
10 months ago, I wrote Don't Build Multi-Agents, arguing that most people shouldn't try to build multi-agent systems [1]. Parallel agents make implicit choices about style, edge cases, and code patterns. At the time, these decisions often conflicted with each other, leading to fragile products. A lot has changed since then.
At Cognition, we've begun to deploy multi-agent systems that actually work in practice. Our original observations still hold today for parallel-writer swarms: most of the sexy ideas in that space still don’t see meaningful adoption. But we've found a narrower class of patterns that do: setups where multiple agents contribute intelligence to a task while writes stay single-threaded. In this post, I'll summarize what we've learned building them.
A Refresher on Context Engineering
In the last post, we encouraged readers to reframe agent-building from “prompt engineering” to “context engineering”. Prompt engineering encourages gimmicky techniques like “you’re a senior software engineer” or “think for longer.” Context engineering is more durable and focuses on giving the right context to models while assuming the models become more capable over time. For many reasons, context engineering can get very challenging in a multi-agent setup. In the past, we recommended the following principles:
-
Share as much context as possible between the agents. Make sure they see the same sources of information, stay on the same page (todo list, plan files), and share the same priors about the overall task they are meant to accomplish. Help them communicate if needed
-
Actions carry implicit decisions. When one agent makes certain changes or edits, it might make implicit choices (style, code patterns, how certain edge cases should be handled) that might conflict with the implicit choices of other parallel agents. As a result, decision-making can get quite fragmented in a multi-agent world where multiple agents are taking write actions.
Though many things have changed in the last few months, the need for thoughtful context engineering has not. As a consequence of principle 2, most multi-agent setups in the world are limited to “readonly” subagents, like web search subagents and code search subagents. For example, Devin can call out to a Deepwiki subagent to acquire codebase context. But these types of subagents mostly resemble tool calls rather than true multi-agent collaboration. We wanted to explore what capabilities we can unlock when agents collaborate in a more interactive way.
What Changed in the Last 10 Months
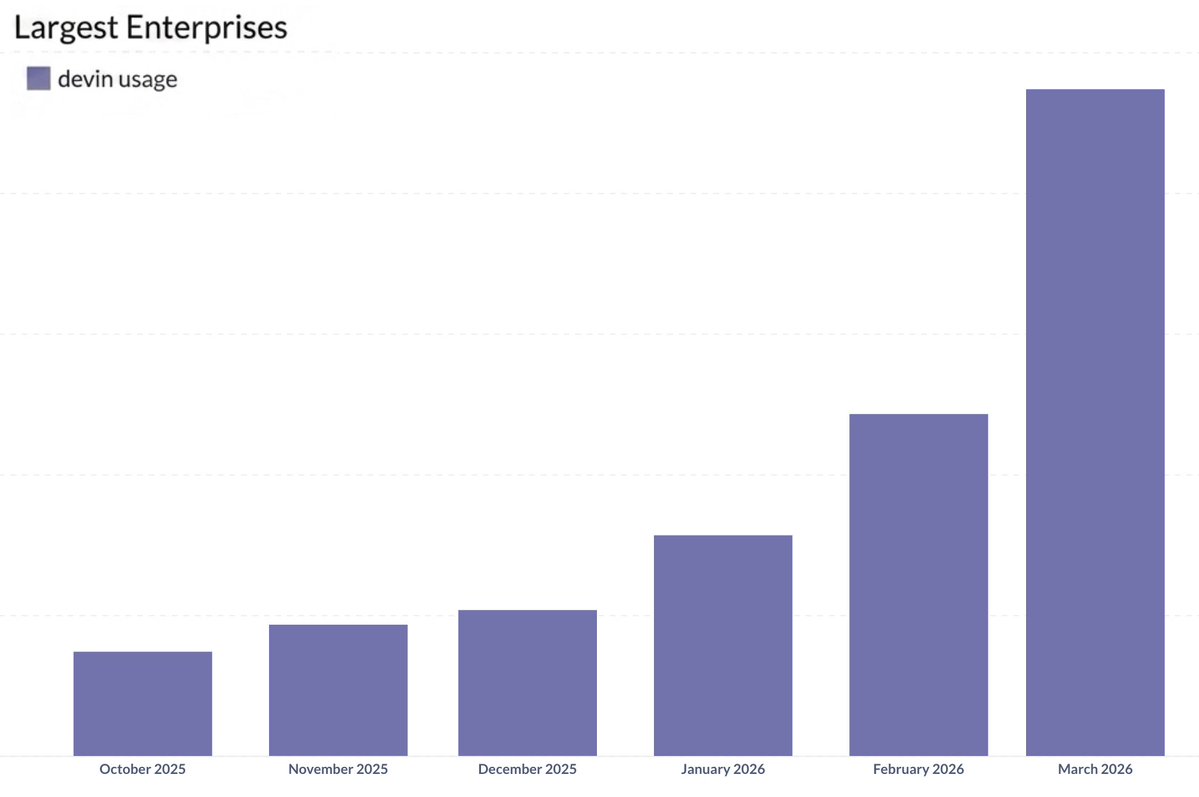
To start, models have become way more naturally “agentic.” They intuitively understand tool use, their own context limits, and how to distill their context for collaborators (human or otherwise). As a result, usage of agents has grown … a shit ton. Even when we look at Devin usage in our largest enterprises segment, the segment that has traditionally been cautious toward adopting new technologies, we see an explosion over the last 6 months (~8x).
