
- 类别
- 产品
Claude Code * 日期
2026 年 6 月 3 日 * 阅读时长
5
分钟 * 分享
https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
许多数据科学和数据工程团队都深有体会,推动自助式商业分析这件事,传统上一直都很磨人。
为了让技术背景较弱的同事更容易使用数据模型,团队通常会采用更宽表、去规范化的表结构。可随着业务扩张,这往往会带来定义不一致、彼此重叠的视图。而且,对那些并不想学 SQL 的员工来说,这也并不能真正填平门槛。另一种做法是给用户建立更多隔离环境,但这通常覆盖不了那些零散而长尾的业务问题,还会导致指标和仪表板不断膨胀,因为各团队都在各自为战。
LLM 的兴起,为自助式分析提供了另一条路,能避开这些问题。不过,如果只是把 Claude 指向数据仓库,然后放手让 agent 执行,很容易产生一种虚假的精确感。
刚开始,团队会为终于摆脱各种临时分析请求而兴奋。可很快,这种轻松会变成焦虑,因为你会发现,这种方式把业务相关方和底层基础设施、文档以及专家经验隔开了。而过去,正是这些东西在引导他们使用那些经过精心治理的数据集。
在 Anthropic,95% 的商业分析查询都通过 Claude 自动完成,整体准确率约为 95%。把这些机械、重复的工作交给 Claude 后,数据科学团队就能把精力放在更有战略价值的事情上,比如因果建模、预测和机器学习。
我们和数十位 Anthropic 内部顶尖的 Claude Code 用户做过交流,也见过大量分析 agent 的设计模式。基于这些经验,我们总结出了一些最佳实践,想分享给其他正在把 LLM 用于数据分析的数据团队。在这篇文章里,我们会讲到这些方法,帮助你尽可能发挥 Claude 在自助式商业洞察中的作用,包括:
- 为什么分析准确性本质上是上下文和验证问题,而不是代码生成问题
- 导致大多数错误的三种失效模式
- 我们为解决这些错误搭建的 agent 化分析栈
- 我们如何衡量效果
- 我们为大多数 skill 设计的一个基础模板(见附录)
数据不是软件
LLM 的生成能力是一把双刃剑。那些能让模型对复杂问题给出创造性方案的机制,也同样会让它凭空编出错误结果。要真正理解分析 agent 面临的挑战,把它和编码 agent 做个对比会很有帮助。
编码面对的是一个开放式问题空间,模型的创造力在这里会得到奖励。而文档和测试天然就能给幻觉问题加上护栏。相比之下,在分析场景里,通常只有一个正确答案,对应一个正确数据源,而且没有一种确定性的方法能证明这个答案就是对的。

对于自助式、agent 化的商业分析来说,复杂性主要来自数据本身的歧义。核心问题归根结底是我们的能力,能否把用户的问题映射到数据模型里具体、最新的实体上,并知道该怎样正确使用它们。如果这一步能做好,后面的执行和 SQL 其实就变得很简单。
我们识别出这个问题的三个特征,它们造成了绝大多数不准确的回答:
-
概念 <> 实体歧义:在一个数据模型里,往往有数百个可选项可用来回答问题,而潜在字段可能多达数百万。agent 无法选出最适合回答用户问题的正确字段。比如要衡量活跃用户数,什么行为算活跃。是否要排除欺诈用户。回看窗口该设多长。
-
数据陈旧:数据源、业务定义和 schema 都在不断变化。资产和 agent 的知识会逐渐过时,最后开始给出那些看起来没问题、其实 subtly 错掉的答案。
