多智能体协同模式:五种方法及其适用时机
五种多智能体协同模式、它们的权衡,以及何时该从一种演进到另一种。
-
分类
-
产品
Claude Platform
-
日期
2026 年 4 月 10 日
-
阅读时长
5
分钟
-
分享
https://claude.com/blog/multi-agent-coordination-patterns
在之前的一篇文章里,我们探讨了多智能体系统何时有价值,以及何时单个智能体才是更好的选择。这篇文章写给那些已经做出这个判断、现在需要决定哪种协同模式更适合自己问题的团队。
我们见过不少团队按听起来是否高级来选模式,而不是按问题本身是否匹配。我们的建议是,先从能奏效的最简单模式开始,观察它在哪些地方吃力,再从那里演进。这篇文章会拆解五种模式的运作机制与局限:
-
生成器-验证器,适合质量要求高且评估标准明确的输出
-
协调者-子智能体,适合任务拆解清晰、子任务边界明确的场景
-
智能体团队,适合可并行、彼此独立、持续时间较长的子任务
-
消息总线,适合事件驱动的流程,以及不断扩大的智能体生态
-
共享状态,适合协作型工作,智能体需要建立在彼此发现之上继续推进
模式一:生成器-验证器
这是最简单的多智能体模式,也是部署最广的模式之一。我们在上一篇文章中把它称为验证子智能体模式,而这里使用更宽泛的生成器-验证器框架,因为生成器不一定非得是协调者。
它如何运作
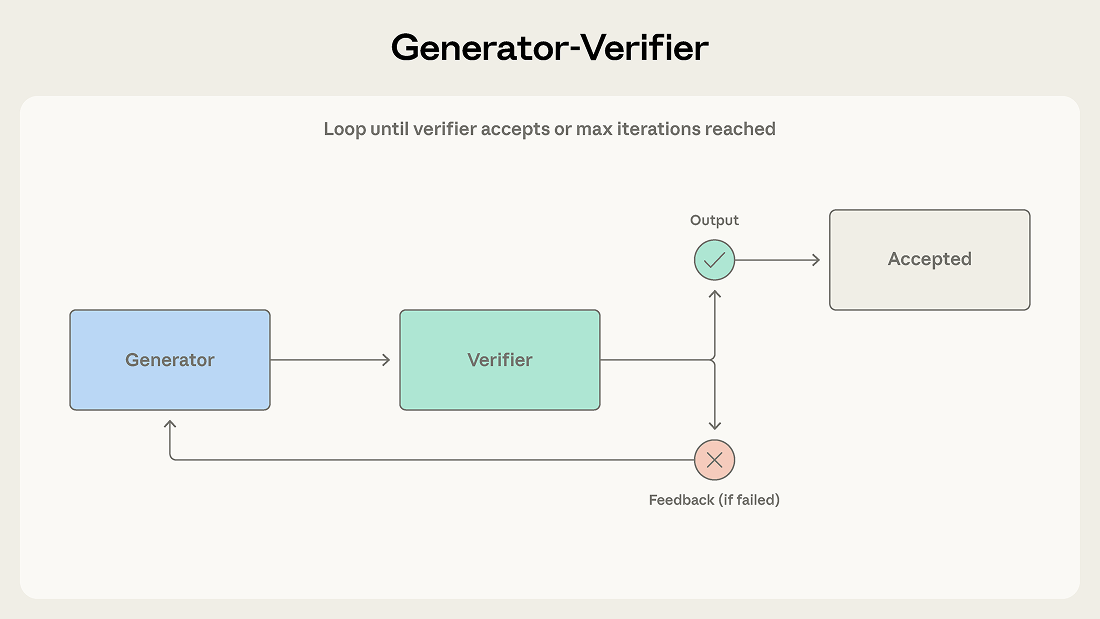
生成器接收任务并产出初始结果,再把结果交给验证器评估。验证器检查输出是否满足所需标准,然后要么接受其为最终结果,要么带着反馈将其退回。如果被退回,这些反馈会回到生成器,生成器据此给出修订版本。这个循环会持续,直到验证器接受结果,或者达到最大迭代次数。
它适合什么场景
比如一个支持系统,需要为客户工单生成邮件回复。生成器会结合产品文档和工单上下文生成初稿。验证器会对照知识库检查准确性,根据品牌规范评估语气,并确认回复是否覆盖了用户提出的每个问题。未通过的检查会带着明确指出问题所在的反馈返回给生成器,比如把某个功能错误地归到了错误的价格档,或者漏答了工单中的某个问题。
当输出质量至关重要,并且评估标准可以明确写出来时,就适合用这种模式。它非常适合代码生成,一个智能体写代码,另一个智能体编写并运行测试;也适用于事实核查、基于评分标准的打分、合规验证,以及所有错误输出代价高于多跑一轮生成的场景。
它会卡在哪里
验证器的能力只取决于它的标准有多好。一个只被要求检查输出是不是好、却没有更多标准的验证器,最后只会给生成器的输出盖章放行。团队最常见的失败方式,就是实现了这个循环,却没有定义清楚验证到底意味着什么。这样会制造出一种质量控制的幻觉,却没有真正的质量控制。我们在上一篇文章里讨论过这种过早获胜的问题。
这种模式还默认生成和验证是可以分开的两种能力。如果评估一个创意方案和生成一个创意方案一样难,验证器就未必能可靠地抓住问题。
最后,迭代循环也可能卡死。如果生成器始终无法解决验证器提出的反馈,系统就会在来回往复中打转,无法收敛。设置最大迭代次数,再配一个兜底策略,比如升级给人工处理,或者带着说明返回当前最好的结果,就能避免它变成无限循环。
模式二:协调者-子智能体
这种模式的核心是层级结构。一个智能体担任团队负责人,负责规划工作、分派任务、整合结果。子智能体负责具体职责,并回传结果。
