如果你觉得这篇文章有意思,我很想听听你的想法。欢迎在 Twitter、LinkedIn 上分享,或通过 guptaamanthan01[at]gmail[dot]com 与我联系。

链接:http://x.com/i/article/2032398255095730177
Karpathy的Autoresearch证明了最好的自主系统不是自由度最大的,而是约束最严苛、框架最强健的——这对所有需要持续优化的系统都有启示。
打开原文 ↗
如果你觉得这篇文章有意思,我很想听听你的想法。欢迎在 Twitter、LinkedIn 上分享,或通过 guptaamanthan01[at]gmail[dot]com 与我联系。
链接:http://x.com/i/article/2032398255095730177

Most "autonomous AI research" demos look impressive for the same reason magic tricks do: you only see the interesting part. An agent edits some code, runs an experiment, and shows a better result. What you usually do not see is the part that actually determines whether the system is useful: what is the harness optimizing for, how stable is the evaluation, and what happens when the agent fails?
大多数“自主 AI 研究”的演示之所以看起来惊艳,原因和魔术一样:你只看到了精彩的那一段。一个智能体改了点代码、跑了个实验、展示更好的结果。你通常看不到的,是那些真正决定系统是否有用的部分:这套框架在优化什么、评估有多稳定、以及当智能体失败时会发生什么?
That is why Karpathy's Autoresearch is worth paying attention to.
这也正是 Karpathy 的 Autoresearch 值得关注的原因。
Autoresearch is not trying to be a general-purpose AI scientist. It is a small, tightly constrained system for one specific job: let an agent modify a training script, run a bounded experiment, measure the result, keep the change if it helps, and discard it if it does not. The repo is tiny, but the design behind it is one of the cleanest examples I have seen of how to build a useful autonomous improvement harness.
Autoresearch 并不试图成为通用的 AI 科学家。它是一个小而紧约束的系统,只为一件特定的事服务:让智能体修改训练脚本,跑一个有边界的实验,测量结果,如果有帮助就保留变更,没有帮助就丢弃。仓库很小,但其背后的设计,是我见过最清晰的示例之一,展示了如何构建一个真正有用的自主改进框架。
In this blog post, I will break down how Autoresearch works, and more importantly, what it teaches us about building reliable agentic systems.
在这篇文章里,我将拆解 Autoresearch 的工作原理;更重要的是,它对构建可靠的智能体系统有什么启示。
At a high level, Autoresearch turns "AI research" into a bounded optimization problem.
从高层看,Autoresearch 把“AI 研究”变成了一个有边界的优化问题。
The agent is not browsing papers, forming original theories, or deciding what science should matter. Its job is much narrower:
这个智能体不会去翻论文、提出原创理论,也不会决定哪些科学问题重要。它的任务要窄得多:
That framing matters. Instead of treating research as an open-ended creative task, Autoresearch treats it as a disciplined search harness over a well-defined surface.
这种问题定义很关键。Autoresearch 不把研究当作无限开放的创作任务,而是把它当作在一个定义明确的搜索空间上运行的、纪律严明的搜索框架。
The setup is deliberately minimal. The agent is allowed to modify only one file, train.py. Data preparation, tokenization, and evaluation are kept outside the search space. That one decision does a lot of work. It keeps the harness focused, keeps diffs reviewable, and prevents the agent from "improving" the system by changing the benchmark in the background.
这个设置刻意保持极简。智能体只被允许修改一个文件:train.py。数据准备、分词(tokenization)和评估都被排除在搜索空间之外。这个决定发挥了巨大的作用:它让框架保持聚焦,让 diff 易于审查,并防止智能体在后台悄悄更改基准测试,从而“改进”系统。
There is another subtle idea here too. The real control plane of the repo is not just the Python code. It is program.md, the file that tells the agent how to behave. In other words, the human is not only programming the model. The human is programming the researcher.
