你每次使用 ChatGPT 或 Claude 时一定都注意到过,第一枚 token 明显要更久才会出现。接下来其余内容却几乎会立刻流式输出。
这背后其实是一个刻意为之的工程设计,叫作 KV 缓存,它的目的就是让大语言模型的推理更快。
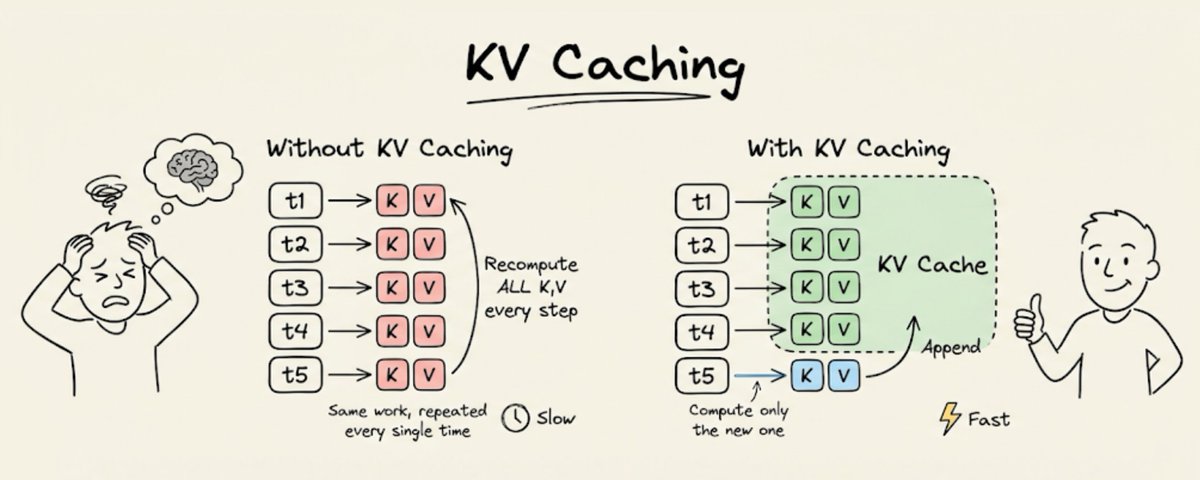
在进入技术细节之前,先看一组并排对比,看看使用 KV 缓存和不使用 KV 缓存时,大模型推理有什么差别。
现在我们从最基本的原理出发,来理解它是怎么工作的。
第 1 部分:大模型如何生成 token
Transformer 会处理所有输入 token,并为每个 token 产出一个隐藏状态。这些隐藏状态随后会被投影到词表空间,生成 logits,也就是词表中每个词对应的一个分数。
但真正重要的,只有最后一个 token 对应的 logits。你从中采样,得到下一个 token,把它追加到输入里,然后重复这个过程。
这里的关键洞见是,想生成下一个 token,你其实只需要最新那个 token 的隐藏状态。其余所有隐藏状态,都只是中间产物。
第 2 部分:Attention 实际上在计算什么
在 Transformer 的每一层里,每个 token 都会得到三个向量,分别是 query,也就是 Q,key,也就是 K,以及 value,也就是 V。Attention 会把 query 和 key 相乘得到分数,再用这些分数对 value 加权。
现在只看最后一个 token。
QK^T 的最后一行会用到:
-
最后一个 token 的 query 向量
-
序列中所有 token 的 key 向量
而这一行最终的 attention 输出会用到:
-
同一个 query 向量
-
所有的 key 和 value 向量
所以,为了计算我们唯一真正需要的那个隐藏状态,每一层 attention 都需要最新 token 的 Q,以及所有 token 的 K 和 V。
第 3 部分:这里面的重复计算
生成第 50 个 token 时,需要第 1 到第 50 个 token 的 K 和 V 向量。生成第 51 个 token 时,需要第 1 到第 51 个 token 的 K 和 V 向量。
而第 1 到第 49 个 token 的 K 和 V 向量,其实早就算过了。它们没有变化。输入相同,输出也相同。可模型还是会在每一步里把它们从头重算一遍。
这意味着每一步都会有 O(n) 的重复工作。放到整个生成过程中,就会浪费 O(n²) 的算力。
第 4 部分:怎么解决
办法就是,不要在每一步都重算所有 K 和 V 向量,而是把它们存起来。对于每个新 token:
-
只为最新的那个 token 计算 Q、K 和 V。
-
把新的 K 和 V 追加到缓存里。
-
从缓存中取出之前所有的 K 和 V 向量。
-
用新的 Q 对完整缓存中的 K 和 V 运行 attention。