它如何运作
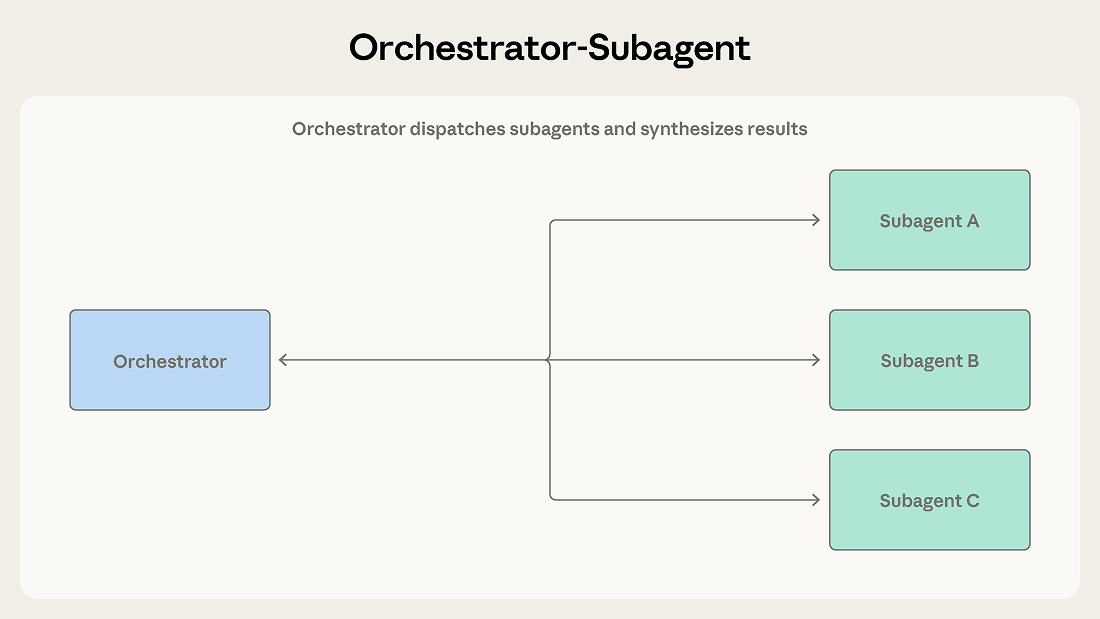
一个主导智能体接收任务,并决定如何推进。它可以亲自处理部分子任务,同时把其他子任务分发给子智能体。子智能体完成工作并返回结果,协调者再将这些结果整合成最终输出。
Claude Code 就使用了这种模式。主智能体会自己写代码、编辑文件、运行命令;当它需要搜索大型代码库或调查彼此独立的问题时,就会在后台派出子智能体,这样主线工作可以继续推进,同时结果陆续返回。每个子智能体都在自己的上下文窗口里运行,并回传提炼后的发现。这样协调者的上下文就能始终聚焦在主任务上,而探索工作则能并行展开。
它适合什么场景
比如一个自动化代码审查系统。每当有一个拉取请求进来,系统需要检查安全漏洞、验证测试覆盖率、评估代码风格,还要判断架构一致性。每一项检查都彼此不同,需要不同的上下文,也会产出清晰的结果。这时协调者可以把每一项检查分派给专门的子智能体,收集结果后,再整合成一份统一的审查意见。
当任务拆解足够清晰,且子任务之间相互依赖很少时,就适合用这种模式。协调者能维持对整体目标的连贯视角,而子智能体则专注于各自的职责。
它会卡在哪里
协调者会变成信息瓶颈。当一个子智能体发现了与另一个子智能体相关的内容时,这条信息必须先回到协调者,再由协调者转发。如果负责安全的子智能体发现了一个会影响架构分析的认证缺陷,协调者就必须识别出这种依赖关系,并把信息准确传过去。经过几次这样的中转之后,关键细节往往就丢了,或者被压缩得太狠。
顺序执行也会限制吞吐量。除非显式并行化,否则子智能体会一个接一个运行,这意味着系统承担了多智能体的 token 成本,却没有拿到速度上的收益。
模式三:智能体团队
当工作可以拆成多个可并行推进、并且能在较长时间内彼此独立完成的子任务时,协调者-子智能体模式就会显得过于束缚。
它如何运作
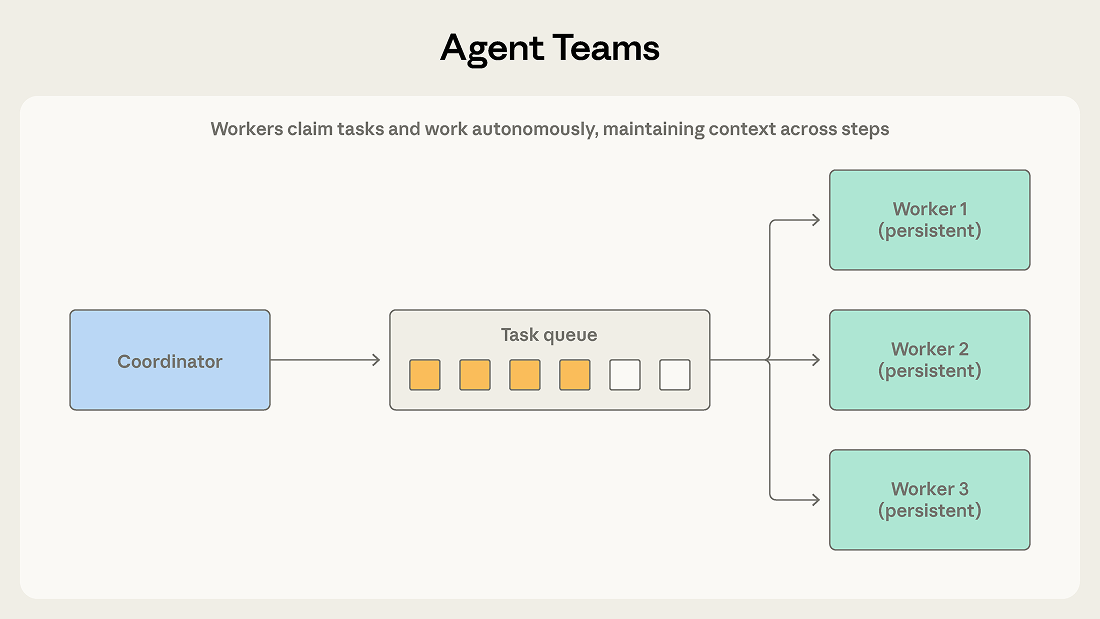
一个协调器会启动多个工作智能体,把它们作为独立进程运行。团队成员从共享队列中领取任务,围绕任务自主地跨多步推进,并在完成时发出信号。
它和协调者-子智能体的区别,在于工作智能体的持续性。协调者会为一个边界明确的子任务临时拉起一个子智能体,子智能体返回结果后就结束。团队成员则会在多次任务之间一直存活,逐步积累上下文和领域专长,时间越久,表现越好。协调器负责分配工作和收集结果,但不会在每次任务之间重置这些工作智能体。
它适合什么场景
比如把一个大型代码库从一个框架迁移到另一个框架。每个服务都可以独立迁移,有自己的依赖、测试套件和部署配置。协调器可以把每个服务分配给一个团队成员,每个成员自主完成迁移过程,包括更新依赖、修改代码、修复测试、做验证。协调器收集完成的迁移结果后,再对整个系统跑集成测试。
当子任务彼此独立,并且能从持续的多步工作中受益时,就适合用这种模式。每个团队成员都能逐渐建立起自己领域内的上下文,而不是每次派发任务都从零开始。
它会卡在哪里
独立性是最关键的前提。不同于协调者-子智能体模式中协调者可以在子智能体之间做信息中介,这里的团队成员是自主运作的,没法轻易共享中间发现。如果一个成员的工作会影响另一个成员,而双方都不知道,最终输出就可能发生冲突。
完成状态也更难判断。因为各个成员会在不同的时长内自主推进,协调器必须能处理部分完成的情况,有的成员两分钟就做完了,另一个可能要二十分钟。
