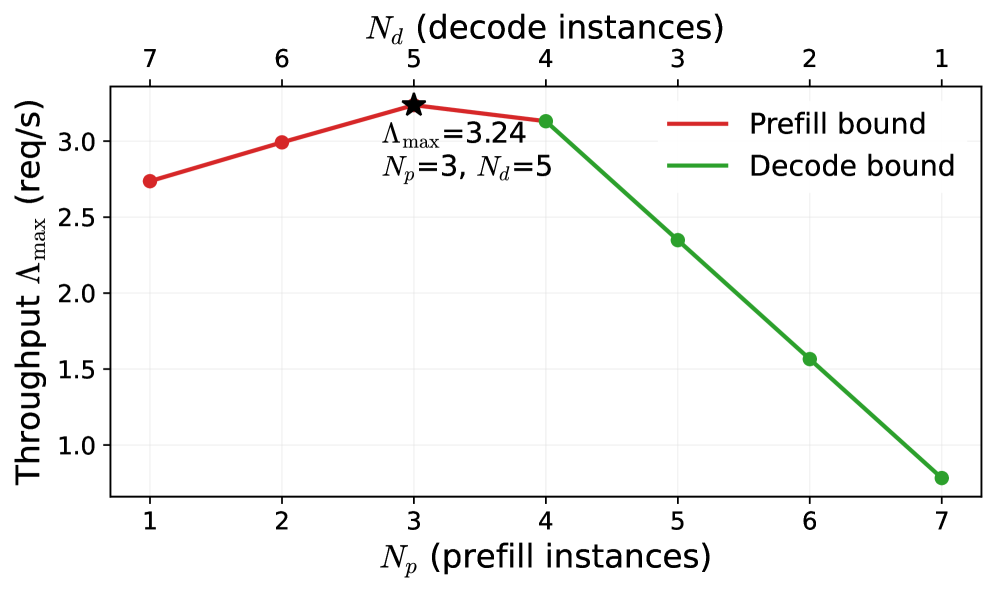 (a) Search over prefill/decode allocation.
(a) Search over prefill/decode allocation.
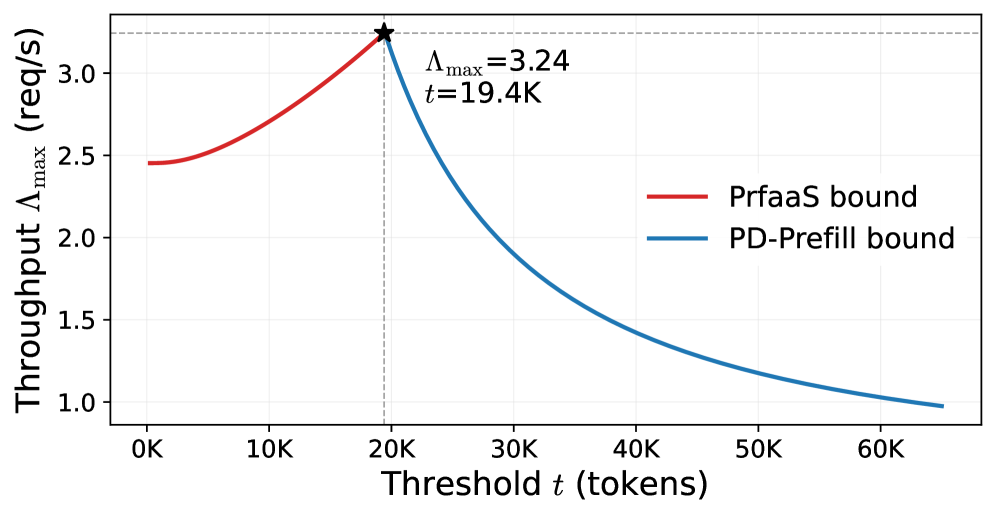 (b) Search over routing threshold tt.
(b) Search over routing threshold tt.