这里还有一个更微妙的想法:这个仓库真正的控制面(control plane)不仅仅是 Python 代码,而是 program.md——那份告诉智能体该如何行动的文件。换句话说,人类不只是给模型写程序,人类是在给“研究员”写程序。
Autoresearch revolves around three files: program.md, prepare.py, and train.py.
Autoresearch 围绕三个文件展开:program.md、prepare.py 和 train.py。
program.md is the operating manual for the agent. It tells the agent how to set up a run, what files are in scope, what it is allowed to modify, how to log experiments, when to keep or discard a commit, and how to recover from crashes. This is what makes the harness operationally disciplined rather than just clever in theory.
program.md 是智能体的操作手册。它告诉智能体如何启动一次运行、哪些文件在范围内、允许修改什么、如何记录实验、何时保留或丢弃一个 commit,以及如何从崩溃中恢复。正是这些规定,让框架在运维上具备纪律性,而不只是理论上聪明。
prepare.py is the fixed harness. It downloads the dataset shards, trains the tokenizer, builds the dataloader, and defines evaluation. The most important choice here is the metric: Autoresearch evaluates models using bits per byte (val_bpb) rather than raw validation loss. That makes results more comparable across tokenizer changes, because the denominator is byte length instead of token count. Just as importantly, the agent is not allowed to modify this file, which means the benchmark stays stable.
prepare.py 是固定不变的框架。它下载数据集分片、训练 tokenizer、构建 dataloader,并定义评估方式。这里最重要的选择是指标:Autoresearch 用 每字节比特数(val_bpb,bits per byte)而不是原始的验证损失来评估模型。这让不同 tokenizer 改动下的结果更可比,因为分母是字节长度而不是 token 数。更重要的是,智能体不被允许修改这个文件,这意味着基准保持稳定。
train.py is the search surface. It contains the model, optimizer, schedules, hyperparameters, and the training logic itself. This is where the agent experiments. It can change architecture, optimizer settings, depth, batch size, and training behavior, but it has to do all of that within one bounded file.
train.py 是搜索空间本身。它包含模型、优化器、各类调度(schedules)、超参数,以及训练逻辑本身。智能体的实验都发生在这里:它可以调整架构、优化器设置、深度、batch size 和训练行为,但必须把这一切都限制在这一个文件之内。
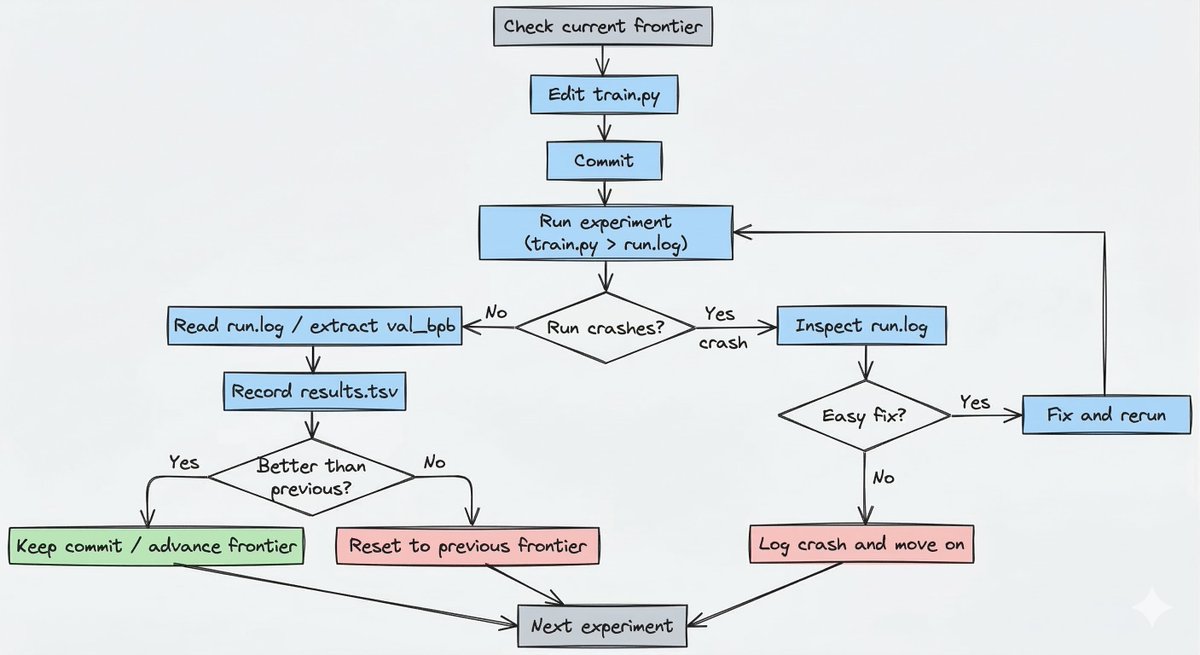
The recurring experiment harness looks like this:
反复运行的实验框架大致如下:
That is the outer harness, including the keep/reset path and the crash-handling branch. Inside each run, train.py has its own training logic, but the repo's real autonomous behavior lives in this experiment cycle.