-
检索失败:正确的信息其实可能已经存在于数据模型中,也被正确标注过了,但因为搜索空间太大,agent 还是没能把它找出来。
未找到任何条目。
0/5
获取 Claude Code
电子书

我们的 agent 化分析栈
在 Anthropic,我们减少这三类错误的主要方式,就是搭建一套 agent 化数据栈。每一层的存在,主要都是为了对付这些问题中的一个或多个:
-
实体歧义:通过数据基础层和事实来源层,把可能的实体空间不断缩小,直到只剩下一个受治理的标准答案。
-
陈旧问题:通过维护和验证流程,避免系统随着业务变化慢慢腐坏。
-
检索失败:通过 skill,确保 agent 能稳定找到这个答案,并且正确使用它。
这一节里,我们会讲讲每一层是怎么搭建的。

数据基础层
想让分析 agent 足够准确,最重要的一点就是打好数据基础。这包括数据仓库中的数据模型、转换逻辑、测试、表,以及描述它们的元数据。像维度建模、左移测试、关键流水线的新鲜度和完整性检查,这些标准的数据工程和数据质量实践依然完全适用,我们这里就不再重复展开。
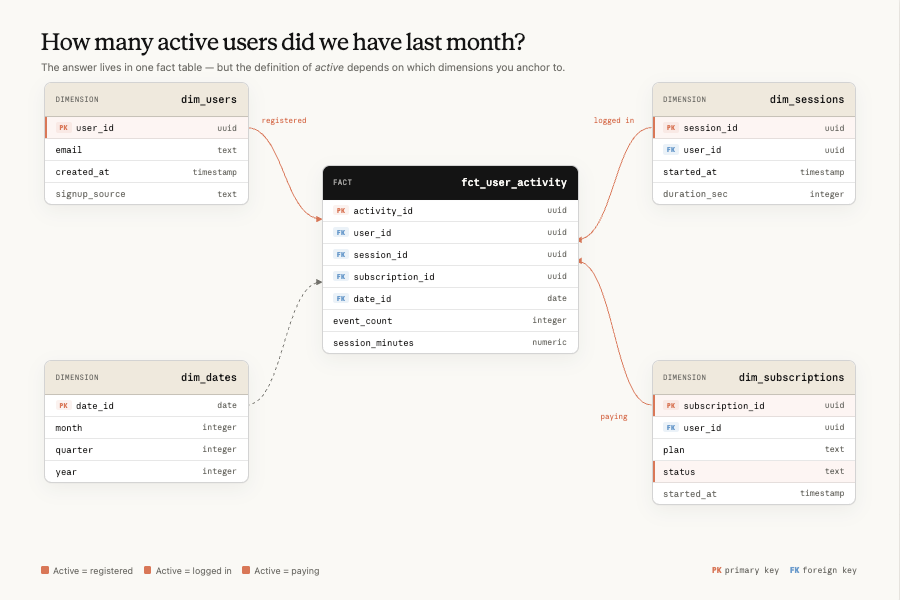
像维度建模这样的标准数据工程实践,重要性一点都没有降低。
真正变化的是,你的数据模型的最终使用者不再是数据专家,比如数据科学家,而是代表不同用户执行任务的 agent。这些用户对数据的理解程度,对底层基础设施的了解程度,都可能差别很大。这个变化带来一个挑战,结果不能指望由用户自己来验证底层是否正确,因为最终用户根本不懂这些。
数据基础层主要针对的是歧义问题。比如说,如果 revenue 最终只会落到一个受治理的数据集上,而不是四十个看起来都像那么回事的候选项上,那么问题在 agent 开始搜索之前,基本就已经被解决了。这里也是防止陈旧问题的第一道防线,因为定义标准模型的同一个 repo,本来就是最自然的地方,用来保证它们始终保持最新。
我们发现,有几种做法特别有效:
- 创建规范数据集:最常见的失败情况,是 agent 无法把一个概念,比如产品 X 的收入,映射到唯一正确的表、列和指标定义上。通常是因为存在多个看起来都合理、但实现上略有差别的候选项。解决办法是减少逻辑模型数量,并加强治理。整理出一小组规范化、单一事实来源的数据集,它们要有明确归属、可直接消费、易于发现,然后积极淘汰那些几乎重复的版本。为了成本和性能,物理聚合表和缓存依然有价值,但它们应该机械地从规范模型派生出来,而不是和规范模型并列,变成另一种可选答案。目标是,当 agent 搜索某个概念时,只能找到一个受治理的标准答案。
- 强制执行你的标准:我们的经验是,只有当规范模型和指标定义通过 tooling 被强制执行时,这些基础层才真正站得住。也就是说,agent 在结构上会被优先路由到它们上面。通过 CI,任何绕开它们的改动都无法通过 review。再通过 mandate,要求下游团队必须构建在受治理层之上,否则就解释原因。如果没有这些强制手段,治理很快就会退化回多候选项并存的问题。
- 把工件放在一起:我们应对数据模型和业务逻辑不断变化的主要防线,是把相关东西放在一起。几乎所有数据代码,也就是建模、语义层、参考文档、规范仪表板定义,都放在同一个 repo 中,并由 CI 检查来保证跨层完整性。如果一次建模改动会破坏下游仪表板,或者让某个已记录的指标失效,CI 就会把它标出来,修复会在同一个 PR 里一起交付。(我们会在下面的 Skills 一节里回到这部分机制。)
