
完整拆解一个开源工具如何在不改动 CLAUDE.md、提示词或模型的前提下,把你的 Claude Code 会话成本降到原来的三分之一,并附上配置指南和它为什么有效的解释。
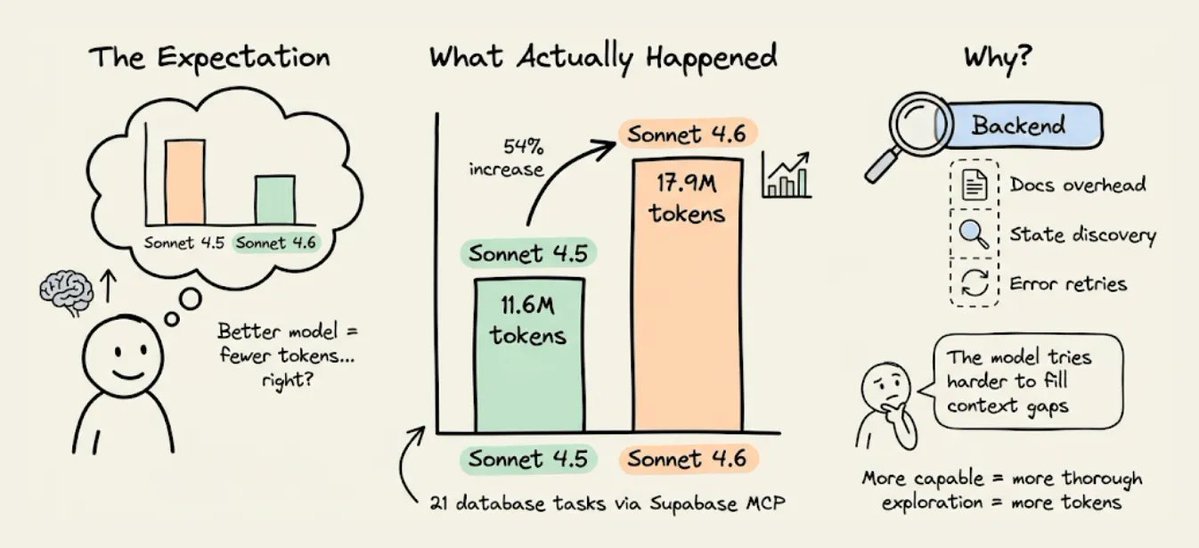
MCPMark V2 基准测试揭示了一个违反直觉的现象。
当 Claude 从 Sonnet 4.5 升级到 Sonnet 4.6 时,通过 Supabase 的 MCP 服务器进行后端操作的 token 用量反而上升了,在 21 个数据库任务中,从 1160 万涨到了 1790 万 token。
模型变得更聪明了,但后端 token 用量却真的增加了。
json{
"auth": {
"providers": ["google", "github"],
"jwt_secret": "configured"
},
"tables": [
{"name": "users", "columns": ["id", "email", "created_at"], "rls": "enabled"},
{"name": "posts", "columns": ["id", "title", "body", "author_id"], "rls": "enabled"}
],
"storage": { "buckets": ["avatars", "documents"] },
"ai": { "models": [{"id": "gpt-4o", "capabilities": ["chat", "vision"]}] },
"hints": ["Use RPC for batch operations", "Storage accepts files up to 50MB"]
}
原因很微妙,而且跟模型本身无关。
真正相关的是,后端把信息暴露给代理的方式。上下文不完整时,能力更强的模型并不会直接跳过缺口。
它会花更多 token 去推理这个缺口,运行更多发现性查询,也会更频繁地重试。所以缺失的上下文不会因为模型更好就消失,只会变得更贵。
下面来看看,为什么后端会成为代理的 token 黑洞,一种替代架构是什么样子,以及在真实项目里成本差异到底有多大。
为什么 Supabase 的 MCP 服务器会浪费 token
Supabase 是个很好的后端。但它并不是为 AI 代理操作而设计的,后来加上的 MCP 服务器也继承了这个限制。
有三个具体机制会导致 token 膨胀。
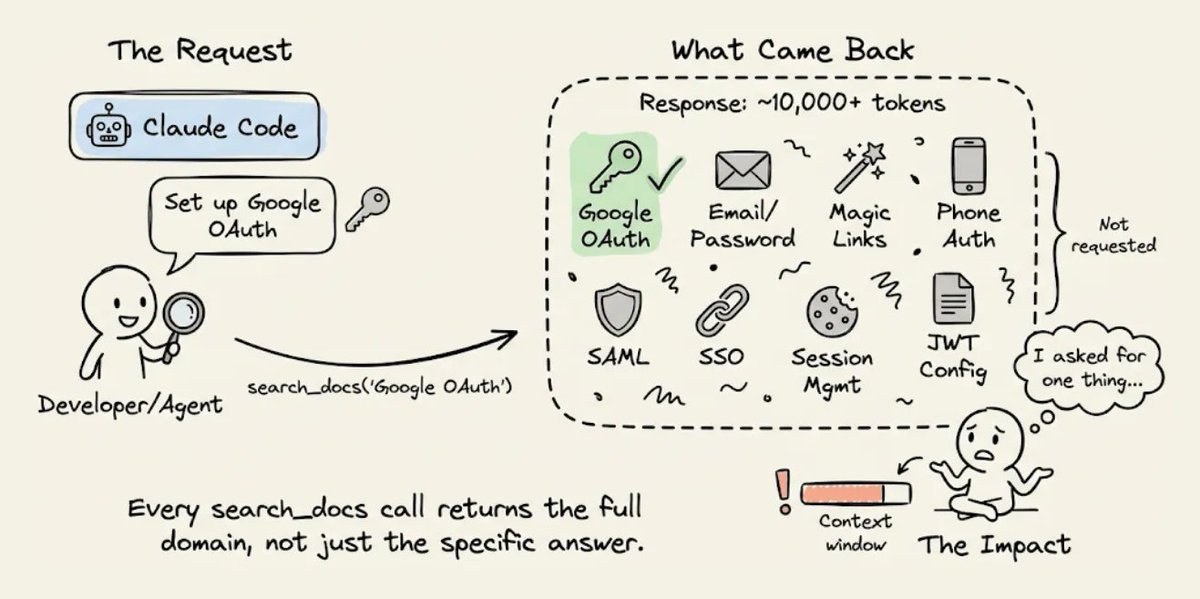
1) 文档检索会把所有内容都返回出来
当 CC 需要通过 Supabase 配置 Google OAuth 时,它会调用 search_docs 这个 MCP 工具。
Supabase 的实现会在每次调用时都返回完整的 GraphQL schema 元数据,token 数量通常是代理真正需要的 5 到 10 倍。
Build a chat with document app called DocuRAG.
It will be a typical RAG setup where a user
can upload a document. It will be chunked,
embedded, and stored in a vector DB. Once done,
A user can ask questions about the document.
The engine will retrieve the relevant chunks
after embedding the query. Finally, it will
generate a coherent response using GPT-4o based on
the query and the retrieved context. Add Google OAuth.
Use Insforge as the backend and also for the model
gateway. Build the front-end in Next.js.