Figure 5: Illustration of the grid search process for the two optimization variables. (a) fixes tt at the optimum and searches over the prefill/decode instance split within the local PD cluster. (b) fixes Np=3N_{p}=3, Nd=5N_{d}=5 and searches over tt.
Using the PrfaaS-PD throughput model from §3.4, we optimize the routing threshold tt and the PD-cluster prefill/decode allocation to maximize Λmax\Lambda_{\max}. We solve them by exhaustive two-dimensional grid search. The optimal configuration is listed in the second column of Table 6.
Figure 5 illustrates the search process, fixing one variable and searching over the other. Figure 5(a) shows that, for a fixed threshold tt (and hence fixed Θprfaas\Theta_{\text{prfaas}}), the system throughput peaks when prefill and decode throughput are approximately balanced. The optimal allocation in the local PD cluster is Np=3N_{p}=3 and Nd=5N_{d}=5. Figure 5(b) fixes Np=3N_{p}=3 and Nd=5N_{d}=5, therefore the overall Λmax\Lambda_{\max} is determined by min(Θprfaas/p,Θpd-p/(1−p))\min(\Theta_{\text{prfaas}}/p,\;\Theta_{\text{pd-p}}/(1{-}p)). The optimum occurs at the intersection of the two curves, yielding t=19.4t=19.4K. At this operating point, approximately 50% of all requests (the longer ones) are offloaded to the PrfaaS cluster, fully utilizing the high-compute-throughput accelerators.
Table 6: Comparison of optimal configurations across PrfaaS-PD, homogeneous PD, and naive heterogeneous PD deployments. Metric PrfaaS-PD Homogeneous PD Naive Heterogeneous PD Threshold tt 19.4K — — NprfaasN_{\text{prfaas}} / NpN_{p} / NdN_{d} 4 / 3 / 5 — / 9 / 3 4 / — / 8 Mean / P90 TTFT (s) 2.22 / 3.51 4.44 / 9.73 1.74 / 3.51 Θprfaas\Theta_{\text{prfaas}} / Θpd-p\Theta_{\text{pd-p}} / Θpd-d\Theta_{\text{pd-d}} (req/s) 1.61 / 1.64 / 3.91 — / 2.11 / 2.35 2.45 / — / 6.25 Λmax\Lambda_{\max} (req/s) 3.24 2.11 2.45 Ratio 1.54×\times 1.00×\times 1.16×\times
4.3 Result Analysis
4.3.1 Cross-Datacenter Bandwidth Utilization
A key prerequisite for the PrfaaS-PD architecture is that the inter-cluster network link can sustain the KVCache transfer demand. We evaluate this by measuring the KV throughput of the PrfaaS cluster under the deployed workload distribution.
With the routing threshold set to t=19.4t=19.4K, 49.6% of requests are routed to PrfaaS, and the offloaded subset has 𝔼[L∣Lt]≈44\mathbb{E}[L\mid Lt]\approx 44K tokens. The aggregate PrfaaS egress load is therefore approximately 13 Gbps, consuming only 13% of the Ethernet link. This confirms that the KVCache of a hybrid-architecture model can be transported over commodity Ethernet with substantial headroom with proper scheduling. By contrast, conventional Transformer models with full KV heads would produce significantly larger KVCache volumes, potentially requiring RDMA-class interconnects.
4.3.2 Comparison with Homogeneous PD
We apply the same throughput modeling methodology to the homogeneous PD baseline of 96 H20 GPUs. The results are shown in the third column of Table 6. In the homogeneous cluster, the system throughput is also maximized when prefill and decode throughput are balanced, yielding an optimal allocation of 9 prefill instances and 3 decode instances.
Thanks to the superior compute throughput of the PrfaaS cluster, the PrfaaS-PD configuration requires two fewer prefill instances in the local PD cluster, freeing capacity for additional decode slots. The overall system throughput improves by 54%.