- 把元数据当成一等产品来对待:编码 agent 表现好,部分原因在于代码库 可读,有 README、类型签名、docstring 等等。你的数据仓库也同样可以做到可读,但前提是列和表的描述、规范指标定义、粒度文档、有效值范围、血缘、归属、模型分层,都要像对待转换逻辑本身那样认真维护。这不算什么新观点,但良好的治理确实能提供关键上下文,帮助 agent 选对数据集。
事实来源
如果说数据基础层就是数据仓库本身,那么事实来源层就是 agent 用来理解和导航这个仓库的参考界面。这一层能减少概念 <> 实体之间的歧义,把业务相关方口中的每周活跃用户,落到数据模型里一个具体、受治理的实体上。按信任程度大致从高到低,依次是:
- 语义层: 编译后的指标和维度定义。如果一个问题能直接映射到某个已定义指标,agent 只需要调用一个函数,就能得到一个数字,而且这个数字和公司里其他所有界面看到的都一样。我们的 agent 在结构上被 强制要求 优先使用语义层,这通过 skill 指令来实现(见附录)。有一个我们试过但 没成功 的想法,是让 LLM 从原始表和查询日志中自动生成指标定义,用这种方式来启动语义层。结果生成出来的定义看上去挺像回事,但实际上把我们本来想消除的那些歧义也一起编码进去了。在评测里,它的效果甚至不如一个更小、人工整理过的语义层。所以我们的建议是,可以用 Claude 来生成 文档,但 定义 一定要由人负责。
- 血缘和转换图: 当语义层覆盖不了某个问题时,血缘信息和表排名(按被引用次数计算)能帮助 agent 推理,哪些上游模型在支撑这个概念,哪些已经废弃,哪些共享同样的粒度。这样一来,原本的我不知道这个指标是什么,就会转变成我知道该从哪个受治理模型去聚合。它也是我们在下面 在线验证 中展示新鲜度和来源信号的基础骨架。
- 查询语料库: 来自仪表板、notebook 和过往分析的历史 SQL。直觉上,这似乎应该很有价值,因为它记录了每一个已经被正确回答过的问题。但在实际中,我们发现,直接让 agent 检索成千上万条旧查询,准确率提升不到 1 个百分点。我们会在后文讲到这个消融实验。非结构化检索没法把一个新问题映射到正确的先例上。真正有效的做法,是把这类语料提炼成结构化的、按领域组织的参考文档,以及 skills 中描述的可复用分析模式。把查询历史当作整理素材,而不是让 agent 直接读取的事实来源。
- 业务上下文: 这是大多数团队会跳过的一层,也是我们低估最久的一层。一个不理解你业务的 agent,会回答用户提出的问题,但不一定回答了用户真正想问的事。它不会知道,Q2 发布 指的是某个具体产品,不会知道两个团队对同一个词有不同定义,也不会知道这个问题之所以被提出来,是因为周四要开董事会。我们会把公司的知识图谱接进来,内容包括已索引的文档、路线图、决策日志和组织结构,这样 agent 才能理解那些环境性指代,并提出更好的澄清问题。
这四层常见的失败模式,其实和数据基础层里是同一个问题,文档差,或者文档过时。Claude 在补这个缺口上特别有用,比如起草列描述、根据查询模式提议指标文档、在 CI 中标出缺少文档的模型。但真正的整理和归属管理,还是由人来负责。