如果代理想要的是 OAuth 配置说明,它拿到的却是整套认证文档,里面还包括邮箱密码、魔法链接、手机认证、SAML 和 SSO 等章节。
每次调用 search_docs 都会这样,比如数据库查询、存储配置和 edge function 部署时也是一样。
每次调用都会把整个领域的完整元数据倒出来。在一次会话里,如果代理要配置认证、数据库、存储和函数,仅仅文档开销就可能浪费掉几千个 token。
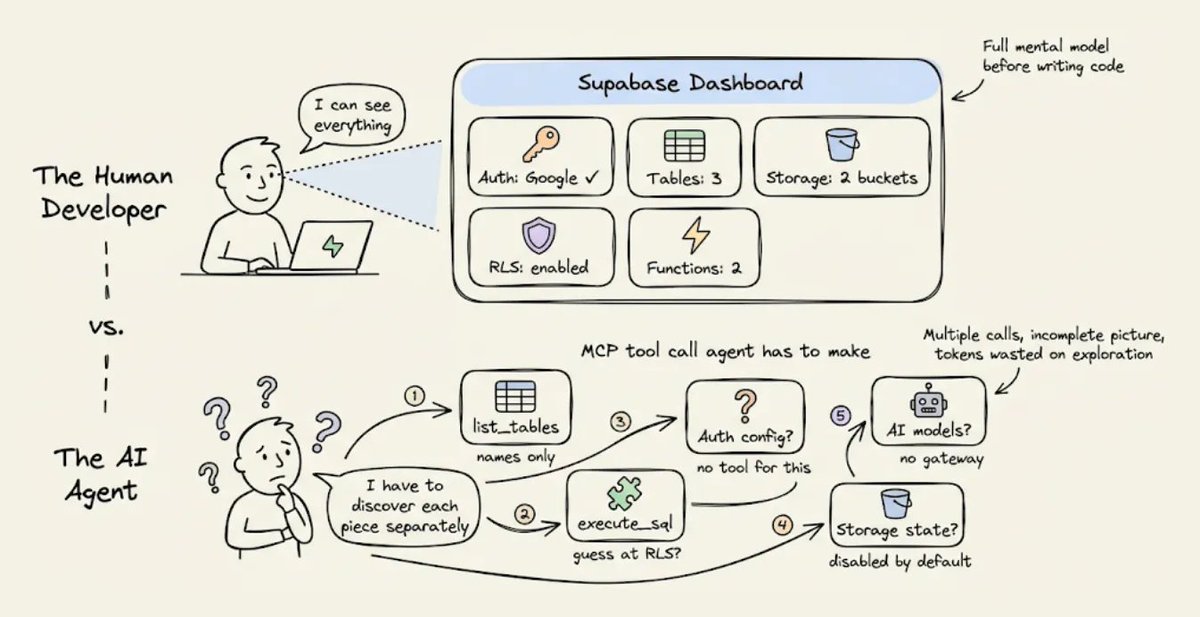
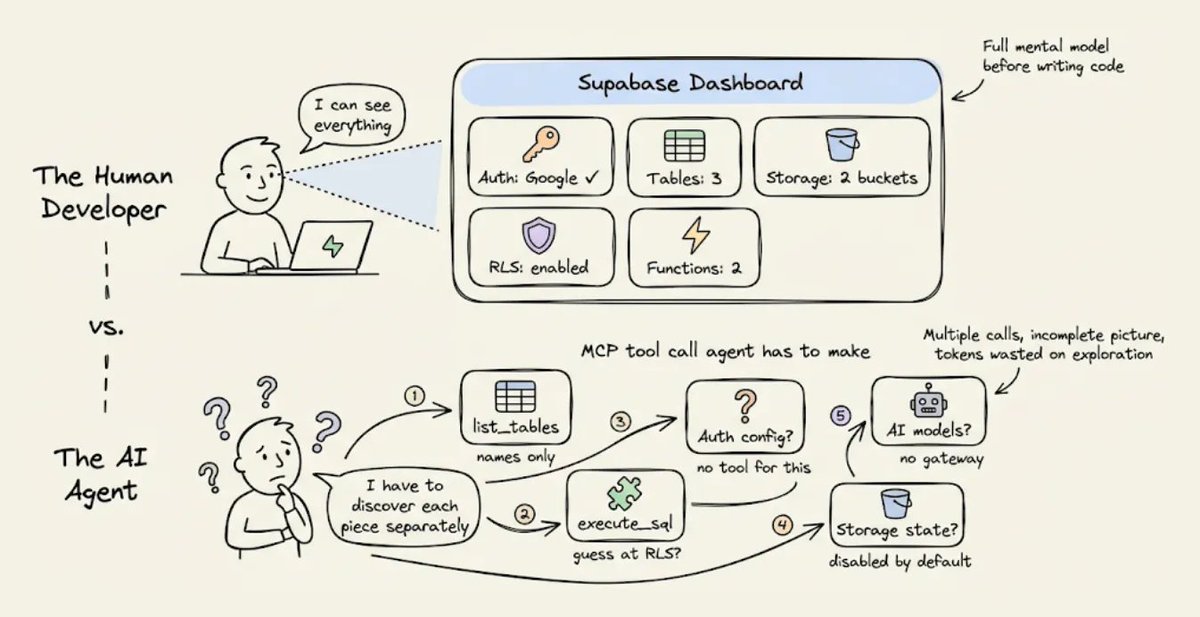
2) 看不到后端状态
人类开发者使用 Supabase 时,会打开控制台,一眼就能看到所有东西,比如启用中的认证提供商、数据表、RLS 策略、配置好的存储桶、已部署的 edge function 等等。
代理看不到控制台。
Supabase 的 MCP 服务器确实会通过一些独立工具暴露部分状态,比如 list_tables 和 execute_sql,但它没有办法让你问一句 现在我的整个后端长什么样 然后一次性返回一个结构化结果。
所以代理只能靠多次调用去拼出来。每次调用只返回局部视图,而且有些信息根本没法通过 MCP 拿到,比如到底配置了哪些认证提供商。
这种碎片化的发现过程会消耗 token,而且代理往往需要尝试好几次,因为返回的信息不完整,或者格式还需要进一步查询才能看懂。
3) 没有结构化的错误上下文
一旦出错了,而且一定会出错,因为代理本来就是在猜,Supabase 返回的是原始错误消息。可能是 RLS 拒绝导致的 403,也可能是 edge function 配错导致的 500,等等。
人类开发者会看到错误后去查 Supabase 控制台,再对照日志,最后把问题修掉。
代理没有这条路径。它只能拿到错误消息,推理可能的原因,然后尝试修复。
如果修错了,就继续重试。每次重试都会把整段对话历史重新发一遍,token 成本也会层层叠加。
这三个机制,也就是文档开销、状态发现和错误重试循环,会非常快地叠加起来。
像 Sonnet 4.6 这种推理更充分的模型,会让每一步探索都更彻底,也更昂贵。
这就是为什么 Sonnet 4.5 到 4.6 之间的 token 差距变大了,而且随着每一代新模型发布,这个差距大概率还会继续扩大。
npx skills add supabase/agent-skills
后端上下文工程应该是什么样
解决办法不是换一个模型。
而是给代理一个结构化的后端上下文,这样它就不用一边探索一边猜了。
这正是 Karpathy 所说的上下文工程,也就是 把恰好合适的信息放进上下文窗口里,以支撑下一步。这句话里他明确把工具和状态也算进上下文。大多数人会把这个思路用在提示词和 RAG 检索上。
但后端也是上下文窗口的一部分,而且现在几乎没人去优化这一层。
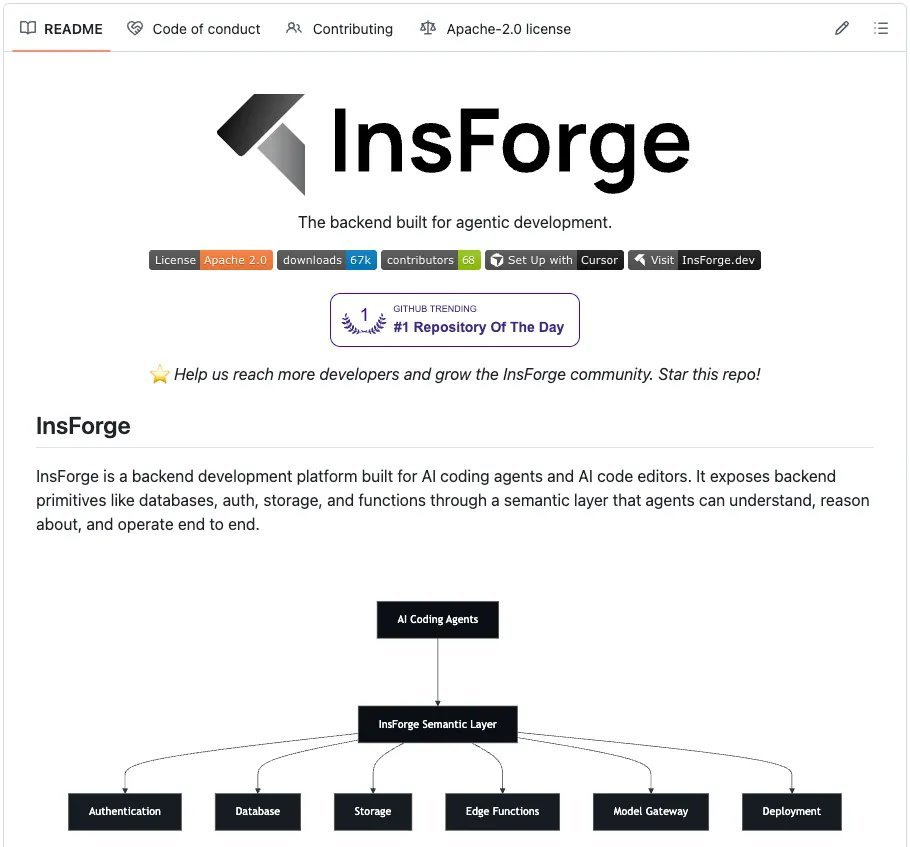
想看实际落地是什么样,可以看看 InsForge 这个项目,它是开源的,已有 8k stars,就是按这个思路实现的。
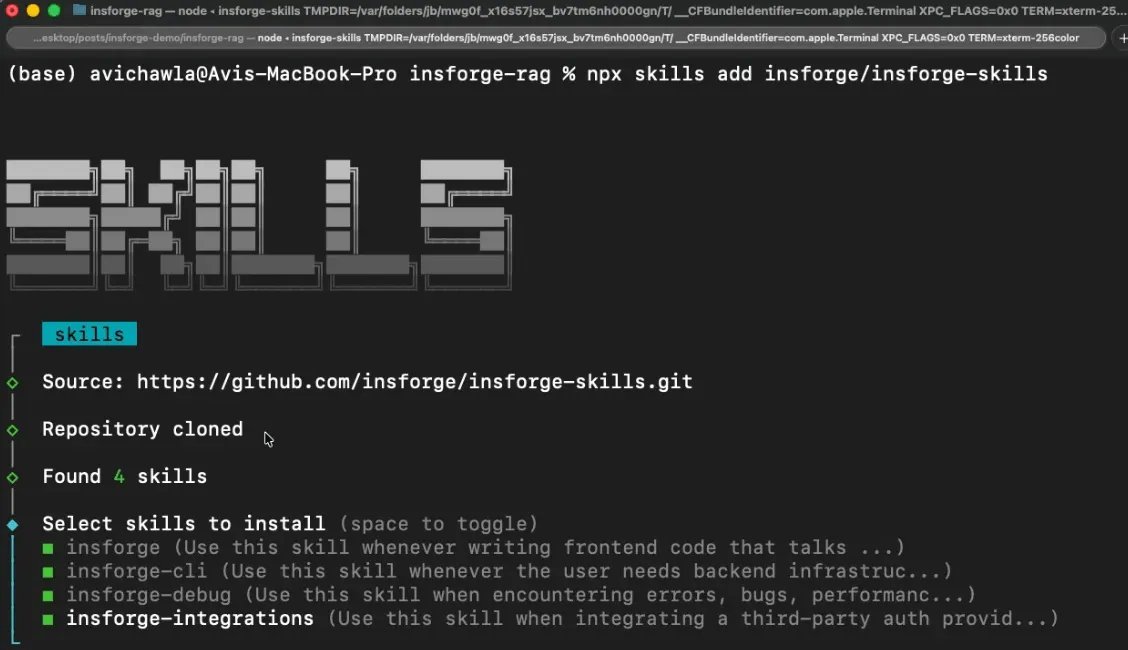