共享资源会让这两个问题更严重。当多个团队成员操作同一个代码库、数据库或文件系统时,两个成员可能会编辑同一个文件,或者做出彼此不兼容的修改。这种模式需要非常仔细的任务切分,以及冲突解决机制。
模式四:消息总线
随着智能体数量增加、交互模式变得更复杂,直接协同就会越来越难管。消息总线通过引入一层共享通信层,让智能体以发布和订阅事件的方式协作。
它如何运作
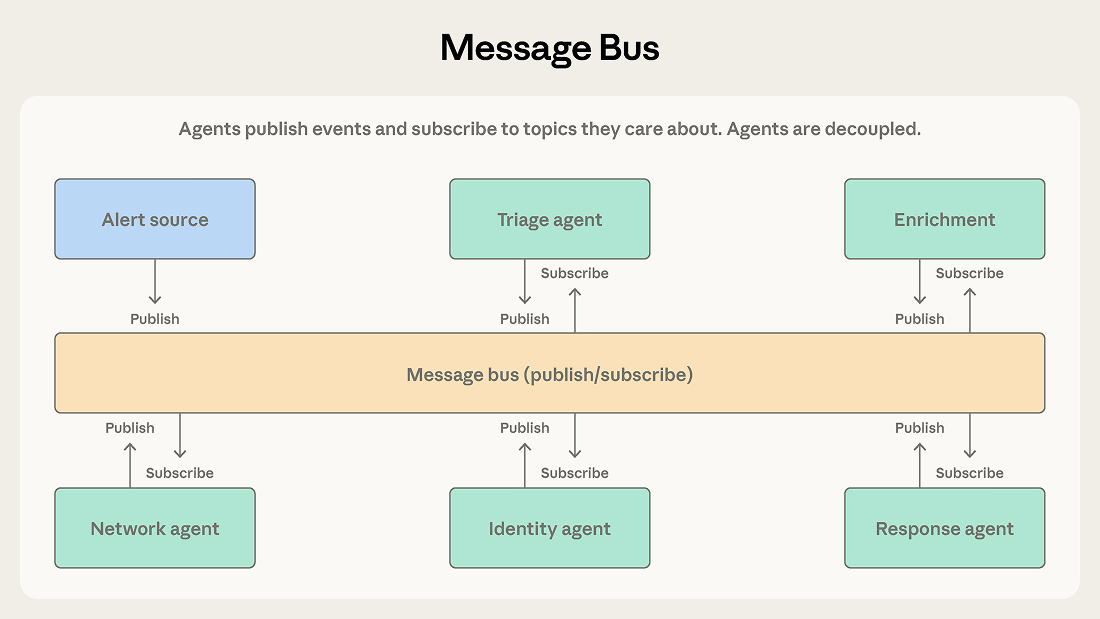
智能体通过两个基础动作进行交互,发布和订阅。智能体订阅自己关心的主题,路由器负责把匹配的消息送过去。拥有新能力的新智能体可以开始接收相关工作,而不需要重接现有连接。
它适合什么场景
一个安全运营自动化系统,就是这种模式大显身手的地方。告警会从多个来源进入,分诊智能体会按严重等级和类型做分类,把高严重性的网络告警分发给网络调查智能体,把和凭证相关的告警交给身份分析智能体。每个调查智能体都可能发布补充信息请求,再由上下文采集智能体去满足这些请求。最终,调查发现会流向响应协调智能体,由它决定该采取什么动作。
这个流水线很适合消息总线,因为事件会从一个阶段流向下一个阶段,团队可以随着威胁类别的变化不断加入新的智能体类型,而且各个智能体可以独立开发和部署。
当流程是由事件推动,而不是由预先写死的顺序决定,并且智能体生态还会继续扩张时,就适合使用这种模式。
它会卡在哪里
事件驱动通信的灵活性,会让追踪问题变得更难。当一个告警触发了跨五个智能体的一连串事件后,想弄清到底发生了什么,就需要非常仔细的日志和关联分析。相比沿着协调者的顺序决策往下追,调试会更难。
路由准确性也至关重要。如果路由器把一个事件错分了,或者直接丢了,系统就会静默失败,什么也没处理,但又不会崩溃。基于大语言模型的路由器带来了语义上的灵活性,但也会带来它自己的一套失败模式。
模式五:共享状态
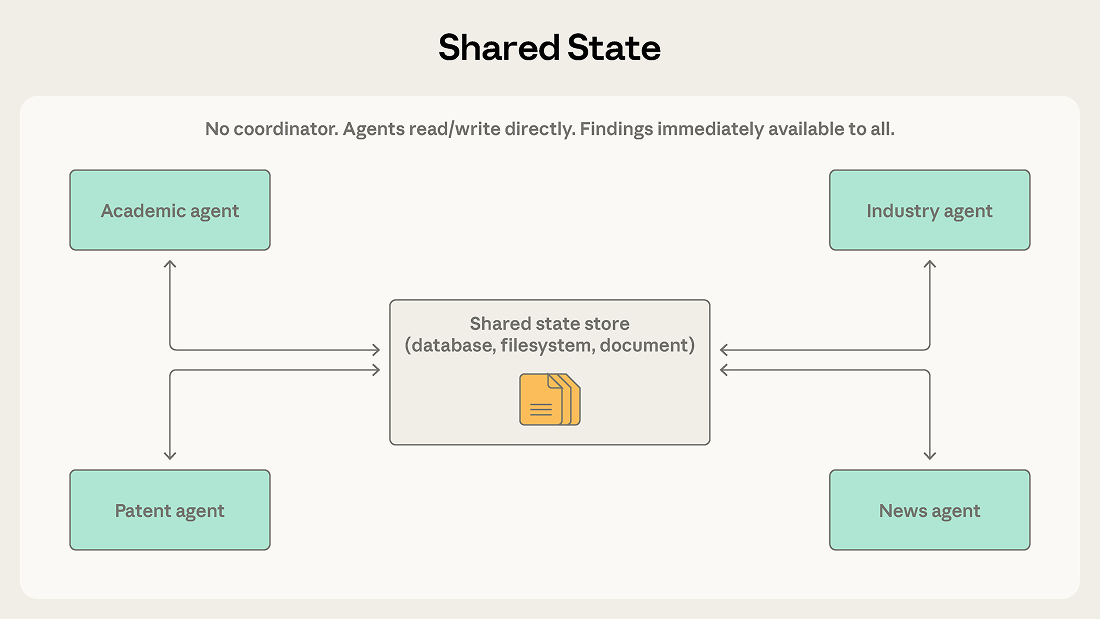
前面几种模式中的协调者、团队负责人和消息路由器,都会在中心位置管理信息流。共享状态把这个中间层拿掉,让智能体通过一个所有人都能直接读写的持久化存储来协同。
它如何运作
智能体自主运作,直接读写共享数据库、文件系统或文档。这里没有中心协调者。智能体会查看存储中与自己相关的信息,根据看到的内容行动,再把自己的发现写回去。工作通常始于一个初始化步骤,把某个问题或数据集写入存储;结束则由某个终止条件决定,比如时间上限、收敛阈值,或者由某个指定的智能体判断存储里已经有了足够好的答案。
它适合什么场景
比如一个研究综合系统,需要多个智能体分别调查一个复杂问题的不同方面。一个查学术文献,一个分析行业报告,一个研究专利申请,第四个盯新闻报道。每个智能体的发现都可能影响其他智能体的调查。查学术文献的智能体,可能会发现一位关键研究者,而这位研究者所在的公司正是行业分析智能体应该重点关注的对象。
在共享状态模式下,这些发现会直接写入共享存储。行业分析智能体可以立刻看到学术智能体的新发现,不需要等协调者来转发信息。智能体会在彼此工作的基础上继续推进,而共享存储会逐步变成一个不断演化的知识库。
共享状态还去掉了协调者这个单点故障。一旦某个智能体停止,其他智能体仍然可以继续读写。在协调者模式或消息总线模式里,协调器或路由器一旦故障,整个系统都会停摆。
它会卡在哪里