接下来的两节,我们会讲怎样把这件事的维护成本降到足够低,低到它真的能被长期做下去。
Skills
如果说事实来源层是 agent 的 声明式 知识,也就是某个指标是什么意思,那么 skill 就是它的 过程式 知识,也就是该按什么顺序查哪些来源,怎样处理模糊数据,以及一份完整分析长什么样。
在 Claude Code 中,skill 是一个按需读取的 markdown 文件夹。在 Anthropic,我们开发的 skills 带来了极大的增益。没有 skill 时,Claude 在分析问题上的准确率在我们的评测里甚至到不了 21%。加入 skill 之后,这个数字整体上能稳定超过 95%,在某些领域甚至经常接近 99%。附录里有我们用来构建大多数 skill 的骨架模板。
一些最佳实践如下:
成对创建 skill: 一个 knowledge skill 充当薄薄的一层顶层路由,让额外的领域细节可以按需加载。它会告诉 agent,先试语义层,如果没覆盖,再去看这个领域下大约 30 份参考文件,里面描述了相关表、列、连接方式和各种坑。这个路由,本质上就是我们对检索失败问题的回答。我们不会让 agent 直接去一个拥有百万字段的数据仓库里乱搜,而是在真正写查询之前,先把搜索空间缩小到几十份精心整理的文件。另一个 unbook skill,则编码了一位资深分析师会遵循的流程,先澄清问题,再通过 knowledge skill 找来源,运行查询,然后把结果交给对抗性审查 sub-agent 循环检查。它还打包了十几种可复用分析模式,比如留存曲线、比率拆解、漏斗分析,这样常见请求就不用每次都重新发明。
写真正适合参考的文档:文档要适合被 LLM 检索。我们的参考文档会描述表本身,包括粒度、范围和排除项,也会描述那些坑的具体机制,比如排除已知免费邮箱域名,但保留像 anthropic.com 这样的自定义域名。还会写清楚显式路由触发条件,比如如果问题是在问实验提升……那就不要拿它去算原始事件数。但不会写那种很快就过时的死板配方。下面是我们用来写参考文档的一个骨架。
# [Domain] Tables
## Quick Reference
### Business Context — [what this domain means in plain words]
### Entity Grain — [what one row represents]
### Standard Hygiene Filter — [the filter every query in this domain applies]
## Dimensions
- [How the key dimensions are encoded, and how the same concept is named
differently across tables]
## Key Tables
### [table_name]
- **Grain**: [...] · **Scope/exclusions**: [...]
- **Usage**: [when to use it, when NOT to, join keys, required filters]
[... one short section per governed table ...]