它提供了和 Supabase 相同的基础能力,比如带 pgvector 的 Postgres、认证、存储、edge functions 和 realtime,但它把信息层做成了更适合代理高效消费的结构。
它和 Claude Code 对接时,关键的架构差异就在于上下文是怎么传递的。
这里有三层一起配合工作。
-
用 Skills 提供静态知识
-
用 CLI 执行直接的后端操作
-
用 MCP 检查实时状态
每一层都在解决不同的问题,也会从不同角度减少 token 消耗。
1) Skills 提供静态知识,零往返
知识层的主要方案是 Skills。它们会在会话开始时直接加载进代理上下文,所以所有后端操作需要的 SDK 模式、代码示例和边界情况,不需要任何工具调用就能拿到。
Skills 还采用渐进式披露机制,起初只加载元数据,也就是名字、描述,以及每个 skill 大约 70 到 150 个 token 的信息。
只有当代理判断当前任务和某个 skill 匹配时,才会加载这个 skill 的完整内容。也就是说,你可以装上 100 多个 skills 而不会把上下文撑爆,这一点是 MCP 那种全有或全无的 schema 加载方式做不到的。
四个 skill 覆盖完整技术栈,而且每个都只负责一个明确领域。
-
insforge 负责和后端交互的前端代码
-
insforge-cli 负责后端基础设施管理
-
insforge-debug 负责结构化错误诊断,覆盖常见失败场景,比如认证错误、慢查询、edge function 故障、RLS 拒绝、部署问题和性能退化
-
insforge-integrations 负责第三方认证提供商,比如 Clerk、Auth0、WorkOS、Kinde、Stytch
一条命令就能把这四个都装上。
2) CLI 用于直接执行
真正在执行后端操作时,比如建表、跑 SQL、部署函数、管理密钥,InsForge CLI 是主接口。
每条命令都支持 --json 结构化输出,支持 -y 跳过确认提示,还会返回语义化退出码,这样代理就能以编程方式识别认证失败、项目缺失或权限错误。
这很有帮助,因为 Claude Code 可以把 CLI 输出继续交给 jq、grep 和 awk 处理,而如果走 MCP,往往得串行调用多个工具才能做到同样的事。
Scalekit 的基准测试显示,在单用户工作流里,CLI+Skills 的成功率接近 100%,token 效率比等价的 MCP 方案高 10 到 35 倍。
下面是代理真实运行过的一些操作。
代理会解析 JSON,并根据退出码来处理错误。
3) MCP 工具用于检查实时后端状态
MCP 依然有用,但适用范围更窄,比如在后端状态持续变化时,用来检查当前状态。
InsForge 的 MCP 服务器暴露了一个轻量级的 get_backend_metadata 工具,只需一次调用,就能返回完整后端拓扑的结构化 JSON。
只需一次调用和大约 500 个 token,代理就能掌握完整的后端拓扑。里面的 hints 字段还会提供面向代理的指导,减少错误 API 用法。
这里最关键的设计选择是,MCP 被用来检查状态,也就是那些会随着代理工作而变化的信息,而不是拿来检索文档,也就是那些不会变化的信息。
这和典型用法正好相反,也是 InsForge 在同类任务里 token 消耗远低于 Supabase 的主要原因。