这就是外层框架:包含“保留/重置”的路径,以及处理崩溃的分支。在每次运行内部,train.py 负责具体的训练逻辑;但这个仓库真正的自主行为,体现在这套实验循环里。
First, every run gets the same wall-clock budget: 5 minutes. That means the question is not "what model is best after N steps?" It is "what configuration gives the best result within this exact amount of time on this machine?" That is a much more useful objective for autonomous iteration, because it forces the system to optimize for improvement per unit time, not just abstract model quality.
第一,每次运行都被分配同样的实际时间预算:5 分钟。这意味着问题不再是“跑 N 步之后哪个模型最好?”,而是“在这台机器上、在完全相同的时间内,哪种配置能给出最好的结果?”对自动迭代来说,这是更有用的目标,因为它迫使系统优化单位时间内的改进幅度,而不仅是抽象的模型质量。
Second, every experiment starts from the current frontier. The agent checks the current branch or commit, edits train.py, commits the change, runs uv run train.py > run.log 2>&1, and then reads the metric back out of the log. If the result is better, that commit becomes the new frontier. If it is equal or worse, the branch resets back to where it started. This keep or reset mechanism makes the branch behave like an evolutionary search path instead of a pile of speculative edits.
第二,每个实验都从当前的“前沿”(frontier)出发。智能体检查当前分支或 commit,编辑 train.py,提交改动,运行 uv run train.py > run.log 2>&1,然后从日志里读回指标。如果结果更好,这个 commit 就成为新的前沿;如果持平或更差,分支就重置回起点。这套“保留或重置”的机制,让分支像一条演化式的搜索路径,而不是一堆投机性的修改。
Third, results are logged in results.tsv, but that file stays outside git history. Git stores the winning line of code evolution. The TSV stores the broader operational history, including discarded runs and crashes.
第三,结果会记录在 results.tsv 里,但这个文件不进入 git 历史。Git 保存的是胜出那条代码演化路径;TSV 则保存更完整的运行历史,包括被丢弃的尝试和崩溃记录。
Finally, the harness assumes that failures will happen. Some experiments will produce NaNs. Some will OOM. Some will simply break the script. The instructions explicitly tell the agent to inspect run.log, attempt an easy fix if the problem is trivial, and otherwise log the crash and move on. That is a big reason the project works conceptually: it is designed for unattended operation, not just successful demos.
最后,这个框架默认失败一定会发生。有的实验会产出 NaN,有的会 OOM,有的干脆把脚本跑坏。说明文档明确要求智能体检查 run.log:如果问题很简单就尝试快速修复;否则就记录崩溃并继续前进。这正是这个项目在概念上能够成立的重要原因:它是为无人值守运行而设计的,而不是只为成功的演示而设计。
Autoresearch matters because it demonstrates a broader truth about agents: autonomy gets useful when the harness is tight.