Another key benefit of PrfaaS-PD is the reduction in TTFT, particularly for long-context requests. In the homogeneous baseline, long requests compete with short requests for prefill capacity, inflating queuing delays. In PrfaaS-PD, long requests are offloaded to the dedicated high-throughput PrfaaS cluster, where prefill completes significantly faster than in the PD cluster even after accounting for cross-cluster transfer latency. As shown in Table 6, the mean and P90 TTFT are reduced by 50% and 64%, respectively, compared to the homogeneous baseline.
4.3.3 Comparison with Naive Heterogeneous PD
The comparison with homogeneous PD demonstrates the fundamental performance advantage of heterogeneous deployment. The comparison with naive heterogeneous PD further highlights the importance of scheduling in heterogeneous systems. In the naive heterogeneous PD configuration, no scheduling optimization is applied: all prefill is assigned to H200 GPUs and all decode to H20 GPUs, without length-based routing or load balancing. As shown in Table 6, the naive heterogeneous PD achieves only 1.16×1.16\times throughput over the homogeneous baseline, a 25% reduction compared to PrfaaS-PD. This degradation stems from the severe imbalance between prefill and decode throughput, and more fundamentally from treating heterogeneous prefill as a universal path rather than selectively offloading only the requests that benefit most from PrfaaS.
4.4 Summary
This case study demonstrates that for hybrid-architecture models, cross-datacenter KVCache becomes practical when it is paired with selective PrfaaS offloading rather than applied indiscriminately.
Regarding feasibility, the KVCache transfer of a hybrid model consumes only 13% of a 100 Gbps Ethernet link. This is well within reach of commodity Ethernet infrastructure and far below the bandwidth demands of RDMA interconnects, confirming the viability of cross-datacenter KVCache transfer.
Regarding effectiveness, the PrfaaS-PD configuration (32 H200 GPUs for PrfaaS, 64 H20 GPUs for local PD) achieves 54% higher throughput and 64% lower P90 TTFT over a 96-H20 homogeneous PD-only baseline; at equal cost, the throughput gain is approximately 15%. These gains stem from offloading compute-intensive long-context prefill to high-throughput PrfaaS accelerators. We note that H200 and H20 serve here as a representative hardware pair, not the sole viable combination. Cost-effective prefill-specialized chips can further reduce deployment cost in production.
Besides, the PrfaaS cluster is currently compute-bound with ample bandwidth headroom. Under larger-scale deployments or higher-bandwidth dedicated lines, the PrfaaS cluster can be further expanded to yield additional throughput gains. For example, in IDC-scale deployments with thousands of PrfaaS GPUs, the aggregate egress bandwidth required for KVCache transfer remains on the order of 1 Tbps, well within the capacity of modern datacenter fabrics, enabling further improvements in throughput and resource efficiency.
5 Discussion
Cross-datacenter KVCache extends PD disaggregation from a single tightly coupled cluster to loosely connected heterogeneous clusters. Its practicality depends on coordinated progress across model architecture, system design, and hardware. In this section, we discuss how these trends reinforce one another and what they imply for next-generation LLM serving systems.
KVCache-friendly model architecture.
As context windows continue to grow, KVCache increasingly dominates inference cost in storage and transfer. Architectural techniques such as MLA, sliding window attention, and linear attention have already shown that KVCache size can be reduced substantially without sacrificing model capability. Going forward, model co-design is likely to optimize not only FLOPs but also KVCache transfer volume. These improvements directly reduce the latency and bandwidth cost of cross-datacenter KVCache, expanding the range of deployments in which PrfaaS-PD is cost-effective.
KVCache compression and reuse.
Beyond architectural innovations, a growing body of work reduces LLM inference cost through KVCache compression and reuse at the algorithm or system level. Methods such as H2O [35] and KIVI [14] selectively evict or quantize KVCache entries to shrink memory footprints. CacheGen [13] applies conventional compression techniques to reduce KVCache transfer volume, while CacheBlend [34] and FusionRAG [30] enable reuse of approximately matched KVCache across requests. Together, these techniques complement KVCache-friendly model design by reducing effective memory pressure and network traffic, thereby making cross-datacenter KVCache more robust under production workloads.
Phase-specialized inference hardware.