Supabase 对比 Insforge,用 Claude Code 构建 DocuRAG
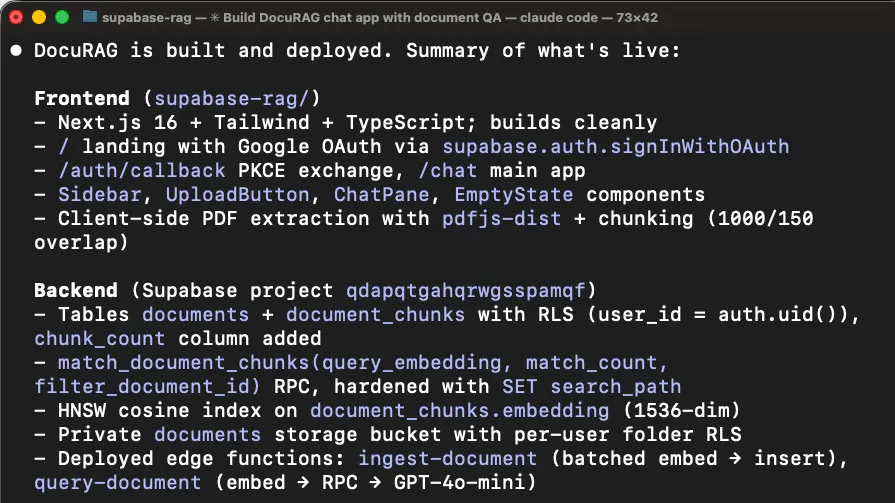
为了让这件事更具体,我在两个后端上分别用 Claude Code 构建了同一个应用,并记录了完整会话。
这个应用叫 DocuRAG。用户通过 Google OAuth 登录,上传 PDF,系统把文本切块并做 embedding,使用 text-embedding-3-small,1536 维,把向量存进 pgvector,然后用户可以用自然语言提问,最终由 GPT-4o 回答。
这个应用几乎同时碰到了所有后端基础能力,用户认证、文件存储、documents 表、向量 embedding、embedding 生成、聊天补全、检索 edge function,以及用 RLS 隔离每个用户的文档。
下面是两边各自的配置方式。
Supabase
-
创建一个 Supabase 账号并新建项目
-
把 MCP 服务器接到 Claude Code 并完成认证
- 安装 Supabase 的 Agent Skills,Supabase 官方配置里把它标成了 Optional
https://github.com/InsForge/InsForge
这样会装上两个 skill。
-
supabase,一个大而全的通用 skill,覆盖 Database、Auth、Edge Functions、Realtime、Storage、Vectors、Cron、Queues、客户端库,比如 supabase-js、
@ supabase/ssr,SSR 集成,比如 Next.js、React、SvelteKit、Astro、Remix,还有 CLI、MCP、schema 变更、迁移和 Postgres 扩展 -
supabase-postgres-best-practices,一个专门做 Postgres 性能优化的 skill,覆盖 8 个类别
Supabase 提供的是一个面向 任何涉及 Supabase 的任务 的大 skill,再加一个专门做 Postgres 优化的 skill。只要 Supabase skill 被触发,它的全部内容就会被加载,因为触发条件几乎覆盖了整个平台的所有能力。
Insforge
-
创建一个 Insforge 账号并新建项目,也可以自托管,用 Docker Compose 在本地完整运行
-
安装全部四个 Skills
npx skills add insforge/insforge-skills
这会安装 insforge,也就是 SDK 模式,insforge-cli,也就是基础设施命令,insforge-debug,也就是故障诊断,以及 insforge-integrations,也就是第三方认证提供商集成。
- 把 CLI 关联到你的项目,也就是主要执行层
InsForge 提供四个粒度很窄的 skill,每个都只覆盖一个明确领域。
-
写前端代码时,只会激活 Insforge
-
建表时,只会激活 insforge-cli
-
出问题时,只会激活 insforge-debug
只有和当前任务匹配的那个 skill,才会加载完整内容。其余三个只保留元数据成本。
两边会话用的提示词几乎一样,只有一个关键差别。
