Every outbound at LangChain used to start the same way: a rep toggling between tabs. Salesforce for the account record, Gong for call history, LinkedIn for the contact, the company website for context. Fifteen minutes of research before a single word was written, and no easy way to know if a teammate had already reached out yesterday. Inbound follow-up used to mean manually dropping the same message into Apollo for every new contact.
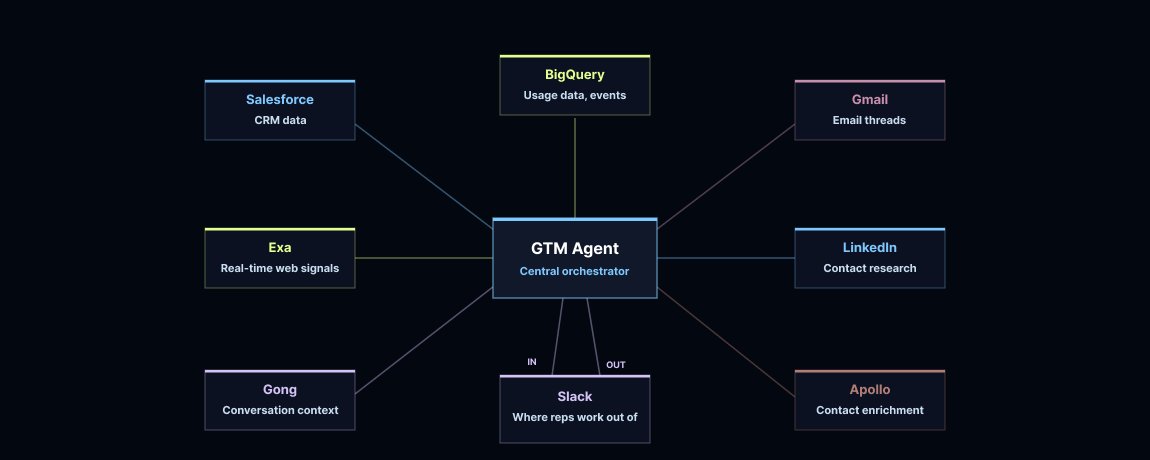
We built a GTM agent that runs the process end-to-end. It triggers on new Salesforce leads, checks whether we should reach out, gathers context (including meeting history), and sends a Slack draft (with reasoning + sources) for the rep to approve. We built it on Deep Agents because this is a long-running, multi-step process that has to orchestrate multiple tools and large amounts of data reliably.
Key results
-
Lead-to-qualified-opportunity conversion rate up 250% from December 2025 to March 2026, driving 3x more pipeline dollars in the same period
-
Rep follow-up rate is up 97% for silver leads and 18% for gold leads
-
Sales reps reclaimed 40 hours per month each, totaling 1,320 hours across the team
-
50% daily and 86% weekly active usage for sales team members
Team love
Constraints & success criteria
Before writing any code, we defined what the agent actually needed to do.
We had two goals: reduce the time reps spend researching and drafting per lead, and improve conversion on marketing-generated inbound. Outbound research and drafting is systematic enough to automate, but only if the system is safe, auditable, and improves with use.
Non-negotiables
-
Human-in-the-loop: Nothing is sent without an explicit rep review and approval. A single poorly timed email can undo months of relationship-building.
-
Contact history knowledge: The agent needed to check whether a rep or teammate had already reached out before drafting anything.
Core capabilities
-
Relationship-aware personalization: The draft should reflect the current state of the account (customer vs. warm prospect vs. cold), and not treat every lead the same way.
-
Explainability: Reps should be able to see key inputs and understand why the agent chose a particular angle so they could refine it and provide feedback.
-
Learning loop: The agent should learn from rep edits over time so drafts improve without anyone manually updating prompts.
Measurement
Every rep action (send, edit, cancel) is logged to LangSmith and attached to the underlying trace so we can evaluate quality, catch regressions, and quantify what’s working.