Autoresearch 之所以重要,是因为它展示了关于智能体的一个更普遍的事实:当外部框架足够紧致时,自主性才会变得真正有用。
The first lesson is that constraints make agents better. The agent edits one file, chases one metric, operates within one fixed harness, and advances only when the score improves. That is not a drawback of the system but the reason the system can run for hours without dissolving into noise. Many agent systems fail because they maximize freedom too early. More freedom usually means a larger error surface.
第一课是:约束会让智能体更强。它只改一个文件,只追一个指标,在固定框架内工作,并且只有当分数提升时才推进。这不是系统的缺陷,恰恰是它能连续运行数小时而不沦为噪声的原因。很多智能体系统失败,是因为过早地最大化自由度;自由度越大,通常意味着错误表面越大。
The second lesson is that prompts are part of the architecture. In Autoresearch, program.md is not fluff around the code. It defines workflow, boundaries, persistence, logging, recovery, and selection criteria. That is system design, not just prompting. As agentic products mature, more of the real architecture will live in this layer: not only application code, but operating instructions for autonomous workers.
第二课是:prompt 本身就是架构的一部分。在 Autoresearch 里,program.md 不是代码旁边的装饰文本;它定义了工作流、边界、持久化、日志、恢复机制以及选择标准。这是系统设计,而不只是写 prompt。随着智能体产品成熟,越来越多真正的“架构”会沉淀在这一层:不仅是应用代码,还有给自主工作者的操作指令。
The third lesson is that you should optimize the harness, not just the model. A lot of builders focus on model intelligence in isolation. Autoresearch shows that the surrounding machinery matters just as much: how work is launched, how failures are handled, how progress is measured, how bad paths are rolled back, and how state is recorded. A mediocre agent inside a strong harness can outperform a stronger agent inside a messy one.
第三课是:你应该优化框架,而不只是优化模型。很多构建者只盯着模型本身的智能水平。Autoresearch 表明,周边机制同样关键:任务如何启动、失败如何处理、进展如何度量、坏路径如何回滚、状态如何记录。把一个普通的智能体放进强健的框架里,往往能胜过把更强的智能体放进混乱的框架里。
The fourth lesson is that time-bounded evaluation is underrated. The 5-minute wall-clock budget is one of the best ideas in the repo. In real systems, time is often the true constraint: latency, compute, iteration speed, or user patience. Time-bounded loops force the system to optimize for real-world usefulness instead of idealized performance.
第四课是:时间受限的评估被严重低估。这仓库里“5 分钟实际时间预算”是最好的点子之一。在真实系统中,时间往往才是真约束:延迟、算力、迭代速度,或用户的耐心。时间受限的循环迫使系统优化面向现实的可用性,而不是理想化的性能。
The fifth lesson is that reversibility and observability are non-negotiable. Autoresearch keeps losers cheap to discard and makes every experiment inspectable through logs, commit history, and results.tsv. That is exactly how agentic systems should be designed. If a bad run leaves the system in an unrecoverable mess, the agent cannot explore aggressively. If the system gives you no trace of what happened, you cannot trust it or improve it.
第五课是:可逆性与可观测性没有商量余地。Autoresearch 让失败代价极低(随时可丢),并通过日志、commit 历史和 results.tsv 让每次实验都可检查。这正是智能体系统应有的设计方式:如果一次糟糕的运行就把系统搞到无法恢复,智能体就不敢大胆探索;如果系统不给你任何痕迹,你既无法信任它,也无法改进它。
Taken together, these choices point to a bigger principle: the best autonomous systems are not the ones with the most freedom. They are the ones with the clearest objective, the strongest harness, and the cheapest failure mode.
综合来看,这些选择指向一个更大的原则:最好的自主系统不是自由度最大的那种,而是目标最清晰、框架最强健、失败成本最低的那种。
Autoresearch is a strong design, but it remains narrow.
