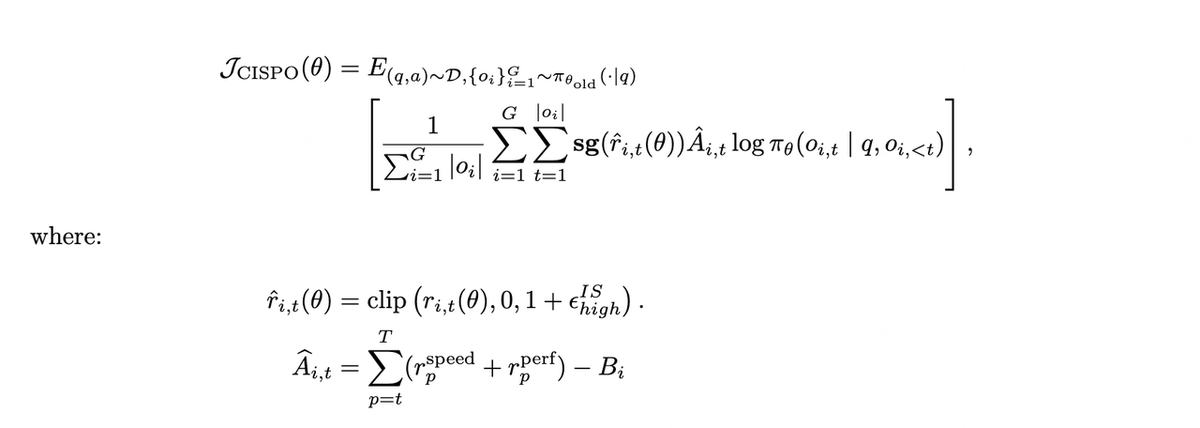Scaling RL for complex, real-world agents confronts a fundamental trilemma: balancing system throughput, training stability, and agent flexibility. These conflicting constraints have long impeded the application of large-scale RL in industrial-grade systems.
In this post, we reveal how we resolved this "impossible triangle" through a holistic approach in our internal RL framework Forge, combining flexible system architecture, algorithmic design, optimized asynchronous scheduling, and extreme training-inference efficiency. By leveraging standardized interaction protocols, Forge supports the training of arbitrary agent scaffolds, enabling the massive-scale RL that culminates in the breakthrough capabilities of the MiniMax M2.5 model.
Throughout the construction of MiniMax M2.5, our RL system navigated over a hundred thousand distinct real-world agent scaffolds and environments. Operating with context lengths of up to 200k, the system maintained a daily processing throughput on the scale of millions of samples, realizing consistent reward convergence and genuine capability improvements in the underlying model. Integrated with our CISPO algorithm and composite reward framework, M2.5 pushes the frontier for efficient and reliable real-world productivity, achieving our mission "Intelligence with Everyone".
- Problem Formulation
Before delving into our architectural design, we first formulate the optimization objective of our Agent RL system to be the maximization of the Effective Agent(A) Training Yield (J), defined as:
\begin{aligned} \max_{\theta} J(\mathcal{\theta}) = & \text{Throughput}(\mathcal{A}) \times \text{Sample Efficiency}(\mathcal{A}) \ \text{s.t.} \quad & \forall \mathcal{A} \in \Omega_{\text{agent}} \quad (\text{Arbitrary Agent}) \ & \mathbb{E}[\text{Update Variance}] < \delta \quad (\text{Stability}) \ & \mathbb{E}[|J^{(T)} - J^*|] < \epsilon \quad (\text{Convergence}) \end{aligned}
maxθJ(θ)=Throughput(A)×Sample Efficiency(A)s.t.∀A∈Ωagent(Arbitrary Agent)E[Update Variance]<δ(Stability)E[∥J(T)−J∗∥]<ϵ(Convergence)\begin{aligned} \max_{\theta} J(\mathcal{\theta}) = & \text{Throughput}(\mathcal{A}) \times \text{Sample Efficiency}(\mathcal{A}) \ \text{s.t.} \quad & \forall \mathcal{A} \in \Omega_{\text{agent}} \quad (\text{Arbitrary Agent}) \ & \mathbb{E}[\text{Update Variance}] < \delta \quad (\text{Stability}) \ & \mathbb{E}[|J^{(T)} - J^*|] < \epsilon \quad (\text{Convergence}) \end{aligned}
where System Throughput refers to the raw number of tokens processed per second, bottlenecked by 4 components of the whole RL system: rollout, training, data processing and I/O. Sample Efficiency refers to the average performance improvement for each sample determined by data distribution, data quality, algorithm efficiency, and off-policy-ness. We choose our specific constraints using proxy indicators for both stability and convergence considerations, as noted in the equation. Achieving maximal J is hindered by three structural challenges, which we explain in detail below.