Scope expansion: account intelligence
Beyond one-off drafts, we also wanted the agent to proactively surface account-level signals like deal risks, expansion opportunities, and competitive moves, so reps know where to focus each week.
What we built
The GTM agent does two things: (1) it researches leads and writes personalized email drafts, and (2) it aggregates account-level signals across web activity, developer ecosystems, product usage, and marketing touchpoints to show reps where to focus. By tying that intent data back to a rep’s accounts, it surfaces meaningful activity, flags deal risks and competitive moves, and clarifies who is ideal to reach out to next.
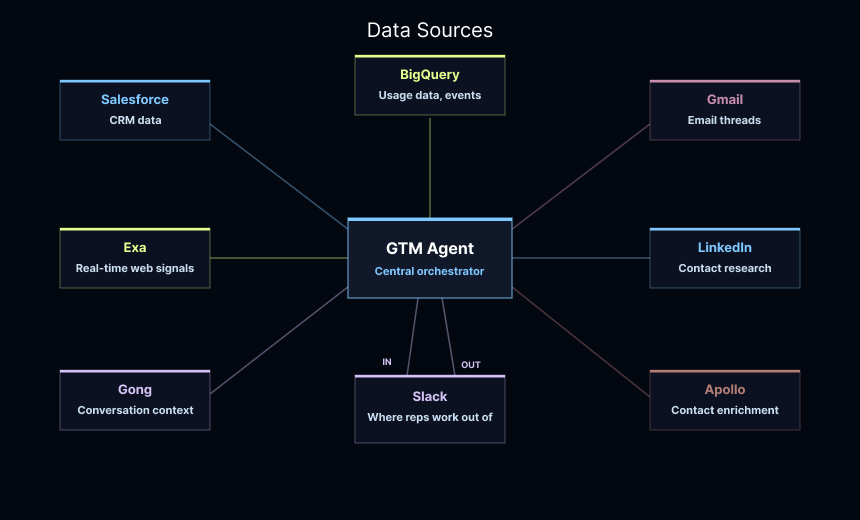
We connected the agent to the following data sources:
https://blog.langchain.com/introducing-ambient-agents/
Inbound lead processing
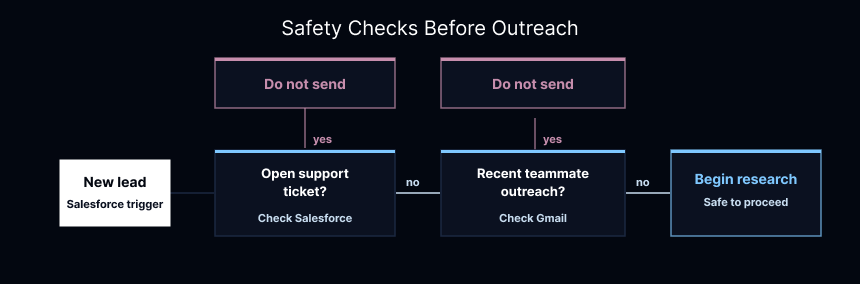
When a new lead shows up in Salesforce, the agent takes over immediately. The first thing it does is look for reasons not to send anything. If someone just filed a support ticket, or if a teammate already reached out earlier in the week, sending an automated email would be a mistake. The agent is programmed to be cautious.
https://www.langchain.com/langsmith/deployment
Once it clears those checks, it does the same research a rep used to do manually: pulls the full Salesforce record, reads through Gong transcripts, checks the prospect's LinkedIn profile. If there isn't much internal history, it goes to the web with Exa to understand what the company is doing with AI right now.