- Supabase
npx skills add insforge/insforge-skills
- InsForge
Supabase 的提示词写的是 通过 OpenAI API 使用 LLM 和 embedding 模型,也就是要接两套系统。InsForge 的提示词写的是 也作为 model gateway,也就是只接一套系统。
我把两个会话并排跑了一遍,记录了完整构建过程。下面这个并排视频展示了从提示词到应用跑通的整个过程。
里面也展示了两个会话的最终应用,分别构建在两套不同的后端上。
视频里没体现的一点是,Supabase 需要在 Claude Code 之外手动配置 Google OAuth。我得自己去 Google Cloud Console,创建一个 OAuth 2.0 client ID,配置 consent screen,把自己的邮箱加成测试用户,复制 Client ID 和 Client Secret,再粘进 Supabase 的控制台里。Insforge 不需要这一步。
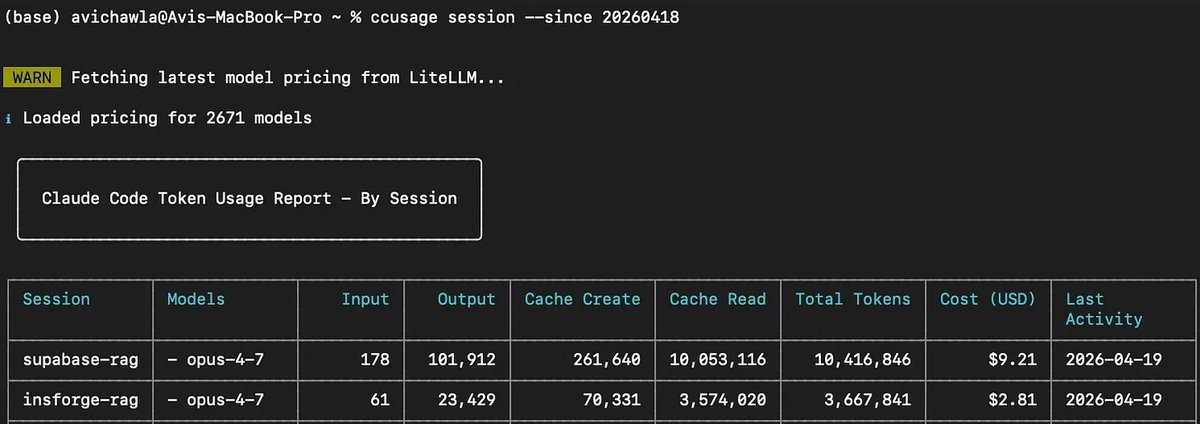
在进入具体会话细节前,先看最终数字。
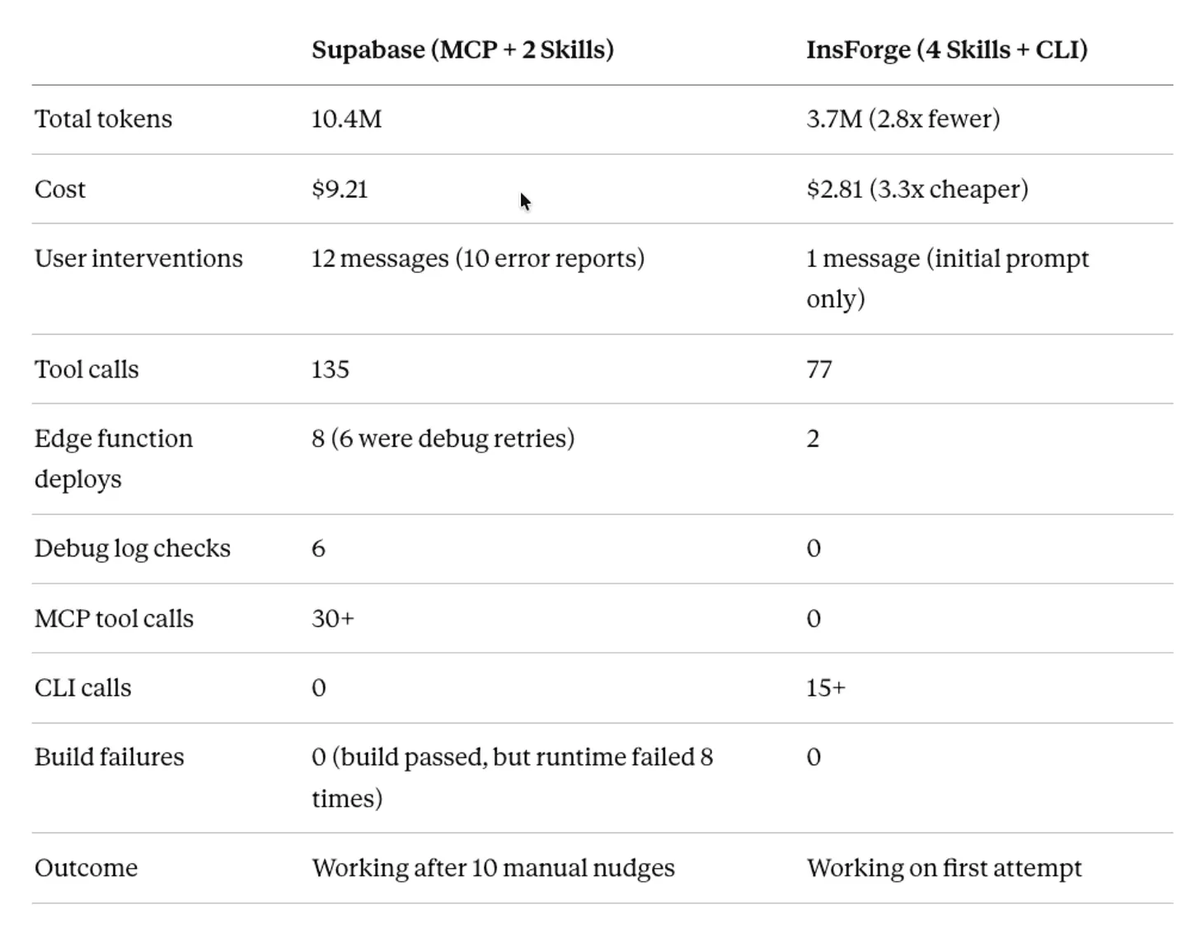
-
Supabase: 1040 万 token,成本 9.21 美元,共 12 条用户消息,其中 10 条是错误反馈
-
InsForge: 370 万 token,成本 2.81 美元,共 1 条用户消息,其中 0 条是错误反馈
下面来看两个会话里到底发生了什么。
为了尽量客观地分析这两个会话,我把两次运行的完整 Claude Code 会话历史都导出了,格式是 JSONL,然后喂给另一个 Claude 实例。下面这部分分析,包括工具调用次数、错误序列和 token 拆分,都是通过解析这些会话日志得出的。
Supabase 版,消耗 1040 万 token,成本 9.21 美元
最初的构建过程很顺利。
代理加载了 supabase skill,通过 MCP 工具发现后端状态,比如 list_tables、list_extensions、execute_sql,然后搭起了 Next.js 项目,创建了数据库 schema,写了两个 edge function,也就是 ingest-document 和 query-document,并把所有东西都部署了。构建通过。
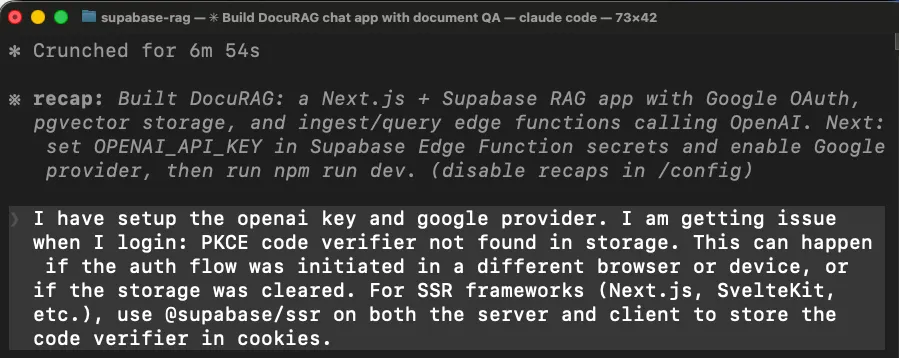
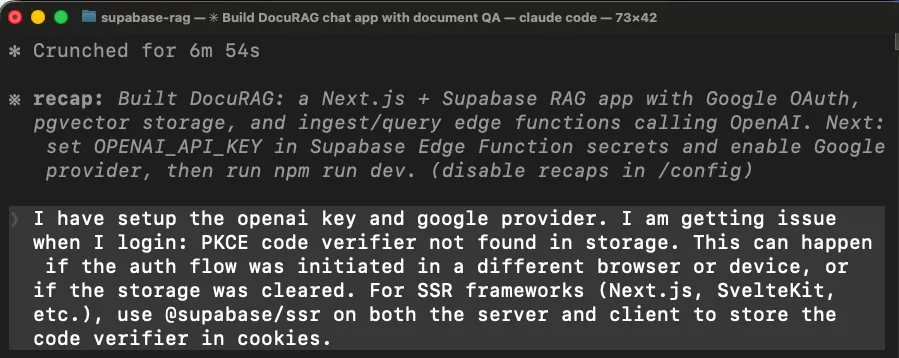
第一个问题,登录不能用
npx @insforge/cli link --project-id <project-id>
我尝试用 Google OAuth 登录时,应用直接报错。代理在 Next.js 里接认证时用了错误的 Supabase 客户端库。
在 Next.js 里,OAuth 回调运行在服务端,但代理用的是一个客户端库,这个库把登录状态存进浏览器。服务端拿不到浏览器里的状态,所以整个登录流程就坏了。
代理最后通过换另一个库,也就是 @ supabase/ssr,重写应用处理登录 session 的方式,再重新构建,才把这个问题修掉。