1.1 Agent Extensibility and Framework Flexibility
Current RL paradigms impose a "Glass Ceiling" on agent complexity due to two structural flaws:
Restricted Agent Autonomy: Standard frameworks treat agents as white-box functions with a shared state between agent and trainer. This rigidity makes it difficult to model complex cognitive architectures (e.g., dynamic Context Management, Multi-Agent collaboration) and therefore prevent the model capability from generalizing effectively on an arbitrary black-box agent without these assumed structural constraints.
Token Consistency Barrier: Existing TITO (Token-In-Token-Out) architectures force Agents to be coupled deeply with the underlying token logic. Maintaining strict consistency between the Inference Abstraction (high-level logic) and the Training Representation (token-level data) under complex Context Management (CM) is computationally prohibitive.
1.2 System Efficiency and Compute Redundancy
Agent rollout completion times exhibit extreme variance, ranging from seconds (simple API calls) to hours (complex reasoning chains). This creates a scheduling deadlock:
Asynchronous Controller: Systems face a critical trade-off between hardware efficiency and training stability: while Strict FIFO/Sync scheduling suffers from the Straggler Effect, where a single high-latency task causes Head-of-Line (HoL) Blocking and idles the cluster, Greedy/FFFO modes maximize throughput at the cost of a severe Data Distribution Shift. This shift creates a non-stationary training environment—initially dominated by short, "easy" tasks and later by clustered "hard" tasks—leading to optimization instability and gradient oscillation.
Prefix Redundancy: In Agent scenarios, the interplay between tokenizer mechanics and inherent Context Management naturally results in a substantial volume of requests sharing identical prefixes. This redundancy causes significant computational waste during training, thereby introducing distinct engineering challenges.
1.3 Algorithmic Challenges: Credit Assignment and Optimization Stability
Sparse Rewards and High Gradient Variance: Agentic tasks typically involve extended horizons with delayed feedback, where a single outcome depends on a sequence of thousands of actions. Assigning credit to specific tokens or tool invocations within a 200k context window is mathematically precarious. This sparsity leads to a low signal-to-noise ratio in the return calculation, causing high gradient variance that destabilizes the training of large-scale models.
Latency-Agnostic Optimization: Traditional RL objectives focus solely on correctness (step-wise or outcome rewards) while ignoring the wall-clock execution cost. In real-world agentic scenarios, multiple valid trajectories exist, but they differ significantly in latency due to tool execution overhead and serial processing. Standard paradigms fail to incentivize parallelism or efficient tool usage, resulting in functionally correct but practically sluggish agents.
- System Architecture and Agent RL Paradigm
To alleviate the "Efficiency vs. Off-Policyness" trade-off and minimize redundancy, we introduce the following architectural innovations.
2.1 RL System Design
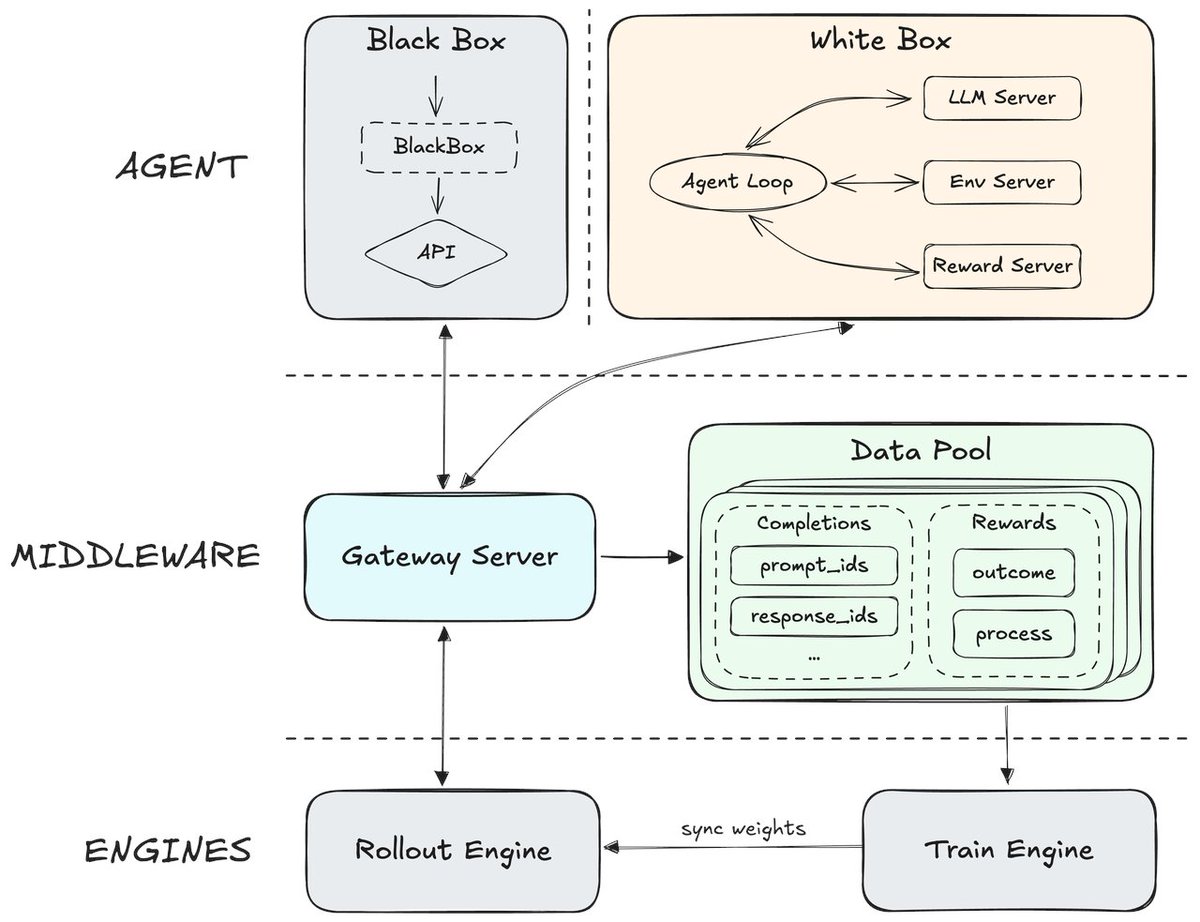