How it writes the email draft depends on the state of the relationship. The agent follows a defined outbound skill, a playbook it loads before drafting. The skill is designed to cover both warm and cold cases. An existing customer gets something different than a warm prospect, who gets something different than a cold contact. For cold outreach, the agent keeps it brief and research-backed, following a playbook we've defined in the skill.
https://smith.langchain.com/
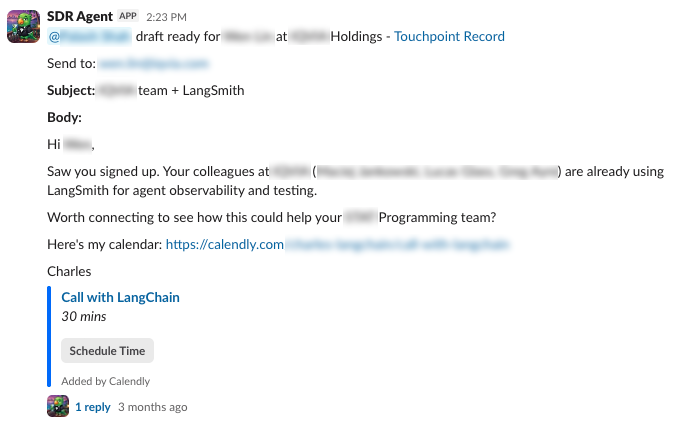
The rep sees the finished draft in a Slack DM with buttons to send, edit, or cancel. They can also see the agent's reasoning, so it's clear why it took a particular angle. If they send it, the agent queues up a set of follow-up emails to optionally enroll the prospect in.
As we've refined the agent, we added a 48-hour SLA for silver leads: if a rep hasn't approved or declined the draft within that window, it sends automatically. This has meaningfully increased our follow-up rate for leads that would otherwise slip through without a response.
Account intelligence
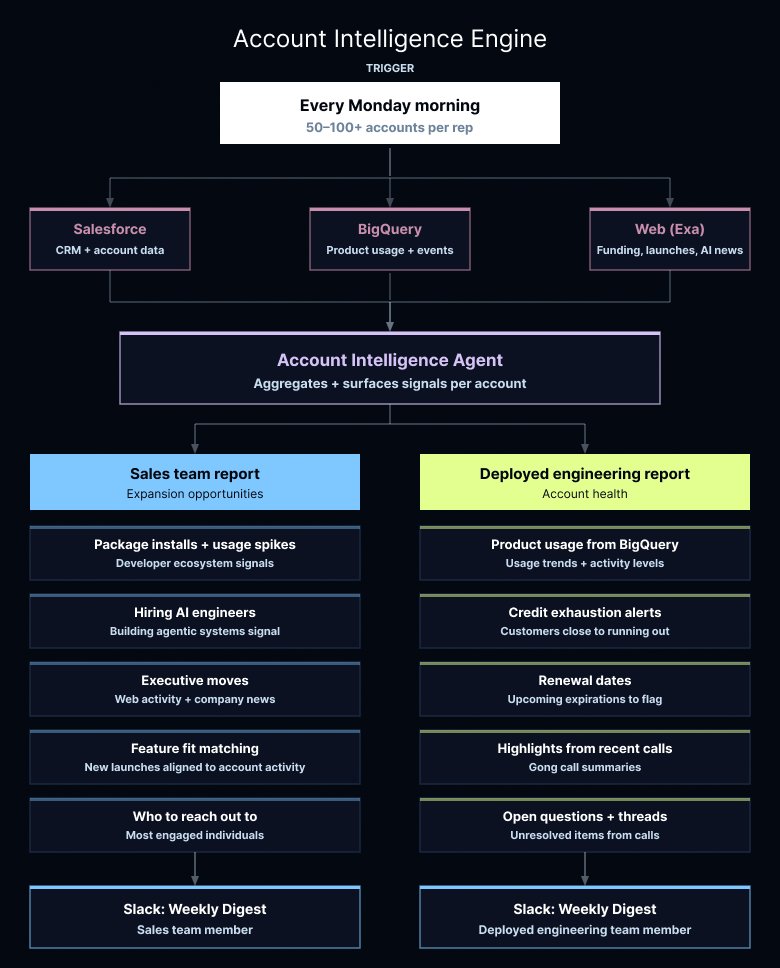
As our team scaled, reps started owning anywhere from 50 to over 100 accounts each. At that volume, it's easy for things to go quiet or for expansion opportunities to slip through.