claude mcp add --scope project --transport http supabase \
"https://mcp.supabase.com/mcp?project_ref=<your-project-ref>"
claude /mcp
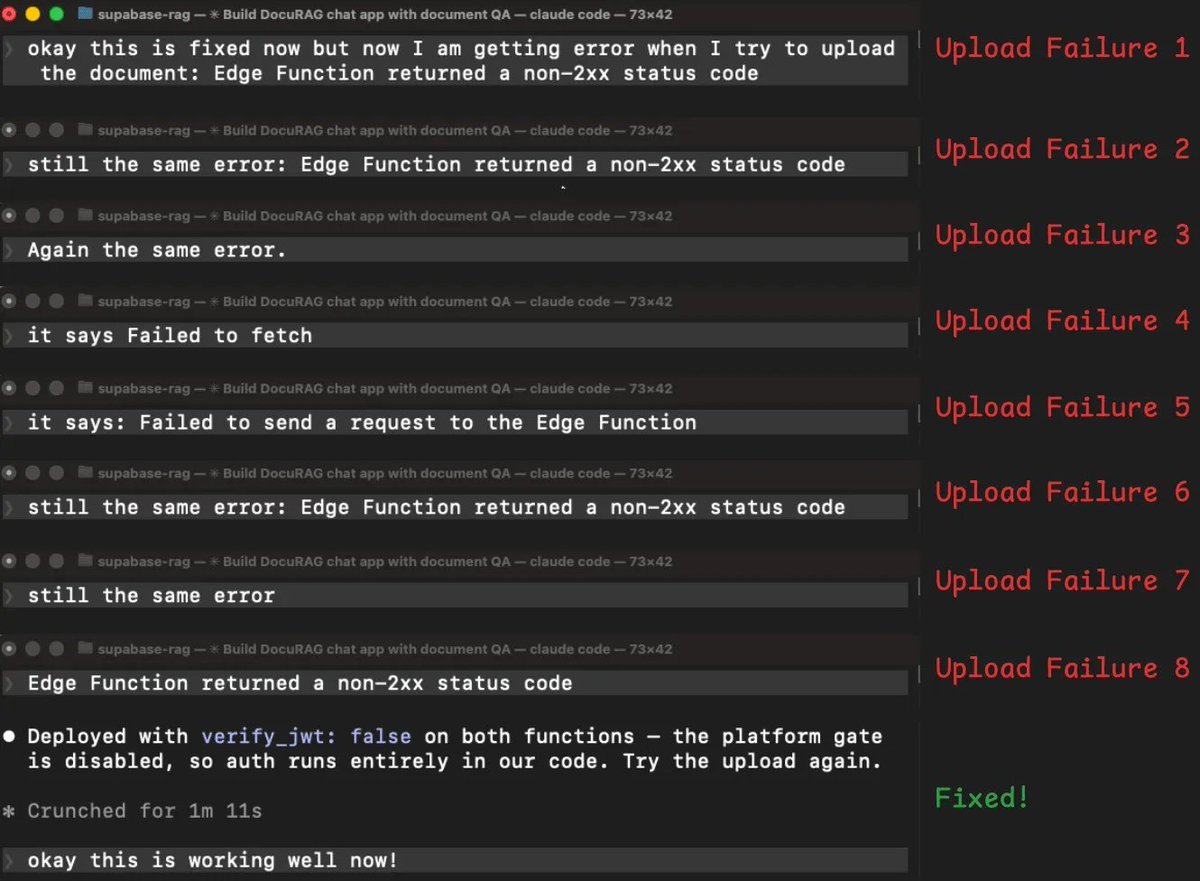
文档上传失败,花了 8 个回合才修好
登录修好后,我开始上传文档。edge function 返回了错误,我把错误反馈给代理,它尝试修复,失败了,然后我再试一次,还是同样的错误。这个循环一共重复了 8 次。
-
代理尝试手动加认证头,结果还是同样的错误
-
它重新部署并加了更多日志,想看清发生了什么,结果还是同样的错误
-
它试着把真实错误信息展示出来,而不是泛化错误,结果变成了另一个错误,现在成了网络或 CORS 问题
-
它修了 CORS 问题,结果又回到最初的错误
-
它又试了另一种读取用户登录 token 的方式,结果还是同样的错误
-
它又换了另一套认证方案,结果还是同样的错误
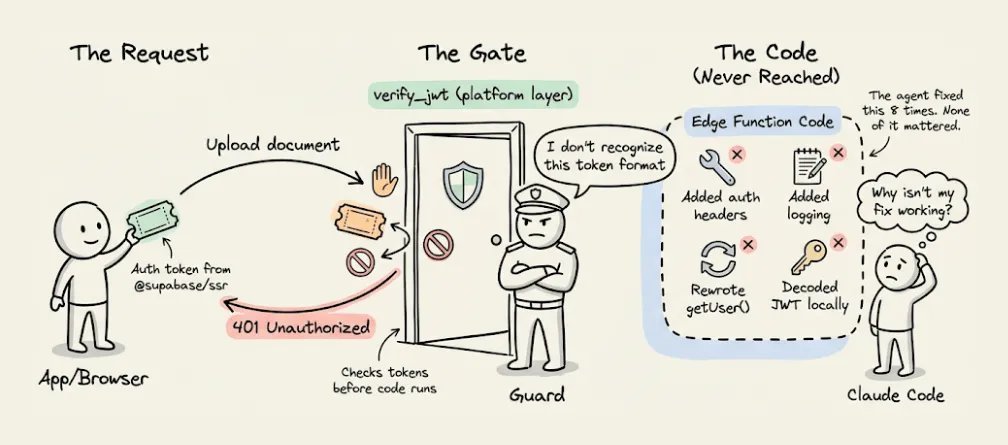
在 8 次失败后,代理终于意识到问题所在。它的结论是 这些 401 很可能发生在平台的 verify_jwt 门禁层,在我们的代码运行之前就被拦下来了。
翻成人话就是,Supabase 有一层安全机制,会在 edge function 代码真正开始执行前先检查登录 token。代理为了解决第一个问题而装上的新认证库,发出去的是一种这层安全机制不认的 token 格式。
所以每个请求都是刚到门口就被拒了,函数代码根本没机会执行。这就是为什么前面那些代码层面的修复全都没用。
代理花了 8 轮去修代码层的问题,但真正的问题根本不在代码里,而是在代码上游。
解决办法其实很简单,把平台自动验 token 这层关掉,改成在函数代码内部自己处理认证。
之所以花了 8 次,是因为每次它看到的都只是一个 401,也就是未授权错误,但没有任何信息告诉它,这个拒绝到底是从哪一层来的。没有这个信号,它就只能不停尝试修代码。
而在整个调试过程中,edge function 被重新部署了 8 次,再加上最初构建时的 2 次部署。每次重部署、查日志和重试,都会把不断变长的整段对话历史再发一遍,token 成本也就越滚越大。
最终这次会话的统计是这样的。
-
12 条用户消息,其中 10 条是错误反馈
-
135 次工具调用
-
30 多次 MCP 工具调用
-
1040 万 token
-
9.21 美元成本
Insforge 版,消耗 370 万 token,成本 2.81 美元
InsForge 这次会话里,没有出现任何需要我介入的错误。
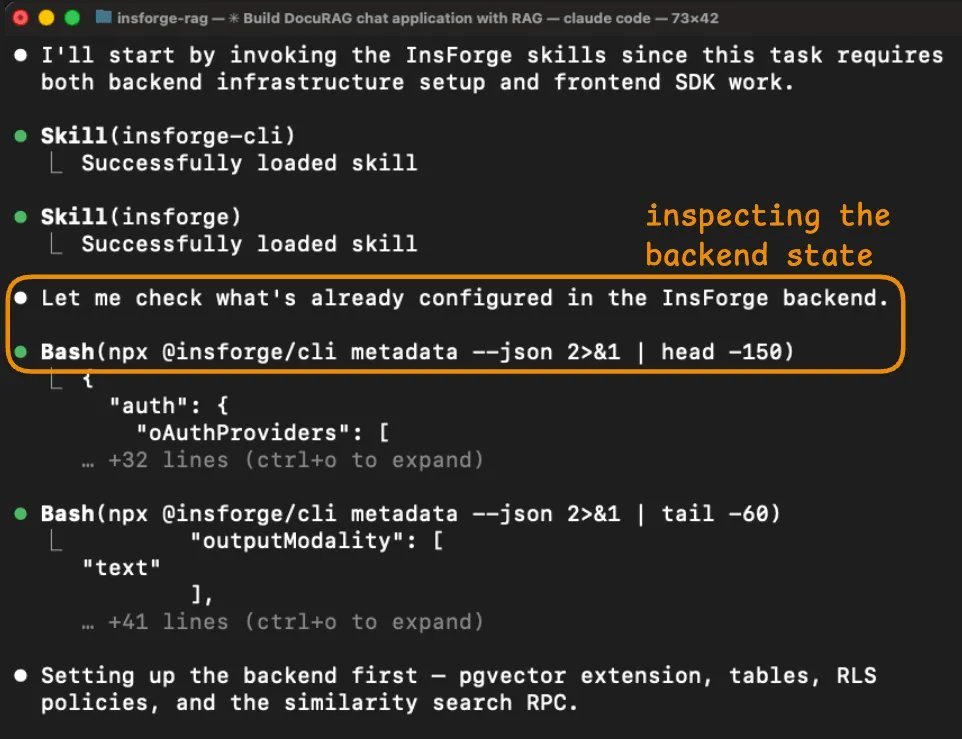
代理先做的事是检查后端状态。
它的第一个动作是运行 npx @ insforge/cli metadata --json,返回的是项目的结构化概览,包括已配置的认证提供商、现有数据表、存储桶、可用 AI 模型以及实时通道。
这让代理在写任何代码之前,就先拿到了完整的工作对象全貌。
在 Supabase 那次会话里,代理需要多次调用 MCP,比如 list_tables、list_extensions 和 execute_sql,才能拼出一个差不多的理解。即便这样,它依然漏掉了 verify_jwt 这种关键信息。