To achieve a truly scalable architecture, we move beyond specific implementations to a generalized "Middleware" design. This decouples the Agent's reasoning logic from the underlying training infrastructure.
Our RL system is made up of 3 modules:
Agent Side: This layer abstracts the General Agent—comprising both white-box and black-box architectures—and its operational environment. It orchestrates recursive environmental interactions, allowing the Agent to function as a pure trajectory producer. By decoupling environmental feedback from system overhead, the Agent can focus exclusively on core business logic (such as Context Management and Reasoning Chains), remaining agnostic to the underlying training and inference mechanics.
Middleware Abstraction Layer: Acting as the bridge, this layer physically isolates the Agent Side from the Training/Inference Side, including the Gateway server and the Data Pool.
Gateway Server: It serves as a standardized communication gateway that processes completion requests between the agent and the LLM. By utilizing common standard protocols, this server effectively isolates the complexities of the actual underlying model from the agent's high-level behavioral logic.
Data Pool: As a distributed data storage, Data Pool asynchronously collects rollout trajectories and reports from the agent. It serves as a buffer that decouples generation and training, allowing users to apply flexible data processing and batching strategy for training efficiency and algorithmic usage.
Training and Inference Side: This layer manages the heavy computational lifting, consisting of the LLM Engine and Train Engine.
Rollout Engine: Dedicated to high-throughput token generation, responding to requests forwarded by the Middleware.
Train Engine: Consumes processed token sequences from the Data Pool to update the policy. It maintains synchronization with the LLM Engine to ensure the agent explores using the latest policy distribution.
During offline evaluation, we observed significant performance discrepancies attributed to differences in the scaffolds. Leveraging the modular design of our RL framework, we can conduct training using an extensive array of scaffolds without requiring internal modifications to the Agent. This approach effectively enables the model to generalize across diverse scaffolds, a.k.a. environments. Our architecture achieves a complete decoupling of engines and agents, ensuring the seamless integration of various agents. In total, we have integrated hundreds of types of scaffolds and thousands of distinct tool invocation formats.
2.2 White-Box Agent RL for Context Management (CM)
For white-box agents, comprehensive scaffold design and augmentation allow us to directly observe and optimize the model's performance on specific agent architectures. In the development of MiniMax M2.5, we specifically addressed several critical issues that plagued previous models during long-horizon tasks requiring active context management (such as DeepSearch):
The Challenge of Context Rot: As the number of interaction turns increases, the accumulation of intermediate reasoning steps and redundant observations creates an "attention dilution" effect. This accumulated noise causes the model to lose focus on critical information, even when operating strictly within its absolute context window limits.