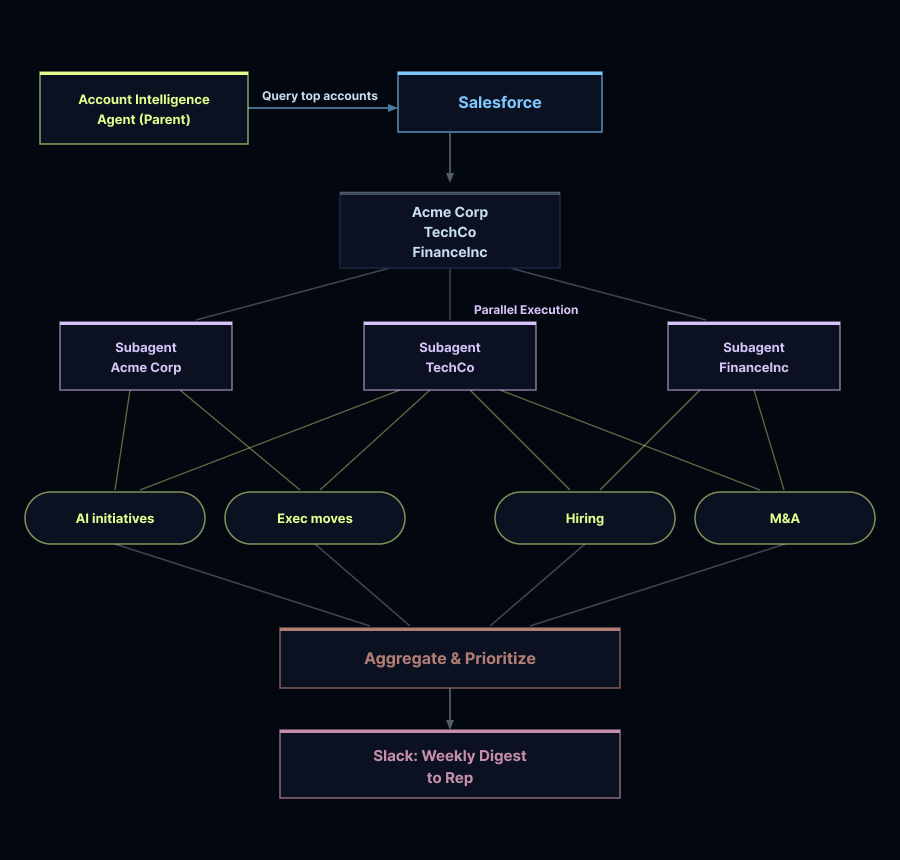
Every Monday morning, the agent pulls data from Salesforce and BigQuery. It then checks the outside world for funding rounds, product launches, and new AI initiatives. We tailored the reports for two audiences: our sales team and our deployed engineering team, since they care about different data points.
For sales, the agent aggregates signals across product usage, developer ecosystems, web activity, hiring trends, and company news to surface expansion opportunities. It flags executive moves, spikes in package installations, and whether a company is actively hiring AI engineers or building agentic systems – which is a strong signal they're ready to expand. It also identifies potential good fits when we launch new features, matching accounts whose recent activity aligns well with the new features. And because knowing an account is active isn't enough on its own, it surfaces which individuals are most engaged and suggests who to reach out to next.
For deployed engineers, the focus shifts to account health. The agent pulls product usage from BigQuery, highlights from recent customer calls, upcoming renewal dates, and cases where a customer is close to running out of credits. It also surfaces open questions and unresolved threads from recent calls. The goal is to flag what actually needs a person to step in, so the team isn't spending Sunday evenings digging through dashboards.
https://docs.langchain.com/oss/python/deepagents/skills
How we built it
The agent needed to pull from multiple sources, reason across them, and produce a personalized output. This is more than a simple LLM call can handle reliably.