The disaggregation between prefill and decode is also becoming visible in hardware design. Prefill is compute-intensive, whereas decode is dominated by memory bandwidth. Recent chip roadmaps are increasingly phase-specialized: NVIDIA Rubin CPX [19] emphasizes compute throughput for prefill, while chips such as the LPU [8] and Taalas HC1 [25] feature extremely high memory bandwidth for fast decode. Cross-datacenter KVCache fits this trend naturally. It removes the requirement that heterogeneous chips be deployed within the same tightly coupled network domain, allowing operators to size prefill and decode clusters independently and to deploy each phase on the hardware best suited to it.
6 Related Work
System optimization for online LLM inference has gradually shifted from monolithic single-cluster engines toward disaggregated, heterogeneity-aware, and KVCache-centric pipelines. On one hand, disaggregated serving splits each request into a compute-intensive prefill phase and a memory-bandwidth-intensive decode phase to reduce inter-phase interference and allow independent scaling. Splitwise [21] and DistServe [37] formulate PD disaggregation from cost/power and goodput perspectives, respectively, with corresponding deployment, scheduling, and placement strategies, showing that PD disaggregation can simultaneously improve throughput and reduce cost under appropriate SLO and hardware constraints. On the other hand, as cluster hardware and interconnects become increasingly heterogeneous, Helix [15], Hetis [17], and LLM-PQ [36] incorporate heterogeneous GPUs/networks and phase-level differences into the optimization space to achieve throughput or latency gains through phase-specialized hardware placement. Meanwhile, DynamoLLM [24] and FREESH [9] emphasize system-level resource reconfiguration and cross-domain scheduling from the perspective of energy, cost, and carbon efficiency while meeting serving SLOs. More critically, KVCache has evolved from per-request ephemeral state into a first-class system resource: Mooncake [22] introduces a global KVCache pool to improve cross-node and cross-request reuse; CacheBlend [34] and FusionRAG [30] significantly reduce TTFT through non-prefix KVCache fusion reuse; KIVI [14], KVQuant [10], and H2O [35] further shrink KVCache volume via quantization or importance-based eviction to improve long-context serviceability. However, no prior work jointly optimizes cross-datacenter prefill offloading, heterogeneous deployment, and bandwidth/cache-aware scheduling within a unified system. This paper approaches the problem from a cross-datacenter KVCache perspective, combining disaggregated inference with heterogeneous resource orchestration to build a low-cost, high-throughput serving system.
7 Conclusion
To address the practical deployment challenges of heterogeneous disaggregated inference, we propose the concept of cross-datacenter KVCache, extending disaggregated serving from single homogeneous clusters to cross-cluster heterogeneous deployments. On this basis, we design the PrfaaS-PD disaggregation architecture, which augments system serving throughput at low cost through heterogeneous PrfaaS clusters connected via commodity Ethernet. We envision that the cross-datacenter KVCache paradigm will co-evolve with next-generation models, hardware, and networks to enable highly efficient LLM serving at scale.
References
-
[1] D. Abts, J. Ross, J. Sparling, M. Wong-VanHaren, M. Baker, T. Hawkins, A. Bell, J. Thompson, T. Kahsai, G. Kimmell, et al. (2020) Think fast: a tensor streaming processor (tsp) for accelerating deep learning workloads. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pp. 145–158. Cited by: §1.
-
[2] S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao, et al. (2025) Gpt-oss-120b gpt-oss-20b model card. arXiv preprint arXiv:2508.10925. Cited by: §1, §2.2.
-
[3] I. AI (2026) Ring-2.5-1t. Note: https://github.com/inclusionAI/Ring-V2.5 Cited by: §1, §2.2, Table 1.
-
[4] J. Ainslie, J. Lee-Thorp, M. De Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai (2023) Gqa: training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 4895–4901. Cited by: Table 1.
-
[5] I. Beltagy, M. E. Peters, and A. Cohan (2020) Longformer: the long-document transformer. arXiv preprint arXiv:2004.05150. Cited by: §1, Table 1.