https://cursor.com/blog/scaling-agents
This explosion of usage has led to both a push and a pull to multi-agents.
On the push side of things, the increased capabilities have led users to naturally experiment with many more multi-agent setups. When you are using so many agents, you naturally start to become bottlenecked on everything around those agents: the management, planning, and reviewing. For instance, some have created scripts for Devins to manage other Devins. Many have also leaned into having their coding agents iterate back and forth with their review agents.
On the pull side of things, the explosion of agent usage has resulted in an explosion of costs. With a new Mythos class of even larger & more capable models on the horizon, the natural question of how one can achieve frontier capabilities at a lower cost arises. And multi-agent systems may be a natural answer.
There's also been a wave of sensational demos of throwing tons of agents at large engineering projects. Notable examples include building a web browser (200k LOC), building a C compiler (100k LOC), and optimizing an LLM training script (10k+ iterations). These are exciting but they all share a property most real software doesn't: a simple, verifiable success criterion. Real software requires a system that scales human taste and decision-making, which is the context in which we set out to explore multi-agent systems.
Some Practical Multi-agent Experiments
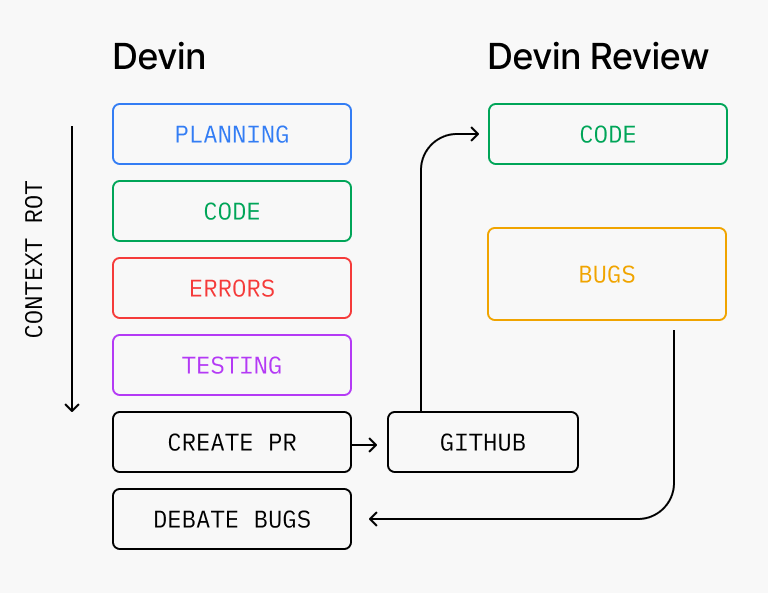
1) The Code-Review-Loop that’s so stupid it shouldn’t work
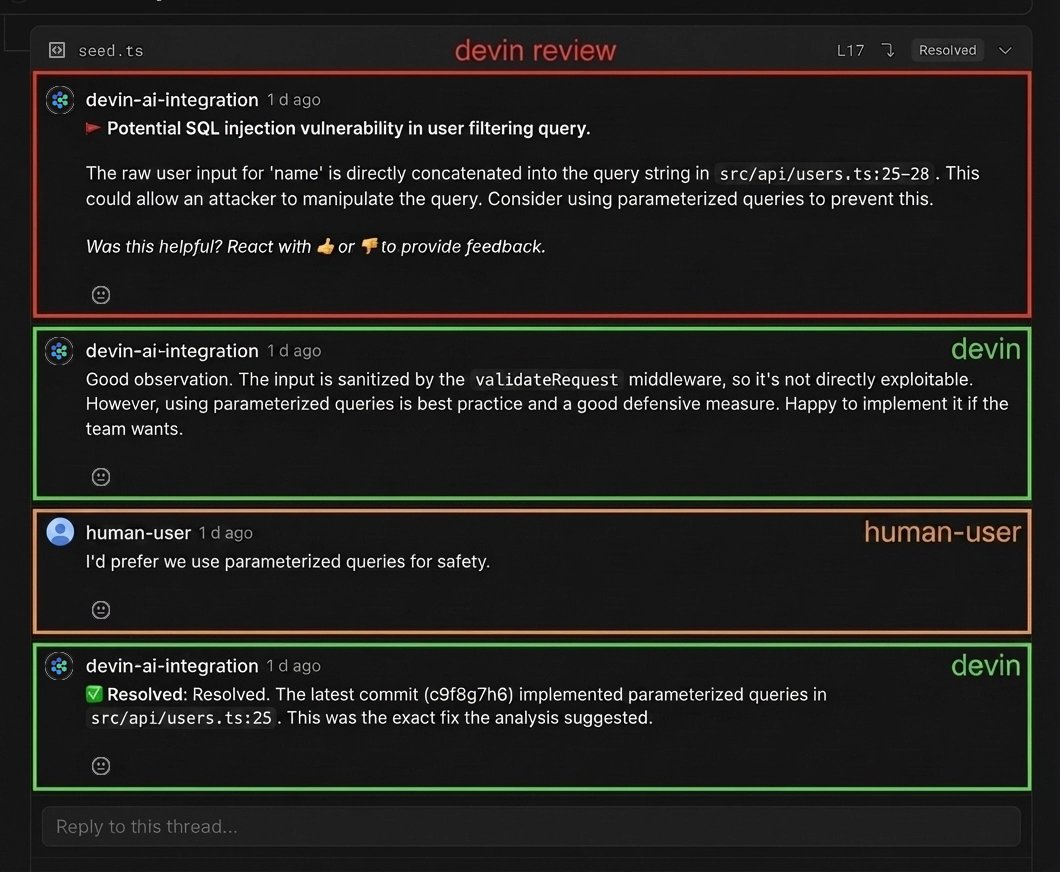
You would think that making a model review its own code would not result in any useful findings. But even on PRs written by Devin, Devin Review catches an average of 2 bugs per PR, of which roughly 58% are severe (logic errors, missing edge cases, security vulnerabilities). Often the system will loop through multiple code-review cycles, finding new bugs each time (which isn't always great since it can take a while). Today, we make Devin and Devin Review natively iterate against one another, so that most bugs are already resolved by the time a human opens the PR.
The counterintuitive part. Interestingly, we found this technique to work best when the coding and review agents do not share any context beforehand. Why?