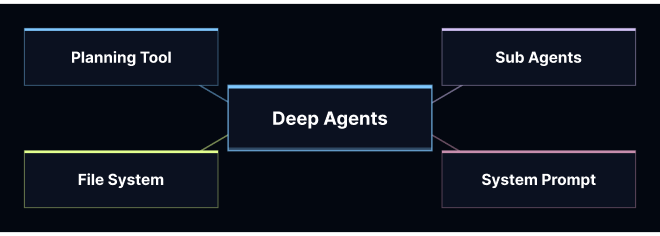
We chose Deep Agents for the multi-step orchestration because the inputs are inherently spiky: meeting data, CRM history, and web research vary a lot in size and structure. With Deep Agents, large tool results get offloaded into a virtual filesystem automatically, so we didn't have to build our own truncation and retrieval layer. We also used the harness's native planning tooling to enforce a consistent checklist (do-not-send checks → research → draft → rationale → follow-ups), which made runs easier to debug and reduced agent wandering.
We connected the agent to LangSmith so we could understand how sales reps were actually using it and measure whether the agent was improving over time. That meant setting up evaluations from the start rather than retrofitting them later, which turned out to be critical for catching regressions when we iterated on prompts or swapped model versions.
Agent patterns
Moving our GTM agent to production surfaced two problems we had to solve: how to make the agent learn from the people using it, and how to keep runs efficient at scale.
Memory
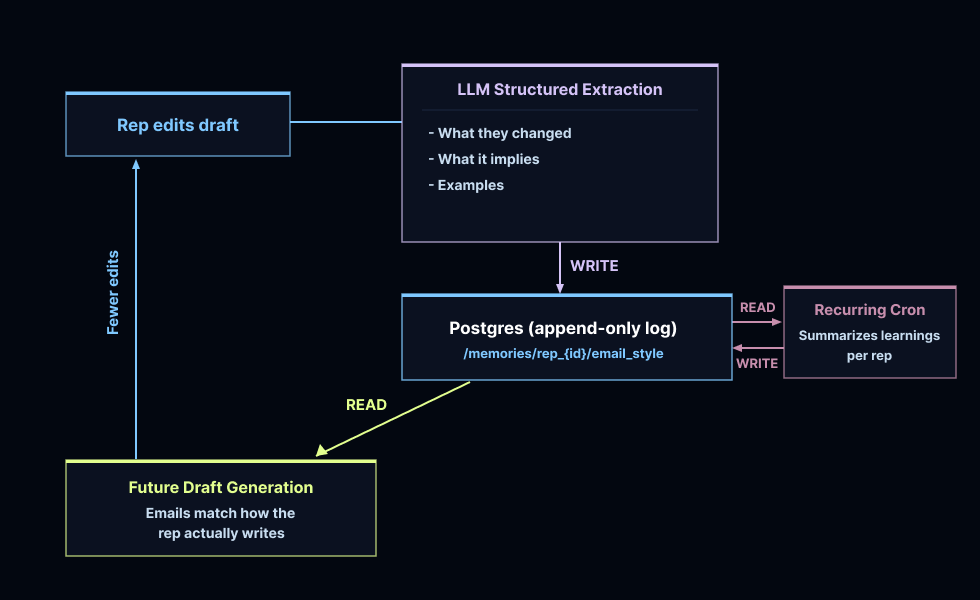
When a rep edits a draft in Slack, the system compares the original against the revised version. If the changes are substantive, an LLM analyzes the diff and extracts structured style observations: what changed, what it implies about the rep's preferences, and an optional quoted example. Those observations are stored in PostgreSQL, keyed per rep, and every future run reads them before drafting.
Each rep has stylistic preferences around tone and brevity. The feedback loop is automatic. Every edit teaches the agent, and the next draft reflects it. A weekly cron compacts these memories to keep them from getting bloated over time.