## Gotchas
- [The wrong-answer modes a senior analyst would warn you about]
## Best Practices / Common Query Patterns
- [Default choices, standard cuts, worked patterns where the exact query
form is the hard part]
## Cross-References
- [Neighboring domain docs that own adjacent questions]
把 skill 维护当成一等公民:skill 文档描述的是一个每天都在变化的数据模型,所以如果不主动维护,几周之内它就会变错。我们就亲眼看到,离线准确率从刚上线时约 95%,一个月内滑到约 65%,直到我们把这件事当成工程问题来处理。具体做法是,把 skill 的 markdown 文件和转换模型放在同一个 repo 里。这样,改模型的 PR,也就是更新对应文档的 PR。代码审查 hook 会标出任何修改了报表模型却没动 skill 文件的变更。现在,大约 90% 的数据模型 PR,都会在同一个 diff 里带上 skill 的更新。随着模型变好、旧的失效模式不再出现,我们也会定期删掉那些多余的 skill 脚手架。
在所有界面上提供一致顺滑的体验:同一个 skill,必须在 Slack、IDE、仪表板工具和独立 agent 会话里,对同样的问题给出同样的答案。我们是这样做到的,用一个规范化源头,也就是数据 repo,然后让 skill 变更自动同步。代码合并后,skill 会同步到插件市场,给 IDE 用户使用;同步到云存储 blob,给读取单文件的托管应用使用;同时也会通过 MCP 直接作为资源提供。我们从一开始就按可移植性来设计,避免写死 repo 路径,避免使用和某个具体界面绑定的命名空间。
验证
最后,验证就是帮你发现,这三种失效模式里到底还有哪一种在漏水。
离线评测
我们经常看到一种情况,数据团队搭建了很复杂的分析环境,却没有任何流程去理解自己分析 agent 的准确性。
补上这个缺口的一种办法,是做离线 eval,也就是简单的问题 / 答案对。你可以把离线 eval 理解成机器学习模型里的离线测试。它不能告诉你线上 agent 的真实表现,但能很好地让你知道,系统里是不是还存在一些严重缺口。
在 Anthropic,我们部署了两类离线 eval。基于仪表板的 eval 由 Claude 自动生成,再由人工验证,覆盖最常见的业务相关方问题。长尾 eval 则是我们把业务上下文,比如路线图、表文档,喂给 Claude,让它在这个领域剩余的部分生成合理的问题。我们还会持续收集业务相关方在对话里纠正 agent 的每一次记录,因为这些纠正都可以变成候选 eval。
其他最佳实践还包括:
- 把基准答案固定住,别让它漂移:如果一个 eval 是针对实时数据写的,那么底层数字一变,它立刻就过时了。每个 eval 都要固定在某个快照日期上,或者写在稳定事实表之上,又或者让评分器去判断 agent 的 query,而不是它给出的数字。还要把这套东西接进 CI,这样一旦 PR 改动了某个依赖,受影响的 eval 就会重新跑。
- 像存遥测数据那样存结果,不要像存测试日志那样存:每次运行的结果都落进数据仓库表里,包含 skill 版本、git SHA、模型 ID、每条断言的通过 / 失败、token 数和总耗时。这样,某个改动到底有没有帮助,就变成一个查询问题。你还能拿到时间序列,用来发现那些单次 CI 跑不出来的缓慢退化。
- 按领域控制上线门槛:某个领域负责人,只有在自己那部分 eval 通过率达到某个阈值后,才能向业务相关方宣布 agent 可用。我们一开始设的是约 90%。这会强迫参考文档的修复发生在用户看到错误之前。
- 创建合适数量的 eval:你需要多少 eval,取决于业务领域有多复杂,也取决于底层数据模型有多复杂。可以通过跟踪离线准确率对线上准确率的预测效果来校准。我们的经验是,每个主题,比如增长,几十个 eval 之后就开始出现边际收益递减。而且,随着新一代模型出现,这个上限还会继续下降。
- 离线 eval 的准确率应该接近 100%,每一个正确答案也都应该命中你的语义层,如果你有语义层的话。再强调一次,这样的准确率并不代表系统不会输出错误答案,只能说明在 eval 覆盖足够好的前提下,没有明显缺口。
消融方法