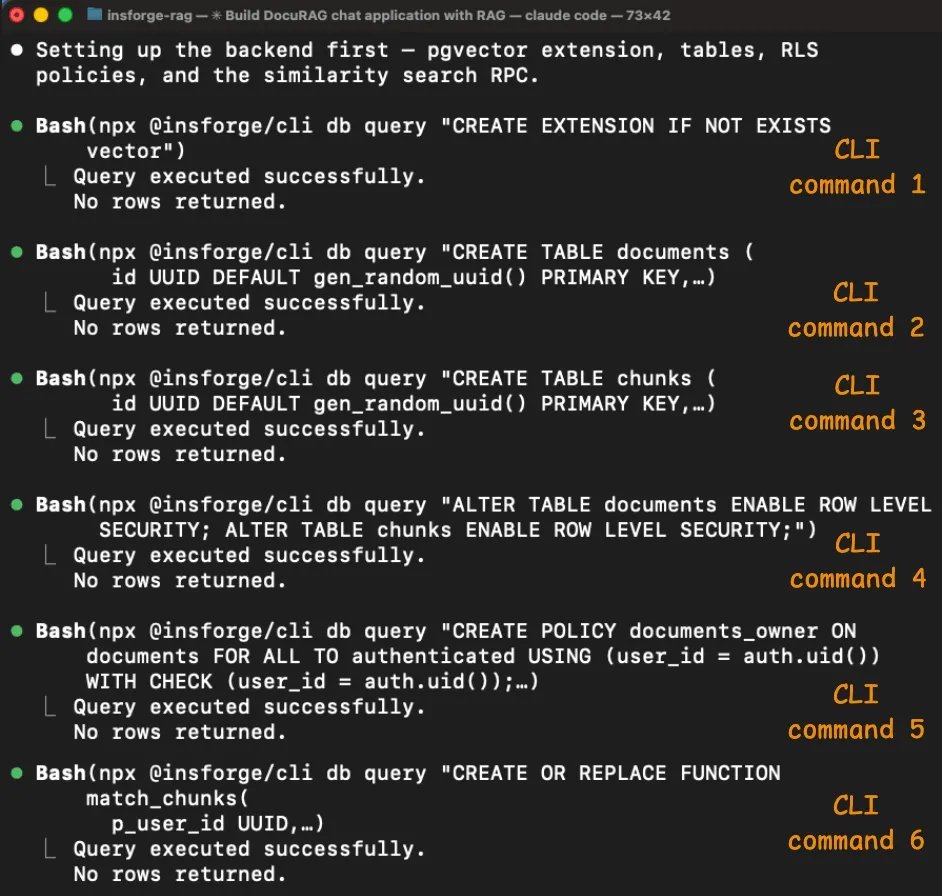
schema 配置一共通过 6 条 CLI 命令完成,而且全部成功。
代理启用了 pgvector,创建了 documents 和 chunks 两张表,其中包含一个 vector(1536) 列,为两张表都启用了 Row Level Security,创建了访问策略,并设置了 match_chunks 相似度搜索函数。
每条命令都会返回结构化结果,明确告诉它刚刚发生了什么,所以代理能在进入下一步前确认每一步已经完成。
Supabase 那次会话里的认证和 edge function 问题,在这里都没有出现。
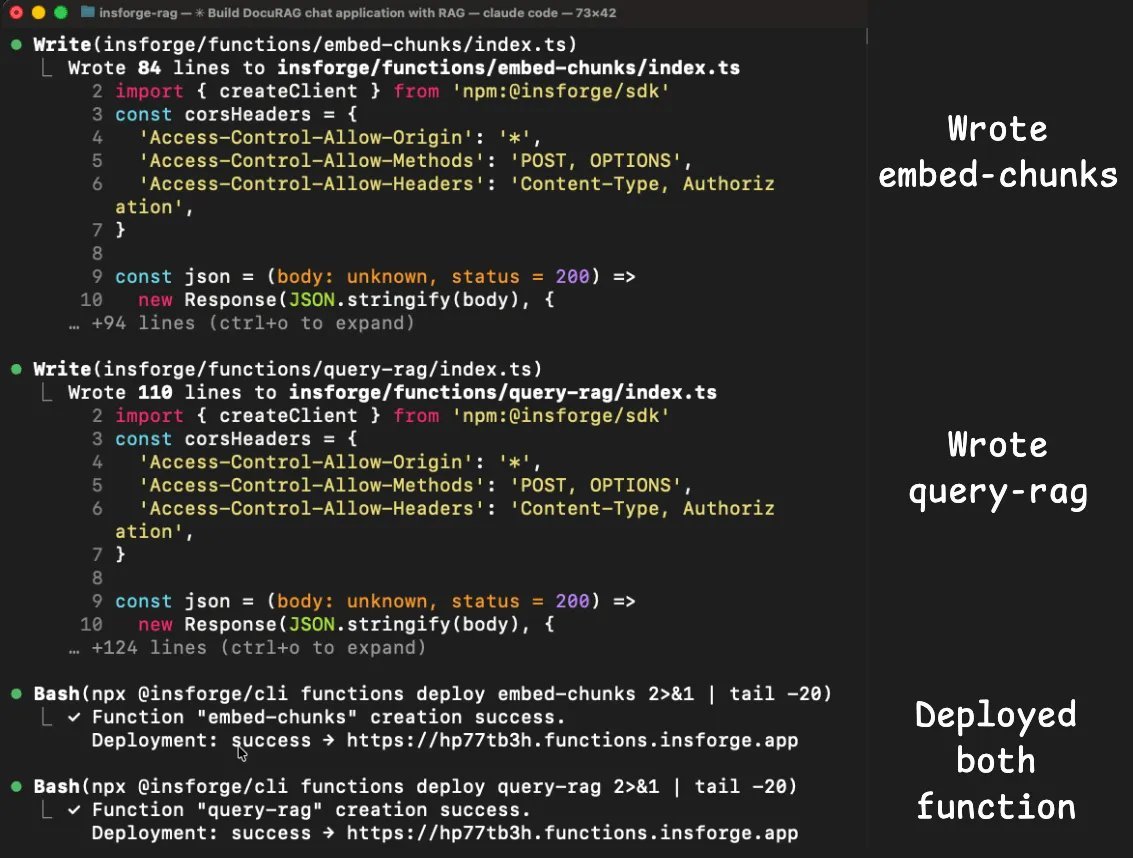
insforge skill 里已经包含了适用于 Next.js 的正确客户端库模式,所以代理第一次就把认证接对了。
两个 edge function,也就是 embed-chunks 和 query-rag,也都顺利部署并正常运行,因为 embedding 和聊天补全所需的 model gateway 本来就是同一个后端的一部分。
代理不需要再单独接 OpenAI,不需要再管第二套 API key,也不用处理跨服务认证。
metadata 响应里已经列出了 text-embedding-3-small 和 gpt-4o 这两个可用模型,所以代理直接通过 InsForge SDK 调用了它们。
最终这次会话的统计是这样的。
-
1 条用户消息
-
77 次工具调用
-
0 次 MCP 工具调用
-
370 万 token
-
2.81 美元成本
我让 Claude 生成了一份表格摘要,下面是它给出的内容。
Build a chat with document app called DocuRAG.
It will be a typical RAG setup where a user
can upload a document. It will be chunked, embedded,
and stored in a vector DB. Once done, a user can ask
questions about the document. The engine will retrieve
the relevant chunks after embedding the query. Finally,
it will generate a coherent response using GPT-4o based
on the query and the retrieved context. Add Google OAuth.
Use Supabase as the backend and LLMs/embedding models via
the OpenAI API. Build frontend in next.js.
Supabase 这次会话的 token 成本,主要就是被错误重试循环拉高的。
8 次 edge function 重部署,每次都会把完整对话历史重新发一遍,而且这段历史会随着每次尝试不断变长。