Subagent delegation
Account intelligence runs through compiled subagents: lightweight agents with constrained tool sets and structured output schemas that act as contracts with the main agent. The sales research subagent has access to Apollo, Exa, and BigQuery, and returns structured prospect and market context. The deployed engineer subagent uses Salesforce, Gong, and support tools to return usage trends, open tickets, and expansion signals.
The parent agent spawns one subagent per account, keeping tools isolated and outputs predictable. Because subagents run independently, we can execute them in parallel. LangSmith Deployment handles horizontal scaling and durable execution, so the system stays reliable as volume grows.
https://docs.langchain.com/oss/python/deepagents/overview
Evals and feedback
Before writing any production code for a new workflow, we define what success looks like in LangSmith. We started with a small library of representative scenarios grounded in the situations our reps actually face, used those to build the initial agent or feature, and made sure the fundamentals work before expanding.
Once things were functional, we broadened the evaluation set in LangSmith to cover harder cases: a researcher deep in agentic AI or NLP, an existing customer we're trying to re-engage, accounts with prior Gong transcripts, verticals with heavy jargon like healthcare. Everything runs through a test harness that mocks our external APIs so we can observe behavior in a controlled environment before it touches real data.
We evaluate on two levels. First, rule-based assertions check the basics: right tools, right order, no duplicate drafts. Second, an LLM judge scores tone, word count, and formatting. Both run as part of a full eval suite in CI, and we treat any unexplained drift in agent behavior as a bug worth investigating.
But evals only tell part of the story. What actually matters is how reps use the drafts day to day. We track every Slack action (send, edit, cancel) and attach it directly to the trace in LangSmith. Over time, this lets us correlate writing patterns with real outcomes: which styles drive opens, which subject lines get replies. When something holds across enough reps, we codify it into the agent's default behavior.
The LangSmith eval suite and the rep feedback loop reinforce each other. One catches regressions, the other drives improvement.
Adoption beyond the sales team
The GTM agent started as an ambient agent, running as a background process. A lead appears in Salesforce, the agent runs, a draft lands in the rep's Slack. No trigger, no manual work.
We later built a conversational Slack interface as a side experiment, mostly to give SDRs a way to interact with the agent directly. What we didn't expect was how quickly it spread to the rest of the company. Because the agent was already connected to Salesforce, Gong, BigQuery, and Gmail, people found uses we hadn't designed for. Engineers checked product usage without writing SQL. Customer success pulled support history before renewal calls. Account executives summarized Gong transcripts before meetings.
We didn't build any of those workflows intentionally. The agent had the access, and people found the path of least resistance. Talking to the bot was easier than opening six different tabs.
We'll cover how other teams are using the GTM agent in a follow-up post.
Learnings
A few things we'd tell someone starting from scratch:
-
Start with a definition of success, not code. Before we write any production code for a new workflow, we define what good looks like and build a small scenario library around it. That set expands as the agent matures. By the time something ships, we have an eval test suite that catches regressions, flags drift, and runs in CI automatically.
-
Human-in-the-loop goes beyond safety. It turned out to be a data collection mechanism. Every rep action (send, edit, cancel) became a signal we could learn from. The memory system and feedback loop work because reps are in the flow.
-
Connect the agent to your systems of record from the start. The organic adoption across the company happened because the agent already had access to the data people needed. We didn't plan for engineers or customer success to use it, but that usage spread because the access was already there.
-
Long-running workflows need the right infrastructure. This agent required much more than a simple LLM call with a tool or two. It needed to pull from multiple sources, reason across them, run subagents in parallel, and maintain state across turns. Picking an agent harness, Deep Agents, built for that kind of orchestration saved us from rebuilding infrastructure from scratch.
-
We're still early. The GTM agent handles a real workflow today, but the feedback loops we've built – including memory, evals, and rep actions tied to traces – are what will make it meaningfully better over the next six months.








Link: http://x.com/i/article/2030841460829089792