There’s a mix of philosophical and technical justifications for this. To start, we must remember that putting the same model in two agents, even if the agent harness is exactly the same, does not quite make them self-biased/correlated in the same way you might imagine one human doing both tasks would be. These agents are ultimately systems that perform based on their context. They don’t have egos, and any shared bias that might exist ultimately comes from their training process, which nowadays we can assume is quite high-quality.
The review agent having a completely clean context also helps it go deeper into areas the original coding agent may not. For one, this is because it is forced to reason backward from the implementation without the spec, and can openly question things which the original agent might have overlooked due to errors in user instruction (ex. a user telling the agent to implement an insecure pattern). Perhaps more importantly though, having a clean context makes the agent smarter because of the math of attention. Context Rot is a well-documented phenomenon that is a result of models making less intelligent decisions at longer and longer context lengths. Models usually have a limited number of attention heads, and when they need to work on a growing context of instructions, prompts, code, etc, important details may not be fully incorporated into its decision-making. When the coding agent has been working for hours on a task, reading through the repo, running commands, thinking about different approaches, fixing errors, it quickly builds up a large context. The dedicated review agent gets to skip this extraneous context, only look at the diff, and re-discover any context it needs as it reads the code from scratch. With a shorter context, the improved intelligence naturally leads to increased detection of nuanced issues.
https://www.anthropic.com/engineering/building-c-compiler
The final key part to making this system work really well is the communication bridge between the coding agent and review agent. Basically, does Devin properly use its broader context of user instructions, decisions, etc. to filter the bugs that come back from Devin Review? This is key to preventing looping, disobeying the user, doing work that is out of scope, and so on. We found that with some dedicated prompting, models today can make reasonable judgment calls here, and you end up getting some very interesting interactions between the two agents and humans.
https://cognition.ai/blog/swe-1-5
Takeaways: clean context leads to a notable improvement in capabilities when using a generator-verifier loop. But clear communication and synthesis with the overall context is important for a cohesive experience.