Autoresearch 的设计很强,但它依然是一个很“窄”的系统。
The first limitation is that it optimizes a local benchmark. The agent is trying to improve val_bpb under a fixed 5-minute budget on a specific setup. That does not automatically mean it is discovering generally superior training strategies. It may be finding what works best under this particular harness.
第一,它优化的是一个局部基准。智能体是在特定配置上、固定 5 分钟预算内,努力提升 val_bpb。这并不自动意味着它发现了普遍更优的训练策略;它也可能只是在这套特定框架下找到了最有效的做法。
The second limitation is hardware. The project is built around a single NVIDIA GPU and works best on high-end hardware. The README points to forks and parameter changes for smaller machines, but the default experience is clearly shaped around a powerful CUDA setup.
第二,是硬件限制。这个项目围绕一张 NVIDIA GPU 设计,在高端硬件上效果最好。README 提到了适配小机器的 fork 和参数调整,但默认体验显然是以强力的 CUDA 环境为前提塑造的。
The third limitation is also its strength: Autoresearch is autonomous only inside a human-designed sandbox. The human defines the metric, the files in scope, the data pipeline, and the operating instructions. That does not make the system less interesting. If anything, it makes it more realistic. Near-term autonomous systems are most useful when they operate inside strong scaffolding, not when they are given open-ended freedom and vague goals.
第三个限制也恰恰是它的优势:Autoresearch 的自主性只存在于人类设计的沙盒之内。指标是什么、哪些文件在范围内、数据流水线怎么走、以及操作指令如何写,都是由人类定义的。这并不会让系统变得不那么有趣;相反,它让系统更现实。近期的自主系统,往往在强脚手架(scaffolding)内运行时最有用,而不是在开放式自由与模糊目标里漫无边际地行动。
Karpathy's Autoresearch is interesting not because it proves that we now have autonomous AI scientists. It proves something more practical: autonomous systems become much more useful when you reduce them to a tight harness with clear boundaries, a stable metric, reversible experiments, and good operational discipline.
Karpathy 的 Autoresearch 之所以有趣,并不是因为它证明了我们已经拥有“自主 AI 科学家”。它证明的是更务实的一点:当你把自主系统收敛为一个紧致的框架,具备清晰边界、稳定指标、可逆实验以及良好的运维纪律时,它会变得有用得多。
That is the real lesson of the repo.
这就是这个仓库真正的启示。
The impressive part is not that an agent can edit training code. Plenty of agents can do that. The impressive part is that the environment is designed so those edits become measurable, discardable, and repeatable over long periods without babysitting the run.
令人惊艳的并不是智能体能编辑训练代码——能做到这一点的智能体很多。真正令人惊艳的是:环境被设计得足够好,以至于这些编辑在长期无人盯守的运行中,能够被度量、被丢弃、并且可重复。
If you are building agents, that is the takeaway worth stealing. Do not start by asking how to make the agent more autonomous. Start by asking how to make the harness more reliable.
如果你在做智能体,这就是最值得“偷走”的结论:不要一上来就问如何让智能体更自主;先问如何让框架更可靠。
Because in practice, the best autonomous systems are rarely the most open-ended ones.
因为在实践中,最好的自主系统很少是最开放的那一种。
They have the most stringent constraints.
它们拥有最严苛的约束。
Read more such articles from me at https://manthanguptaa.in/
想读我更多类似的文章,请访问 https://manthanguptaa.in/
If you found this interesting, I would love to hear your thoughts. Share it on Twitter, LinkedIn, or reach out at guptaamanthan01[at]gmail[dot]com.
如果你觉得这篇文章有意思,我很想听听你的想法。欢迎在 Twitter、LinkedIn 上分享,或通过 guptaamanthan01[at]gmail[dot]com 与我联系。
Link: http://x.com/i/article/2032398255095730177
链接:http://x.com/i/article/2032398255095730177
If you found this interesting, I would love to hear your thoughts. Share it on Twitter, LinkedIn, or reach out at guptaamanthan01[at]gmail[dot]com.
Link: http://x.com/i/article/2032398255095730177
讨论进行中…