-
[6] R. Child, S. Gray, A. Radford, and I. Sutskever (2019) Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509. Cited by: §2.2.
-
[7] L. Corp. (2026) SGLang. Note: https://github.com/sgl-project/sglang Cited by: §1, Table 3, Table 3.
-
[8] Groq (2025) What is a language processing unit?. Note: https://groq.com/blog/the-groq-lpu-explained Cited by: §1, §5.
-
[9] X. He, Z. Fang, J. Lian, D. H. Tsang, B. Zhang, and Y. Chen (2025) FREESH: fair, resource-and energy-efficient scheduling for llm serving on heterogeneous gpus. arXiv preprint arXiv:2511.00807. Cited by: §6.
-
[10] C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y. S. Shao, K. Keutzer, and A. Gholami (2024) Kvquant: towards 10 million context length llm inference with kv cache quantization. Advances in Neural Information Processing Systems 37, pp. 1270–1303. Cited by: §6.
-
[11] A. Huang, A. Li, A. Kong, B. Wang, B. Jiao, B. Dong, B. Wang, B. Chen, B. Li, B. Ma, et al. (2026) Step 3.5 flash: open frontier-level intelligence with 11b active parameters. arXiv preprint arXiv:2602.10604. Cited by: §1, §2.2.
-
[12] A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, et al. (2024) Deepseek-v2: a strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434. Cited by: Table 1.
-
[13] Y. Liu, H. Li, Y. Cheng, S. Ray, Y. Huang, Q. Zhang, K. Du, J. Yao, S. Lu, G. Ananthanarayanan, et al. (2024) Cachegen: kv cache compression and streaming for fast large language model serving. In Proceedings of the ACM SIGCOMM 2024 Conference, pp. 38–56. Cited by: §5.
-
[14] Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V. Braverman, B. Chen, and X. Hu (2024) KIVI: a tuning-free asymmetric 2bit quantization for kv cache. In International Conference on Machine Learning, pp. 32332–32344. Cited by: §5, §6.
-
[15] Y. Mei, Y. Zhuang, X. Miao, J. Yang, Z. Jia, and R. Vinayak (2025) Helix: serving large language models over heterogeneous gpus and network via max-flow. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, pp. 586–602. Cited by: §6.
-
[16] Minimax (2026) MiniMax m2.5: built for real-world productivity. Note: https://www.minimax.io/news/minimax-m25 Cited by: Table 1.
-
[17] Z. Mo, J. Liao, H. Xu, Z. Zhou, and C. Xu (2025) Hetis: serving llms in heterogeneous gpu clusters with fine-grained and dynamic parallelism. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1710–1724. Cited by: §6.
-
[18] NVIDIA (2025) Nemotron 3 Nano: open, efficient mixture-of-experts hybrid Mamba-Transformer model for Agentic reasoning. Note: Technical report External Links: Link Cited by: §1, §2.2.
-
[19] NVIDIA (2025) NVIDIA rubin cpx accelerates inference performance and efficiency for 1m+ token context workloads. Note: https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/ Cited by: §1, §5.
-
[20] NVIDIA (2026) Dynamo. Note: https://github.com/ai-dynamo/dynamo Cited by: §1.
-
[21] P. Patel, E. Choukse, C. Zhang, A. Shah, Í. Goiri, S. Maleki, and R. Bianchini (2024) Splitwise: efficient generative llm inference using phase splitting. In 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pp. 118–132. Cited by: §6.
-
[22] R. Qin, Z. Li, W. He, J. Cui, H. Tang, F. Ren, T. Ma, S. Cai, Y. Zhang, M. Zhang, et al. (2024) Mooncake: a kvcache-centric disaggregated architecture for llm serving. ACM Transactions on Storage. Cited by: §1, §6.
-
[23] Z. Qin, W. Sun, D. Li, X. Shen, W. Sun, and Y. Zhong (2024) Lightning attention-2: a free lunch for handling unlimited sequence lengths in large language models. External Links: 2401.04658 Cited by: Table 1.