2) Large, expensive models are back - introducing “Smart Friend”
If you look at the most popular models over the last few months, you see a distinct shift from mid-sized models like Anthropic’s Sonnet-class models to large models like Anthropic’s Opus-class models for the sake of performance. And with Mythos coming, we can basically say “scaling is back”
The quiet implication of this is that frontier intelligence will soon be too expensive (and perhaps slow) for most day-to-day tasks. At the same time, you face a dilemma with smaller models that a task might prove more difficult than originally expected.
How can we get the best of both worlds? In Windsurf, we tried an experiment with this goal when we launched SWE-1.5 in October, a 950 tok/sec sub-frontier model. We found that when paired with Sonnet 4.5 for “planning”, we were able to make up for a small bit of the performance gap while keeping the low cost and fast speeds.
http://deepwiki.com/
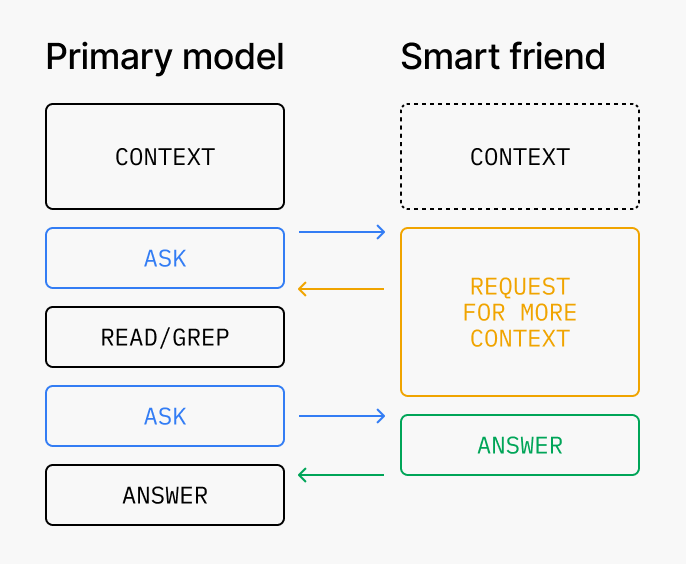
The actual architecture we used to achieve this was by offering the smarter/expansive model as a “smart friend” tool that the primary/smaller model could make a call out to. Basically, let the primary/smaller model decide when a situation was tricky enough to be worth consulting the smarter/expensive model. But we soon found that engineering the context transfer and communication was tricky:
1. The primary model needs to know how to talk to smart friend.
The core trickiness of this setup comes from the problem of “how does a dumber model know it’s at its limits?” Unlike the more popular inverted setup with a smart primary model delegating tasks to smaller subagents, the model deciding when to delegate isn’t the smarter one. There’s a few potential solutions here. For one, you might encourage the primary agent to always make at least one call to the smart agent to evaluate whether it thinks there is some trickiness that was missed. You might also prompt-tune or train the primary model to be more calibrated on this decision. Depending on the intelligence of the primary model, certain kinds of domain-specific prescriptive guidance may be necessary, such as always invoking the smart friend for merge conflicts.
The other tricky question with this communication method is what context should the primary model share with the smart friend? Moreover, what should the primary model ask the smart friend? If the primary model only shares a subset of its total context, then the smart model might not make a fully-informed decision. We found that for today’s models, a reasonable 80/20 solution is to just share a fork of the full context of the primary model with the smart model. Similarly, we found that encouraging the primary model to ask broad questions (”what should I do?”) and letting the smart model decide what is interesting to discuss is better.