没有显式协调时,智能体可能重复劳动,或者走向彼此矛盾的方向。两个智能体可能会独立调查同一条线索。智能体之间的交互会共同塑造系统行为,而不是由上而下设计,这会让结果更难预测。
更麻烦的失败模式是反应式循环。比如智能体 A 写入一条发现,智能体 B 读到后写了跟进内容,智能体 A 又看到了这条跟进并继续回应。系统就会不断消耗 token,做的却是无法收敛的工作。重复劳动和并发写入,都有相对成熟的工程解决方式,比如加锁、版本控制、分区。反应式循环是行为层面的问题,需要被当作一等公民来处理,必须有明确的终止条件,比如时间预算、收敛阈值,也就是连续 N 个周期没有新发现,或者指定一个智能体来负责判断存储中是否已经有了足够充分的答案。那些把终止条件当成事后补丁的系统,往往会无限循环,或者在某个智能体上下文塞满后随意停下。
如何选择,并在模式之间演进
正确的模式取决于系统结构上的几个关键问题。上一篇文章里,我们主张以上下文为中心来拆解任务,也就是按每个智能体需要什么上下文来划分工作,而不是按它做什么类型的工作来划分。这个原则在这里同样适用。不同模式的差别,主要就在于它们如何管理上下文边界,以及信息如何流动。
协调者-子智能体 vs. 智能体团队
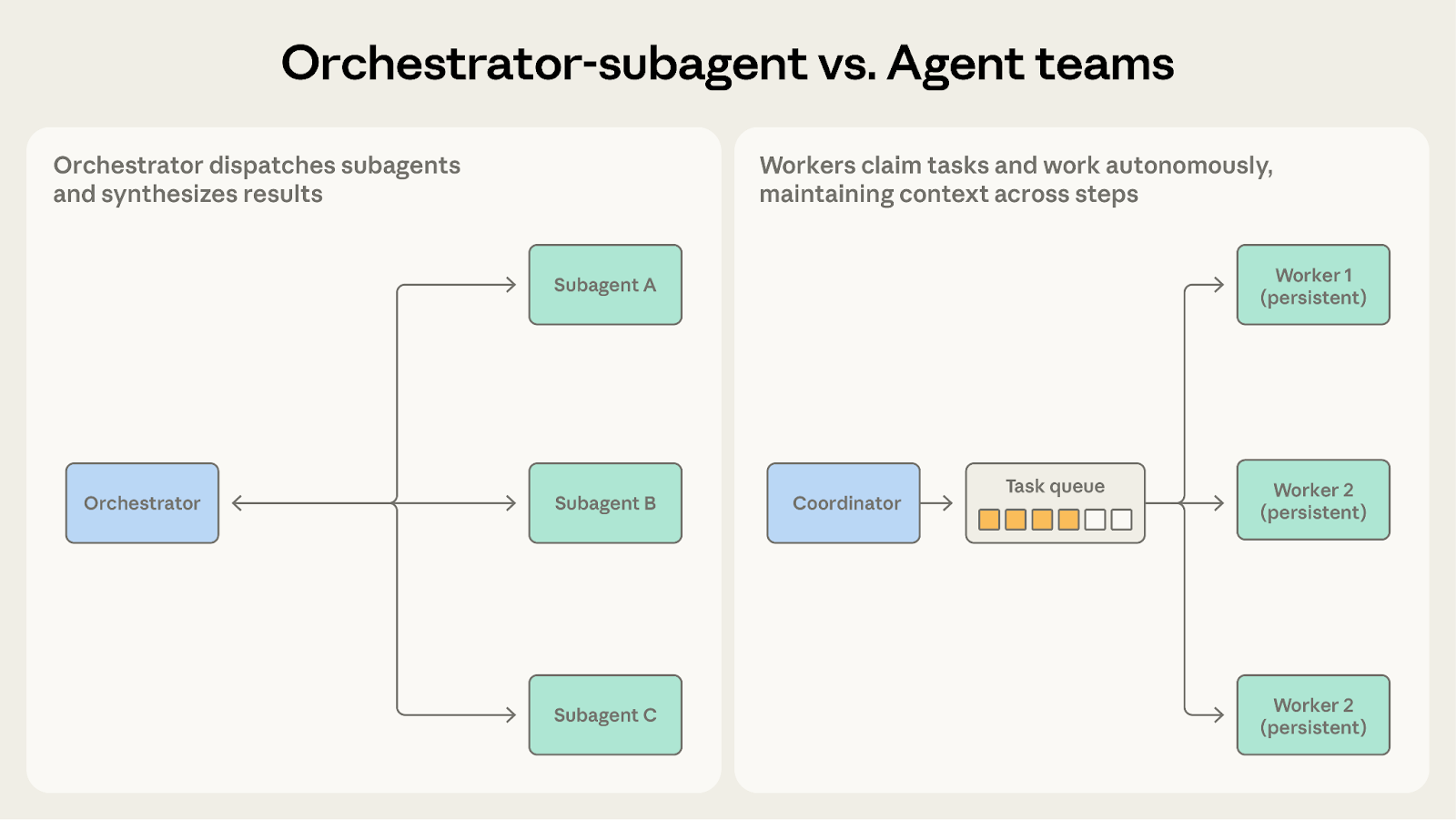
这两种模式都涉及一个协调者向其他智能体分派工作。关键问题在于,工作者需要维持上下文多久。
-
当子任务较短、聚焦明确,并且能产出清晰结果时,选择协调者-子智能体。代码审查系统就很适合,因为每项检查都会完成分析、生成报告,并在一次边界明确的调用中返回。子智能体不需要跨多个周期保留上下文。
-
当子任务会从持续的多步工作中获益时,选择智能体团队。代码库迁移就很适合,因为每个团队成员都会逐步真正熟悉自己负责的服务,包括依赖图、测试模式和部署配置。这种积累出来的上下文,会以单次派发无法复制的方式提升表现。
当子智能体需要跨多次调用保留状态时,智能体团队会更合适。
协调者-子智能体 vs. 消息总线
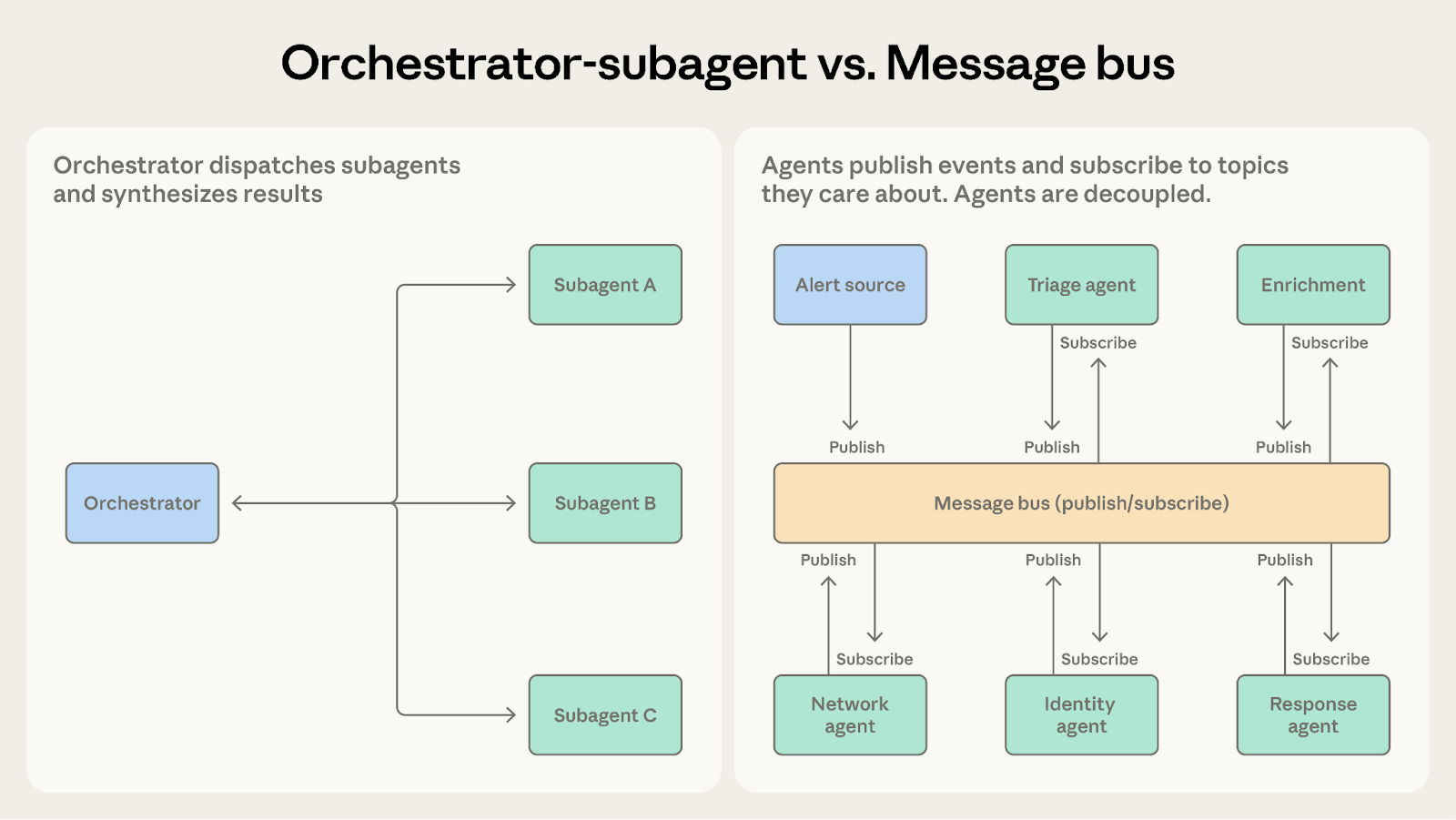
这两种模式都能处理多步工作流。关键问题在于,工作流结构是否可预测。
-
当步骤顺序事先已知时,选择协调者-子智能体。代码审查系统遵循一条固定流水线,接收 PR,运行检查,整合结果。
-
当工作流由事件推动,并且会随着新发现而变化时,选择消息总线。安全运营系统无法预先知道会收到什么告警,也无法预先知道这些告警会需要怎样的调查路径。新的告警类型还可能不断出现,带来新的处理需求。消息总线通过把事件路由给有能力处理的智能体,而不是沿着预设顺序推进,来容纳这种变化。
当协调者里为了处理不断扩展的情况而塞进越来越多条件分支时,消息总线会让这种路由逻辑变得更明确,也更容易扩展。
智能体团队 vs. 共享状态
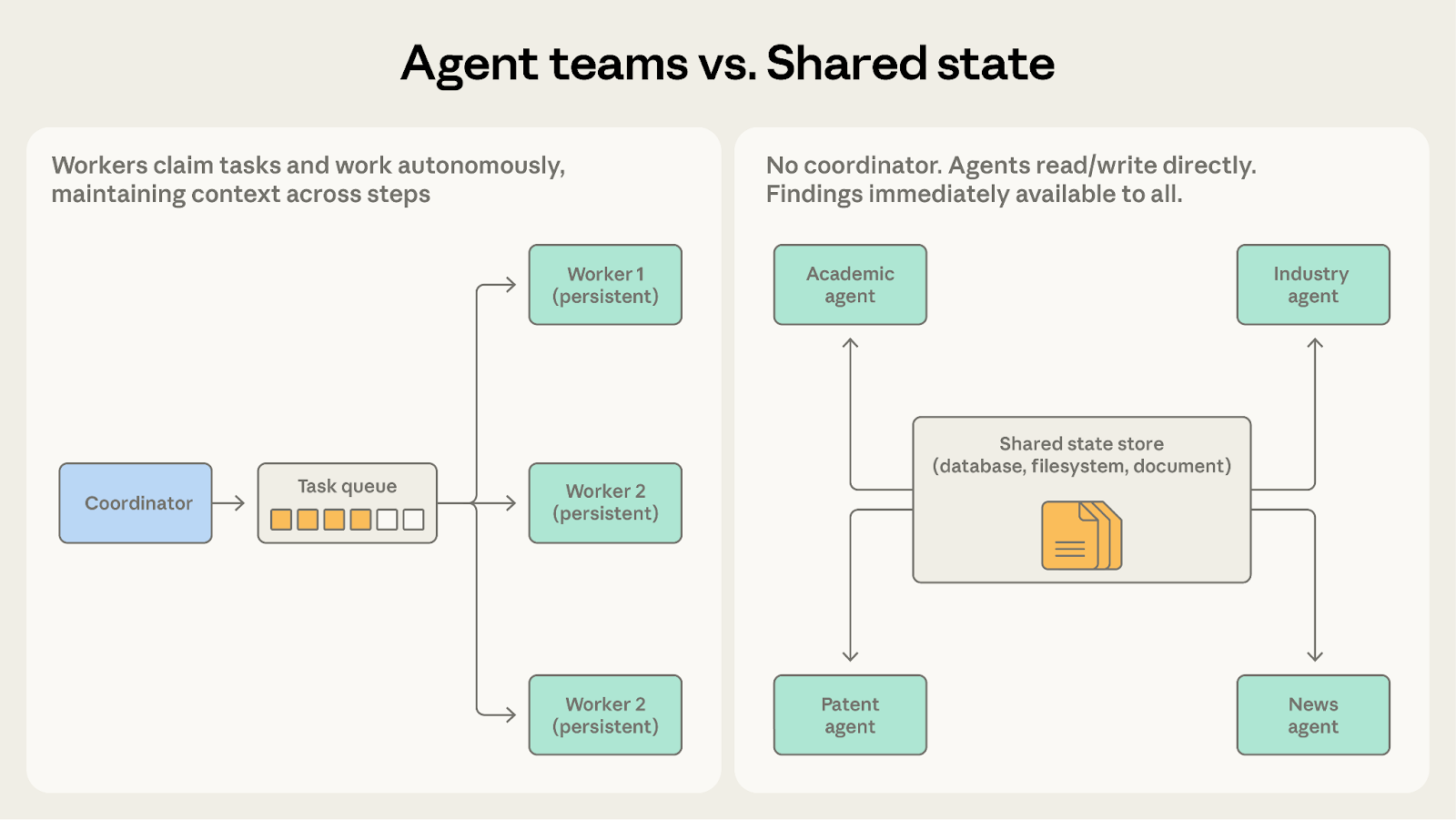
这两种模式都让智能体自主工作。关键问题在于,智能体是否需要彼此的发现。
-
当智能体处理的是彼此独立、不互相影响的分区任务时,选择智能体团队。代码库迁移就适合这种模式,因为每个团队成员处理自己的服务,协调器在最后把结果合并起来。
-
当智能体的工作本质上是协作性的,并且彼此的发现需要实时流动时,选择共享状态。研究综合系统更适合这里,因为学术智能体发现一位关键研究者后,这条发现会立刻影响行业智能体接下来的调查。