关于 skill 的每一个结构性决策,比如该暴露哪些来源、某个 sub-agent 是否值得它带来的延迟、两项 skill 是否要合并,我们都是在固定离线 eval 集的前提下做判断的。
我们每次只改变一个组件,然后比较通过率。一次运行只需要一小时,却能省掉大量争论。这个方法本身,比任何单一结果都更重要:
- 要为负结果而设计。 我们最有用的一次消融,恰恰是个负结果。我们给 agent 直接开放了整个仪表板、转换逻辑和分析师 notebook SQL 的 grep 权限,总共几千个文件。之后我们还在对话记录里确认,它确实在每次回答前都读过这些内容。结果准确率无论正负,变化都不到 1 个百分点。接着我们又检查了最 obvious 的混淆因素。对于它答错的问题,答案真的在那个语料库里吗。大约 80% 的情况,是的。那只要答案存在,是不是就更容易答对。不是,翻转率并没有变化。信息就在那里,agent 看到了,但还是没用上。这个实验一下就告诉我们,瓶颈不在于能不能接触到过去的工作,而在于有没有 结构,也就是能不能把问题映射到正确实体上。这个洞察,直接改写了我们之后几个月的路线图。
- 按 PR 粒度做消融。 每一次有意义的 skill 修改,都会在相关 eval 切片上做前后对比,并把变化量写进 PR 描述里。这样,所谓文档改进了,就必须经得起验证。它还能抓住一种很常见的情况,有些出发点是好的新增内容,反而把效果弄差了。
- 保留一份简短的没用清单。 我们自己的例子有两个。第一,对文档继续叠加更多轮润色,过了某个点以后就没用了。我们连续三轮都是净负收益,文档变长了,却没变好。第二,把对抗性 reviewer 换成更便宜的模型,想降低延迟,结果大部分准确率收益都没了,速度也没有真的提升多少。把这些负结果记下来几乎没成本,却能防止后来的人把同样的实验再做一遍。
在线验证
最后一步,是确保真实线上系统的表现尽可能准确。我们会采取的措施包括:
- 对抗性审查:我们发现,使用一个 Claude skill 去积极质疑潜在最终答案背后的所有假设,能让评测集里的准确率提升 6%,但代价是 token 增加 32%,延迟提高 72%。
- 来源页脚: 每个回答都会带一个页脚,里面写明它来自哪一层来源,语义层、整理过的参考资料,还是原始表,还会说明底层数据有多新、模型归谁负责。这不会让答案本身更正确,但能帮助使用者判断这条回答到底该信到什么程度。一个写着原始表,新鲜度未知的页脚,就是一个应该先核实、再往上转发的信号。这也是我们应对静默失败少数有效的办法之一。
- 数据质量检查:即使 agent 用的是对的字段,也用对了方式,数据本身仍然可能是错的。加上一些基本的数据质量检查,确保引用字段是最新的、完整的、没有异常,通常都是好的卫生习惯。
- 被动监控: 我们持续跟踪两个生产信号。一个是 agent 查询中有多少比例最终通过语义层解决。另一个是回答里用了纠正语言的比例,比如那张表不对,或者你漏掉了欺诈过滤器。这两个指标都会进入一个仪表板,每周和离线通过率一起被审查。
- 主动收集纠正: 这一步把闭环真正补上。一个定时运行的 agent 每隔几小时就会扫描业务相关频道,查找类似纠正语言,给对应参考文档起草一条单行修复建议,并发起一个标记到领域负责人的 PR。这个修复路径被我们刻意设计得很无聊,改一份 markdown,合并,自动同步到所有地方。这样领域负责人就不会在这件事上花太多时间。同样,这些纠正也会回流进离线 eval 集。
这些方法里,没有一种能彻底抓住的失效模式,是那种静默的错误。答案是错的,但看起来很像对的,于是没人提出异议,它就被直接用了。我们当前的缓解手段包括来源页脚、所有发给管理层的内容都必须有人明确签字,以及为每个领域的核心 KPI 设立一个常驻 eval,每天拿它去和标准仪表板做 sanity-check。不过,坦白说,我们还没有一个足够稳健的解决方案。
如何开始
如果你是从零起步,那么少量规范数据集、几十个离线 eval,再加一个薄薄的 knowledge skill,就已经能拿到大部分收益。本文其他内容,都是在这些基础已经搭好之后,我们继续加上去的东西。
我们也分享了不少最佳实践,但不是每一条都适合每个数据团队。更实际的做法,是先和组织内部对齐几条会直接影响方案的原则。你可以从这些问题开始思考:
- 今天的正确答案,和未来的正确答案,哪个更重要?AI 模型进步非常快。我们常看到一些公司为了弥补当前模型的短板,建设了大量基础设施,但等模型能力提升后,这些投入就显得没那么必要了。清楚知道模型到底短在哪里,然后等待模型进步去填补这些缺口,整体开销会小得多,但这未必符合你们公司的风险承受能力。