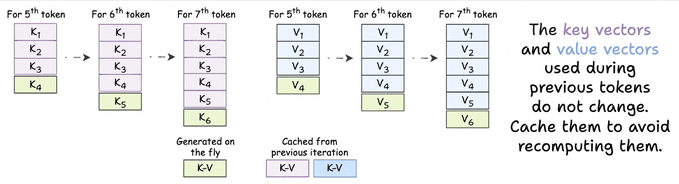
这就是 KV 缓存。每一层、每一步,只新增一个 K 和一个 V。其余全部直接从内存里取。
Attention 本身的计算量依然会随着序列长度增长,因为你还是要对所有 key 和 value 做 attention。但生成 K 和 V 的那些高开销投影,每个 token 只需计算一次,而不是每一步都算一次。
第 5 部分:首个 token 时间
现在你就能明白,为什么第一个 token 会慢了。
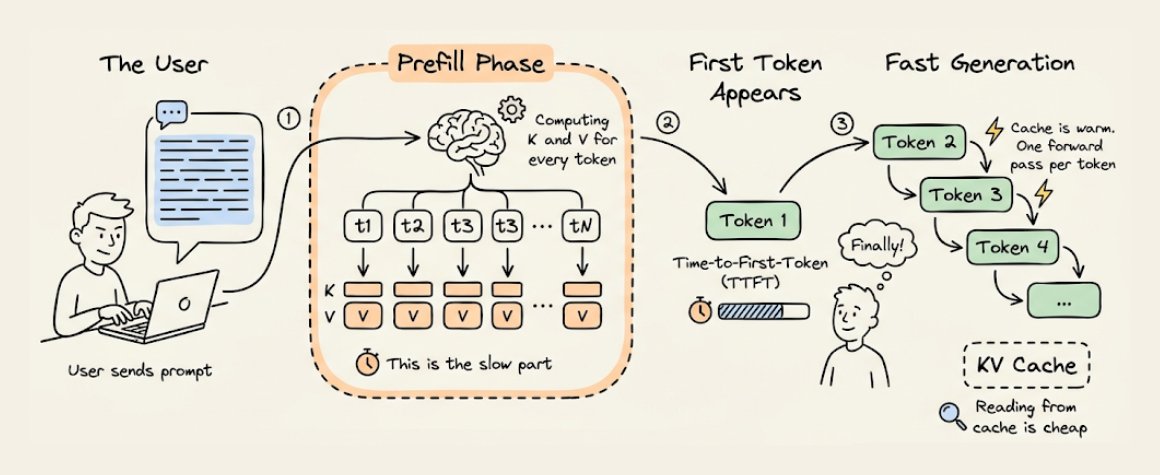
当你发出一个 prompt 时,模型会用一次完整的前向传播处理整段输入,计算并缓存每个 token 的 K 和 V 向量。这个过程叫 prefill 阶段,也是整个请求里计算最密集的部分。
一旦缓存预热完成,后续每个 token 都只需要做一次只含单个 token 的前向传播。
这段最初的延迟,就叫 time-to-first-token,简称 TTFT。prompt 越长,prefill 越久,等待时间也越长。优化 TTFT 本身又是一个很深的话题,比如 chunked prefill、speculative decoding、prompt caching,但底层逻辑始终一样:构建缓存很贵,读取缓存很便宜。
第 6 部分:取舍
KV 缓存是用内存换算力。每一层都要为每个 token 存储 K 和 V 向量。以 Qwen 2.5 72B 为例,80 层、32K 上下文、隐藏维度 8192,单个请求的 KV 缓存就可能占用数 GB 的 GPU 显存。当并发请求达到数百个时,它占用的显存往往会超过模型权重本身。
这也是为什么会有 grouped-query attention,也就是 GQA,以及 multi-query attention,也就是 MQA:让多个 query head 共享 key/value head,从而降低内存占用,同时质量损失很小。
这也是为什么把上下文长度翻倍会很难。窗口翻倍,每个请求的 KV 缓存也翻倍,并发用户数就会减少。
还有另一个思路叫 Paged attention,可以解决这个问题。我前不久在这里讲过:
总结
KV 缓存消除了自回归生成过程中的重复计算。之前的 token 总是会生成相同的 K 和 V 向量,所以只需要计算一次并存起来。每个新 token 只需要计算它自己的 Q、K 和 V。之后,attention 再对完整缓存执行计算。
实际中常常能带来 5 倍加速。代价是 GPU 显存,而在大规模场景下,这往往会成为真正的瓶颈。所有的大模型服务栈,比如 vLLM、TGI、TensorRT-LLM,都是建立在这个思路之上的。
到这里就讲完了。
如果你喜欢这篇教程:
可以在这里找到我 → @_avichawla
我每天都会分享关于 DS、ML、LLMs 和 RAGs 的教程与见解。