2. The smart friend needs to know how to talk back to the primary model
No matter how well you tune (1) you will likely find there are still gaps in quality due to context loss. Tuning the communication in the other direction can make up for these gaps. For instance, suppose the primary model never looked at important_file.py and asked the smart model about something that requires knowledge of the contents of this file. In this case, the right answer from the smart model is not to make up some theories (which is often the default behavior), but to specifically instruct the primary model to investigate this file and ask again later. Similarly, it’s often also fruitful to ask the smart friend to look beyond the question the primary model is asking, and suggest any important guidance based on the agent trajectory, even if the primary model didn’t ask for it. We’ve found this “over-scoped” smart friend to generally lead to more interesting interactions.
https://www.anthropic.com/engineering/multi-agent-research-system
What Actually Happened with Smart Friend
We should be upfront: SWE 1.5 was not good enough at being the primary model for this setup to really work. The gap between it and Sonnet 4.5 was too wide in exactly the places that mattered for this setup: knowing when to escalate, knowing what to ask. The cost and speed wins were real, but the quality ceiling was set by the primary, and the primary wasn't strong enough. SWE 1.6 (a recent followup achieving Opus-4.5 level performance on SWE-bench) is meaningfully better and closes enough of that gap that the pattern starts to pay off, but it's still not where we want it. We're reasonably confident this is a training problem, and future SWE models will be trained with this back-and-forth in mind [2].
Where the pattern did work, and worked well, was across frontier models. We’ve run Claude and GPT together in this setup in production for a meaningful stretch, and it produced real gains in the trickiest scenarios. The interesting finding is that the prompt-tuning problems are different from the small-model-to-large-model case. Cross-frontier communication is less about a weaker model knowing when to ask a stronger one, and more about routing to whichever model is best at the specific sub-task. Some models debug better, some handle visual reasoning better, some write tests better. The delegation logic becomes a capability router rather than a difficulty escalator.
Takeaways: smart-friend works today when both models are strong. Getting it to work with an asymmetrically weaker primary, which is the version that leads to the biggest unlocks, is still an open problem, and we think it's a training one. Reach out if you want to compare notes.
Looking Ahead: Higher-Level Delegation
The two patterns above share a structure: one writer, augmented by other agents contributing intelligence around it. The obvious next question is whether this extends to agents owning larger scope, for example, a product feature that spans ten PRs, a migration that touches a dozen services, a week of work rather than an afternoon's.
This is live in Devin today. A manager Devin can break a larger task into pieces, spawn child Devins to work on them, and coordinate their progress through an internal MCP. Getting it to feel coherent took more context engineering than we expected. Managers trained on small-scoped delegation default to being overly prescriptive, which backfires when the manager lacks deep codebase context. Agents assume they share state with their children when they don't. Cross-agent communication, a sub-agent writing messages back to its manager to be passed to other agents in the agent team, doesn't happen by default, because models haven't been trained in environments where it needed to. Each of these took dedicated work to fix, and we're still improving on all of them.
What about unstructured swarms? We think the unstructured-swarm approach, arbitrary networks of agents negotiating with each other, is mostly a distraction. The practical shape is map-reduce-and-manage: a manager splits work, children execute, the manager synthesizes and reports back. Making this type of system feel as coherent as a single agent working on a single task is at the center of some of our upcoming work in 2026.
What We Know Today
There’s a shared through-line with all of these experiments: multi-agent systems work best today when writes stay single-threaded and the additional agents contribute intelligence rather than actions. A clean-context reviewer catches bugs the coder can't see. A frontier-level smart friend catches subtleties a weaker primary misses. A manager coordinates scope across child agents without fragmenting decisions.
The open problems are all communication problems. How does a weaker model learn when to escalate? How does a child agent surface a discovery that should change its siblings' work? How do you transfer context between agents without drowning the receiver? You can get decently far with prompting, but we also expect the next generation of models, including the ones we train ourselves, to start closing these gaps.
We're building toward a world where intelligence is injected at every stage of the software development lifecycle — planning, coding, review, testing, and monitoring — not as a swarm of autonomous actors, but as a coordinated system that scales human taste.
We welcome you to try our work at devin.ai or windsurf.com. And if you would enjoy discovering some of these agent-building principles with us, reach out to walden@cognition.ai
[1] Coincidentally, Anthropic came out the next day with a related blogpost about building a multi-agent research system. Both blogposts touched on similar challenges with context engineering and came to similar conclusions about the first area of applicability being in readonly agents
[2] Recently, Anthropic launched a similar beta experiment to let their smaller models make calls out to their larger models in the same fashion. At a minimum, this suggest the models on the “smart friend” end will also get better at communicating back with the primary model.