- 你预期业务复杂度会怎样随时间变化?如果你的数据量并不大,输出结果的使用者也不多,或者数据模型大概率会一直保持简单,那么我们上面讲的一些流程可能就有点过度了。
- 输出内容面向的人群有多强的技术背景?换句话说,如果你构建这套分析系统是给数据科学家用的,而他们能看出答案什么时候不对,那么你对错误的容忍度可能就会高一些。反过来,如果受众对底层数据模型完全不熟,这件事就不一样了。
- 为了提高准确率,你愿意付出多少成本?我们的经验是,像对抗性验证这样的流程,确实能显著提高准确率,但往往也会带来更高成本和更长延迟。
- 你对访问控制和内部数据隐私的接受度如何?agent 拿到的上下文越多,通常表现越好。但广泛的数据访问权限,往往和多数公司的治理姿态相冲突。这会决定你做的是一个大一统 agent,还是多个有边界的 agent。
不管你走哪条路,我们最大的收益都来自对三种失效模式逐一处理,把歧义压缩成一个受治理的标准答案,让这个答案容易被发现,并且在答案或定义过时时及时发出信号。
本文由数据科学与数据工程团队成员 Chen Chang、Clement Peng、Justin Leder、Johanne Jiao 和 Josh Cherry 撰写。作者也感谢 Michael Segner 的贡献。
附录
Skill 文件骨架
下面展示的是我们主数据仓库 skill 的骨架,也就是实际文件的结构,只是把内部细节替换成了 [方括号占位符]。它并不是让你逐字照抄,而是为了展示我们认为值得写下来的那些部分。
---
name: [warehouse-skill]
version: [x.y.z]
description: "IF the user asks to query [the company]'s data warehouse for any
[list of business domains] question — THEN invoke this skill. DO NOT invoke
for [adjacent engineering tasks] or questions with no data-warehouse component."
---
# [Warehouse] Skill Instructions
## Description
The single source of truth for safe and effective [warehouse] querying.
Referenced by other skills [listed] for query execution guidance.
Act as a Data Analyst, providing strategic insights and data-driven
recommendations but seek guidance along the way.
**Out-of-scope decisions**: [product areas, etc.] → surface data only,
state "decision is [owning team]'s call", do NOT take a position or author
code fixes.
## Executing queries
Priority:
1. **[Managed connection]** (if available): [query tool] / [schema tool]
2. **[CLI fallback]** (if installed): [default project, fallback project]
3. **Neither** — ask the user to authenticate, then stop
---
# Semantic Layer (REQUIRED first step)
The governed semantic layer is the **mandatory default path** for every data
question — same numbers as [the BI tool], joins/grain/filters baked in. Raw SQL
via the reference docs below is the **fallback**, used only after the
semantic-layer path is shown not to cover the ask.