一旦团队成员需要彼此沟通,而不只是共享最终结果,共享状态会更自然。
消息总线 vs. 共享状态
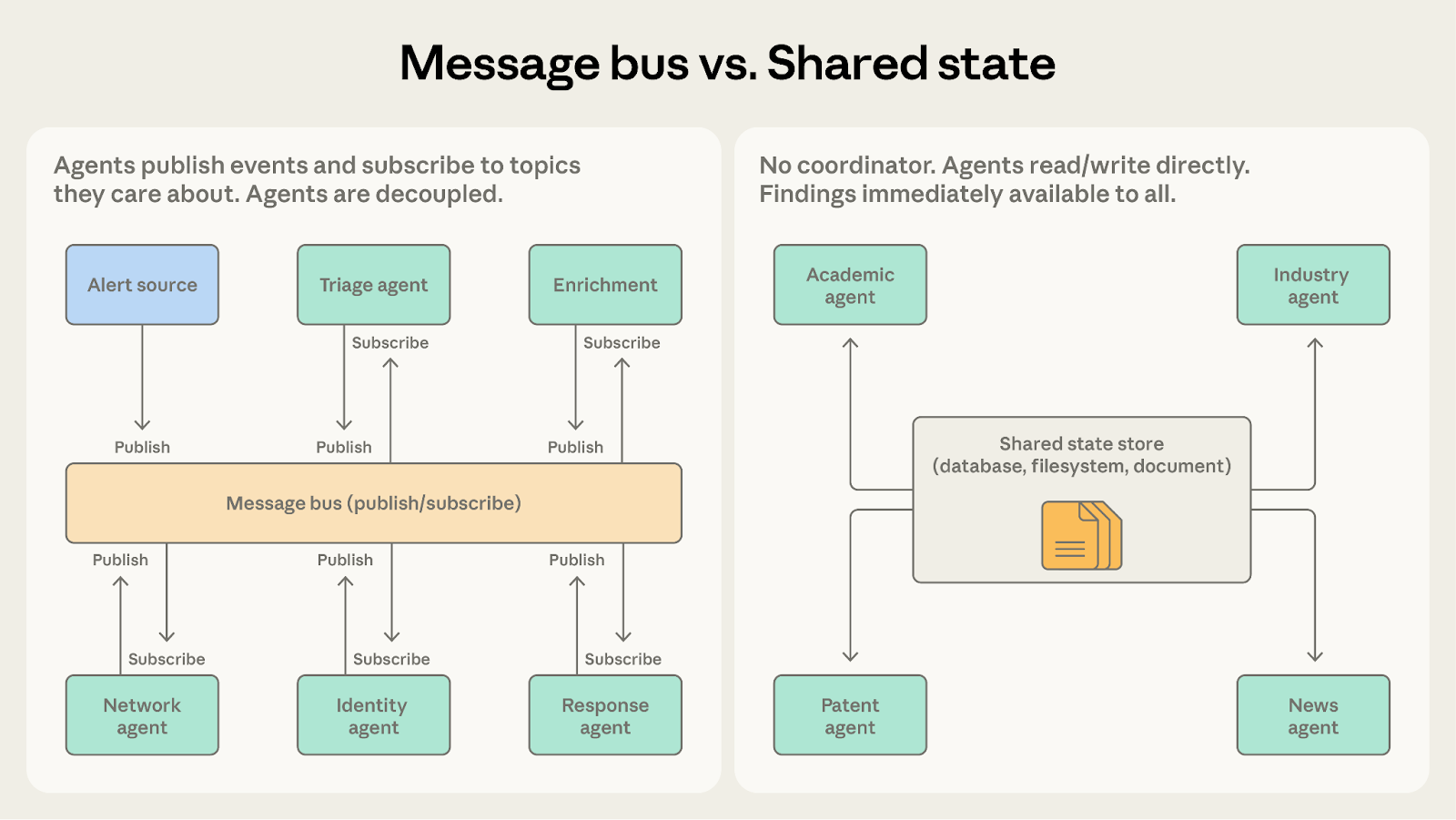
这两种模式都支持复杂的多智能体协同。关键问题在于,工作是以离散事件流动,还是不断累积成共享知识库。
-
当智能体是在流水线中对事件作出响应时,选择消息总线。安全运营系统会按阶段处理告警,每个事件都会触发下一个事件,直到整个流程完成。这种模式在把事件高效路由给有能力的智能体方面表现很好。
-
当智能体需要随着时间推移不断建立在累积发现之上时,选择共享状态。研究综合系统会持续积累知识。智能体会反复回到共享存储,查看别人已经发现了什么,再调整自己的调查方向。
消息总线里仍然有一个路由器,也就是说仍然有一个中心组件负责决定事件该往哪走。共享状态则是去中心化的。如果去掉单点故障是优先目标,共享状态在这点上会做得更彻底。
如果消息总线系统里的智能体发布事件,目的已经不是触发动作,而是共享发现,那共享状态会更合适。
如何开始
生产系统里,经常会把多种模式混合使用。一个常见的混合方式,是整体流程使用协调者-子智能体,而在协作密集的子任务里使用共享状态。另一种常见方式,是用消息总线做事件路由,而每类事件内部再由类似智能体团队的工作者来处理。这些模式是积木,不是非此即彼的互斥选项。
下表总结了每种模式分别适用于什么时候。
场景 模式 质量要求高,评估标准明确的输出 生成器-验证器 任务拆解清晰,子任务边界明确 协调者-子智能体 并行工作负载,彼此独立且持续时间长的子任务 智能体团队 事件驱动流程,不断扩大的智能体生态 消息总线 协作型研究,智能体共享发现 共享状态 不允许有单点故障 共享状态
对于大多数使用场景,我们建议从协调者-子智能体开始。它能覆盖最广的一类问题,同时协同开销也最低。先观察它在哪些地方吃力,再在具体需求变得明确之后演进到其他模式。
接下来的文章里,我们会逐一深入分析每种模式,并给出生产级实现和案例研究。想了解多智能体系统在什么时候值得投入,可以先看这篇文章 构建多智能体系统:何时以及如何使用它们。
致谢
本文由 Cara Phillips 撰写,Eugene Yang、Jiri De Jonghe、Samuel Weller 和 Erik S. 亦有贡献。
未找到任何条目。
上一页上一页
0/5
下一页下一页
电子书

常见问题
未找到任何条目。
相关文章
探索更多产品新闻,以及使用 Claude 构建产品的团队最佳实践。

2026 年 4 月 10 日
为 AI 加速攻势做好安全体系准备
智能体
为 AI 加速攻势做好安全体系准备为 AI 加速攻势做好安全体系准备
为 AI 加速攻势做好安全体系准备为 AI 加速攻势做好安全体系准备

2026 年 1 月 23 日
构建多智能体系统:何时以及如何使用它们
智能体
构建多智能体系统:何时以及如何使用它们构建多智能体系统:何时以及如何使用它们
构建多智能体系统:何时以及如何使用它们构建多智能体系统:何时以及如何使用它们

2026 年 4 月 2 日
发挥 Claude 的智能
智能体
发挥 Claude 的智能发挥 Claude 的智能
发挥 Claude 的智能发挥 Claude 的智能

2026 年 3 月 5 日
AI 智能体的常见工作流模式,以及何时使用它们
智能体