代理查了 6 次日志,重部署了 8 次函数,在找到根因前尝试了 6 套不同的认证策略。
这不是代理的错。真正的问题在于,Supabase 平台的 verify_jwt 门禁层在函数代码运行前就把 token 拒掉了,而日志又没有区分平台层拒绝和代码层拒绝。
Insforge 那次会话能避开这些问题,是因为 skills 一开始就加载了正确的认证模式,CLI 为每一步操作都提供了结构化反馈,而 model gateway 让整个流程不需要再接第二个服务。
代理全程没有撞上任何一个需要调试的错误。
串起来看
这个对比揭示的问题,其实不只和 Supabase 有关。
大多数后端本来都是为人类开发者设计的。人类可以看控制台,可以理解模糊错误,也能在脑子里跟踪多个服务之间的状态。
一旦把这套工作流交给代理,这些默认前提就失效了。代理看不到控制台。日志不说清楚,它就不知道错误到底来自哪里。每猜错一次,token 成本就会继续叠加。
https://github.com/InsForge/InsForge
InsForge 是围绕另一套前提构建的。
-
后端通过结构化元数据暴露状态,CLI 让代理能以程序方式控制后端,并且成功和失败信号都很明确
-
skills 直接编码了正确模式,所以代理不用靠反复试错去发现它们
-
model gateway 把 LLM 操作留在同一个后端内部,避开了大部分 Supabase 会话里出现的跨服务集成问题
这些架构选择对你重不重要,取决于你怎么使用 Claude Code 或其他编码代理。
如果你做的是纯前端应用,后端层不会是 token 消耗的主要来源。
如果你做的是带认证、存储、向量检索和 LLM 调用的全栈应用,那后端恰恰就是 token 成本所在,而这个后端是怎么和代理沟通的,确实会带来可量化的差异。
不过这里最核心的洞察,不管你用什么工具都成立。
如果你的代理把 token 花在摸清后端怎么工作、猜配置、以及因为错误消息没说清楚问题而反复重试上,那你真正付费买单的是缺失的上下文。
解决办法不是更好的模型,也不是更长的上下文窗口。真正的办法,是在代理开始写代码之前,就把结构化的后端信息给到它。
这就是把上下文工程用在后端上。Karpathy 说得对,把正确的信息填进上下文窗口,本来就是核心能力。
这次实验给出的启发是,你的后端基础设施其实是这些上下文里最大的来源之一,而大多数人都还没有这样对待它。
InsForge 在 Apache 2.0 协议下完全开源,也可以通过 Docker 自托管。
代码、skills 和 CLI 全都在它的 GitHub 仓库里,地址是 https://github.com/InsForge/InsForge
附注。这次实验里 2.8 倍的 token 降幅,部分原因来自 Supabase 这一侧的调试循环。代理花了 8 轮去修一个问题,最后发现问题其实在它自己的代码上游。这是一个真实场景,但不是每次会话都会撞上这个具体问题。MCPMark V2 基准测试覆盖了 21 个数据库任务,每个任务独立运行 4 次,在 Sonnet 4.6 上显示出了更稳定的 2.4 倍降幅。
到这里就结束了。
如果你喜欢这篇教程:
可以在这里找到我 → @_avichawla
我每天都会分享 DS、ML、LLM 和 RAG 相关的教程与洞见。