## Required workflow
1. **Load** — [how to load the semantic layer in each runtime, with fallbacks]
2. **Discover** — search measures/dimensions by keyword; **always check
segments** (the named canonical population filters — hand-rolled WHERE
clauses for these are the dominant wrong-answer mode)
3. **Compile + run** — build the spec → compile to SQL → execute
4. **Fallback** — only if discovery finds no relevant metric or compile fails
→ raw SQL via `references/*.md` (PART 3 below)
> **Don't bail early.** Do NOT fall back to raw SQL on these grounds:
> - "[custom date filtering / cohorts]" → [covered by time-dimension specs]
> - "[needs a join]" → [the metric layer already encapsulates its joins]
> - [3–4 more pre-rebutted excuses agents use to skip the semantic layer]
### Date windows & timezone — decide before you query
- **As-of date vs trailing-N days**: [convention for each]
- **"Last week/month"** → the last *complete* calendar week/month, not trailing-7/30
- **Timezone default**: [TZ]; [exception for certain reporting rollups]
- **Freshness lag**: [some] tables settle late — anchor on MAX(date), not "yesterday"
---
# PART 1: MUST KNOW (Read First for Every Request)
## 🚀 Quick Start Workflow
1. **Check for red flags first**: [restricted/PII requests, gated domains,
high-stakes asks that need extra validation]
2. **Out of scope — escalate, don't guess**: [access requests, pipeline
troubleshooting, stale dashboards, root-cause assertions, product/pricing
recommendations] → redirect to [the owning team], don't answer
3. **Clarify the request**: time period, segment, the business decision it informs
4. **Check for existing dashboards**: [per-domain dashboard catalogs]
5. **Identify the data source**: [navigation map below; prefer governed/aggregated tables]
6. **Execute the analysis**: [required filters + adversarial review]
7. **Deliver insights**: show methodology, differentiate observations from interpretations
## 🏢 Business Context
### Entity Disambiguation (MUST CLARIFY)
- **"[Term A]" can mean**: [entity 1] or [entity 2] — always clarify which
- **"[Term B]" can mean**: [entity 1] → [entity 2] → [entity 3] (one-to-many chain)
- **"Users"**: [which identifier gives accurate counts, and which ones inflate them]
### Business Terminology
- [Current product names vs deprecated aliases that still appear as frozen
values in the data layer — write with the new names, filter with the old]
- [Key internal acronyms]
- **[Headline metric] calculations**: [monthly / default window / leading indicator]
- **Unfamiliar terms — search [internal docs], don't guess**
### Data Integrity Requirements ⚠️
- **NEVER**: make up data/columns; make speculative assertions beyond what data shows
- **ALWAYS**: use safe division; differentiate observations ("data shows X")
from interpretations ("this suggests Y"); flag limitations
---
# PART 2: HOW TO DO (Follow During Execution)
## 🔧 Technical Execution Guide
- [Managed-connection tools and CLI invocation details]
- **PII protection**: for restricted data, return the SQL for the user to run
themselves — do not return results
## 📊 Analysis Best Practices Guide
1. Clarify the ask before querying
2. Show your work (filters, inclusions/exclusions, freshness)
3. Clarify denominators
4. Consider sample bias
5. Connect to business impact
6. **Adversarial SQL review (MANDATORY)** — spawn the [sql-reviewer] sub-agent
for every query before the final answer; blocking findings must be fixed
and re-reviewed; do not self-certify
7. **Report with provenance** — every answer ends with a footer:
> **Source:** [semantic layer | governed table | raw exploration] ·
> **Confidence:** [tier] · **Reviewed:** [reviewer ✓, round N] ·
> **Freshness:** [max date in the data] · **Owner:** [owning team]
---
# PART 3: DATA REFERENCES & RESOURCES
## 📚 Knowledge Base Navigation
### [Domain A] → `references/[domain_a].md`
- **Use for**: [kinds of questions]
- **Key tables**: [...]
- **Dashboards**: `references/[domain_a]_dashboards.json`
### [Domain B] → `references/[domain_b].md`
- **Use for**: [...]
[... one entry per business domain — a few dozen in total ...]
## ⚠️ Troubleshooting Guide
### When Information Is Missing
- [missing tables / access denied / outdated docs / unknown enum values → what to do]
### Field Naming Gotchas
- Use `[field_x_v2]` NOT `[field_x]`
- [Two similarly-named tables report the same metric at different grains — which to use]
- [Which of two plausible sources is canonical for the headline metric]
- [… a dozen more hard-won one-liners …]
未找到任何条目。
用 Claude 改变你的组织运作方式
获取开发者新闻简报
产品更新、操作指南、社区聚焦等更多内容。每月发送到你的收件箱。
如果你愿意订阅我们的每月开发者新闻简报,请提供你的电子邮件地址。你可以随时取消订阅。
谢谢!你已订阅。
抱歉,你的提交出了点问题,请稍后再试。