AI 智能体的常见工作流模式,以及何时使用它们AI 智能体的常见工作流模式,以及何时使用它们
AI 智能体的常见工作流模式,以及何时使用它们AI 智能体的常见工作流模式,以及何时使用它们
用 Claude 改变你的组织运作方式
查看定价
查看定价查看定价
联系销售
联系销售联系销售
获取开发者通讯
产品更新、实用指南、社区精选等内容。每月发送到你的收件箱。
订阅订阅
如果你希望接收我们的每月开发者通讯,请提供你的电子邮箱地址。你可以随时取消订阅。
谢谢,你已订阅。
抱歉,你的提交出了点问题,请稍后再试。
首页首页
下一页下一页
谢谢,你的提交已收到。
糟糕,提交表单时出了点问题。
写作
按钮文本按钮文本
学习
按钮文本按钮文本
编程
按钮文本按钮文本
写作
-
帮我为特定受众打造独特的表达风格
你好 Claude!你能帮我为某一类受众打造独特的表达风格吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
提升我的写作风格
你好 Claude!你能帮我提升写作风格吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
头脑风暴创意点子
你好 Claude!你能帮我一起头脑风暴一些创意点子吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
学习
-
把一个复杂主题讲简单
你好 Claude!你能把一个复杂主题讲得简单一点吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
帮我理清这些想法
你好 Claude!你能帮我理清这些想法吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
准备考试或面试
你好 Claude!你能帮我准备考试或面试吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
编程
-
解释一个编程概念
你好 Claude!你能帮我解释一个编程概念吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
看看我的代码并给我一些建议
你好 Claude!你能帮我看看代码并给我一些建议吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
和我一起随性写代码
你好 Claude!你能和我一起随性写代码吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
更多
-
撰写案例研究
这是另一个测试
-
撰写资助申请书
你好 Claude!你能帮我撰写资助申请书吗?如果你需要更多信息,请立刻问我 1 到 2 个关键问题。如果你觉得我上传一些文档会让你做得更好,也请告诉我。你可以使用你能访问的工具,比如 Google Drive、网页搜索等,只要它们有助于更好地完成这个任务。请不要使用分析工具。请让你的回复保持友好、简短、像聊天一样自然。
请尽快开始执行这个任务。如果合适的话,最好能给出一个成品。如果使用成品形式,请考虑哪种形式最适合这个任务,比如交互式、可视化、清单等。谢谢你的帮助!
-
撰写视频脚本
这是一个测试
AnthropicAnthropic