-
[24] J. Stojkovic, C. Zhang, Í. Goiri, J. Torrellas, and E. Choukse (2025) Dynamollm: designing llm inference clusters for performance and energy efficiency. In 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 1348–1362. Cited by: §6.
-
[25] Taalas (2025) Taalas hc1. Note: https://taalas.com/products Cited by: §5.
-
[26] K. Team, Y. Zhang, Z. Lin, X. Yao, J. Hu, F. Meng, C. Liu, X. Men, S. Yang, Z. Li, et al. (2025) Kimi linear: an expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692. Cited by: §1, §1, §2.2, Table 1, Table 1, §4.1.
-
[27] Q. Team (2026) Qwen3.5: towards native multimodal agents. Note: https://qwen.ai/blog?id=qwen3.5 Cited by: §1, §2.2, Table 1.
-
[28] vLLM Team at IBM (2025) Hybrid models as first-class citizens in vLLM. Note: https://pytorch.org/blog/hybrid-models-as-first-class-citizens-in-vllm/PyTorch Blog, November 2025 Cited by: §3.2.
-
[29] vLLM Team (2026) VLLM. Note: https://github.com/vllm-project/vllm Cited by: §1, Table 5, Table 5.
-
[30] J. Wang, W. Xie, M. Zhang, B. Zhang, J. Dong, Y. Zhu, C. Lin, J. Tang, Y. Han, Z. Ai, et al. (2026) From prefix cache to fusion rag cache: accelerating llm inference in retrieval-augmented generation. arXiv preprint arXiv:2601.12904. Cited by: §5, §6.
-
[31] B. Xiao, B. Xia, B. Yang, B. Gao, B. Shen, C. Zhang, C. He, C. Lou, F. Luo, G. Wang, et al. (2026) Mimo-v2-flash technical report. arXiv preprint arXiv:2601.02780. Cited by: §1, §2.2, Table 1.
-
[32] A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. (2025) Qwen3 technical report. arXiv preprint arXiv:2505.09388. Cited by: Table 1.
-
[33] S. Yang, J. Kautz, and A. Hatamizadeh (2025) Gated delta networks: improving mamba2 with delta rule. In International Conference on Learning Representations (ICLR), Cited by: Table 1.
-
[34] J. Yao, H. Li, Y. Liu, S. Ray, Y. Cheng, Q. Zhang, K. Du, S. Lu, and J. Jiang (2025) Cacheblend: fast large language model serving for rag with cached knowledge fusion. In Proceedings of the twentieth European conference on computer systems, pp. 94–109. Cited by: §5, §6.
-
[35] Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. Ré, C. Barrett, et al. (2023) H2o: heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems 36, pp. 34661–34710. Cited by: §5, §6.
-
[36] J. Zhao, B. Wan, C. Wu, Y. Peng, and H. Lin (2024) Llm-pq: serving llm on heterogeneous clusters with phase-aware partition and adaptive quantization. In Proceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pp. 460–462. Cited by: §6.
-
[37] Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang (2024) DistServe: disaggregating prefill and decoding for goodput-optimized large language model serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pp. 193–210. Cited by: §6.
Experimental support, please view the build logs for errors. Generated by [L
A
T
E
xml](https://math.nist.gov/~BMiller/LaTeXML/).
Instructions for reporting errors
We are continuing to improve HTML versions of papers, and your feedback helps enhance accessibility and mobile support. To report errors in the HTML that will help us improve conversion and rendering, choose any of the methods listed below:
- Click the "Report Issue" ( ) button, located in the page header.
Tip: You can select the relevant text first, to include it in your report.
Our team has already identified the following issues. We appreciate your time reviewing and reporting rendering errors we may not have found yet. Your efforts will help us improve the HTML versions for all readers, because disability should not be a barrier to accessing research. Thank you for your continued support in championing open access for all.
Have a free development cycle? Help support accessibility at arXiv! Our collaborators at LaTeXML maintain a list of packages that need conversion, and welcome developer contributions.