© [year] Anthropic PBC
产品
-
Claude
ClaudeClaude
-
Claude Code
Claude CodeClaude Code
-
Claude Code 企业版
Claude Code for EnterpriseClaude Code for Enterprise
-
Claude Cowork
Claude CoworkClaude Cowork
-
Pro 套餐
Pro planPro plan
-
Max 套餐
Max planMax plan
-
Team 套餐
Team planTeam plan
-
Enterprise 套餐
Enterprise planEnterprise plan
-
下载应用
Download appDownload app
-
定价
PricingPricing
-
Log inLog in
功能
-
Claude Code 安全
Claude Code SecurityClaude Code Security
-
Claude for Chrome
Claude for ChromeClaude for Chrome
-
Claude for Slack
Claude for SlackClaude for Slack
-
Claude for Excel
Claude for ExcelClaude for Excel
-
Claude for PowerPoint
Claude for PowerPointClaude for PowerPoint
-
Claude for Word
Claude for WordClaude for Word
-
Skills
SkillsSkills
模型
-
Mythos 预览版
Mythos previewMythos preview
-
Opus
OpusOpus
-
Sonnet
SonnetSonnet
-
Haiku
HaikuHaiku
解决方案
-
AI 智能体
AI agentsAI agents
-
代码现代化
Code modernizationCode modernization
-
编程
CodingCoding
-
客户支持
Customer supportCustomer support
-
教育
EducationEducation
-
金融服务
Financial servicesFinancial services
-
政府
GovernmentGovernment
-
医疗健康
HealthcareHealthcare
-
生命科学
Life sciencesLife sciences
-
非营利组织
NonprofitsNonprofits
-
安全
SecuritySecurity
Claude Platform
-
概览
OverviewOverview
-
开发者文档
Developer docsDeveloper docs
-
定价
PricingPricing
-
市场
MarketplaceMarketplace
-
Amazon Bedrock
Amazon BedrockAmazon Bedrock
-
Google Cloud 的 Vertex AI
Google Cloud’s Vertex AIGoogle Cloud’s Vertex AI
-
Microsoft Foundry
Microsoft FoundryMicrosoft Foundry
-
区域合规
Regional complianceRegional compliance
-
控制台登录
Console loginConsole login
资源
-
博客
BlogBlog
-
Claude 合作伙伴网络
Claude partner networkClaude partner network
-
社区
CommunityCommunity
-
连接器
ConnectorsConnectors
-
课程
CoursesCourses
-
客户案例
Customer storiesCustomer stories
-
Anthropic 工程团队
Engineering at AnthropicEngineering at Anthropic
-
活动
EventsEvents
-
插件
PluginsPlugins
-
由 Claude 提供支持
Powered by ClaudePowered by Claude
-
服务合作伙伴
Service partnersService partners
-
创业公司计划
Startups programStartups program
-
教程
TutorialsTutorials
-
使用场景
Use casesUse cases
公司
-
Anthropic
AnthropicAnthropic
-
招聘
CareersCareers
-
Economic Futures
Economic FuturesEconomic Futures
-
研究
ResearchResearch
-
新闻
NewsNews
-
负责任扩展政策
Responsible Scaling PolicyResponsible Scaling Policy
-
安全与合规
Security and complianceSecurity and compliance
-
透明度
TransparencyTransparency
帮助与安全
-
可用性
AvailabilityAvailability
-
状态
StatusStatus
-
支持中心
Support centerSupport center
条款与政策
-
隐私选项
Cookie 设置
我们使用 Cookie 来提供并改进服务、分析网站使用情况,并在你同意的情况下,为你定制或个性化体验并推广我们的服务。你可以在这里阅读我们的 Cookie 政策。
自定义 Cookie 设置 拒绝所有 Cookie 接受所有 Cookie
必要
启用安全性和基础功能。
必需
分析
启用网站性能跟踪。
关闭
营销
启用广告个性化和跟踪。
关闭
保存偏好设置
-
隐私政策
Privacy policyPrivacy policy
-
负责任披露政策
Responsible disclosure policyResponsible disclosure policy
-
服务条款:商业版
Terms of service: CommercialTerms of service: Commercial
-
服务条款:消费者版
Terms of service: ConsumerTerms of service: Consumer