Inference-Training Mismatch: While context management can effectively extend the interaction horizon and boost agent performance in long-context scenarios, applying it exclusively during inference introduces a severe distribution shift from the RL training data. This discrepancy forces the model to abruptly adapt to unexpected context transitions and process unfamiliar long-context structures on the fly, ultimately degrading its overall performance.
To resolve this distribution shift and maintain reasoning fidelity, we integrate the CM mechanism directly into the RL interaction loop, effectively treating Context Management as a functional action that drives state transitions:
CM-Driven State Transitions: We model CM as an explicit agent action, with context transitions naturally embedded within the environment's dynamics. The state transition from St to St+1 implicitly encapsulates the context-switching logic, effectively folding context adaptation directly into the model's training objective.
Adaptive Reasoning Patterns: By optimizing the policy π within this framework, the model learns to internalize the distribution shift. This prompts the emergence of robust reasoning patterns that inherently prioritize "state-critical" tokens.
Context-Aware Management Strategy: Under this paradigm, the model is trained to anticipate potential context management operations and shifts during the RL generation process. By actively retaining task-critical information while pruning irrelevant contextual noise, the model significantly enhances its performance when deployed within Context-Management Agent frameworks.
2.3 Black-box Agent RL: Robustness Across Heterogeneous Scaffolds
In practical deployment, a significant portion of our user base operates proprietary or complex agent architectures that function as "Black Boxes." We have observed that model performance often varies drastically depending on the underlying agent scaffold, as standard training paradigms fail to generalize across different cognitive architectures. To address this, we validated our framework through a dedicated Black-box Agent Experiment, ensuring consistent optimization regardless of the agent's internal opacity.
Non-Intrusive Integration and Compatibility: Forge remains completely agnostic to the agent's internal implementation details. Agents simply route their requests to the RL service Gateway, and the framework automatically handles data collection and training under the hood. Consequently, during actual RL training, Forge seamlessly supports arbitrary context manipulations (such as memory compression and history rewriting) alongside any complex internal Agent Loop (e.g., Deep Think, Multi-Agent architectures).
Multi-Scaffold Generalization: By decoupling the training loop from the agent's internal state, MiniMax M2.5 achieves broad compatibility with a vast array of black-box agents. This adaptability spans everything from code-centric agents heavily reliant on Sandbox and Model Context Protocol (MCP) environments—for instance, training our OpenCode Agent entirely as a black box—to agents employing aggressive context reduction strategies, such as Truncate BC. Empirical results demonstrate that this approach delivers consistent, stable improvements even across completely opaque black-box systems.
- Engineering Optimization
3.1 Hybrid Scheduling Strategy: Windowed FIFO
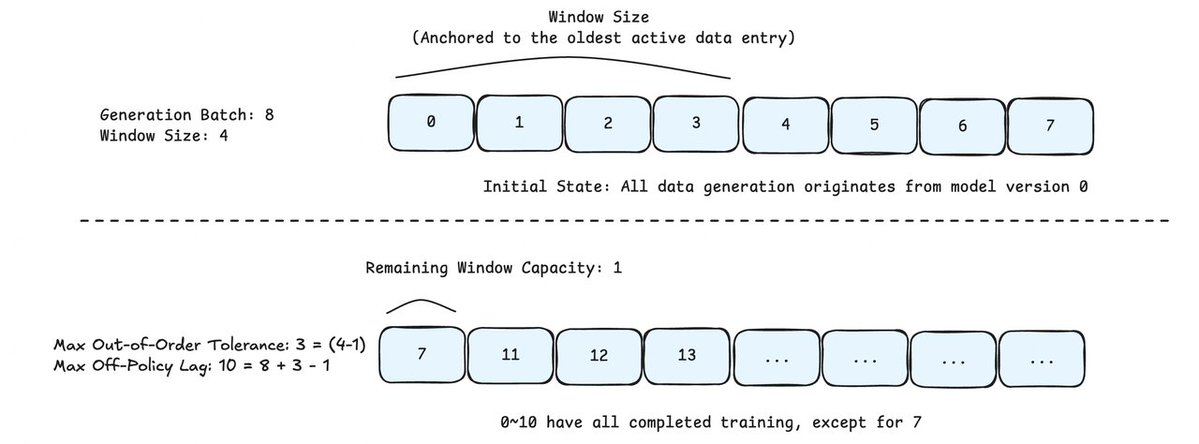
To resolve the conflict between System Throughput and Distributional Consistency, we introduce Windowed FIFO. This strategy imposes a sliding constraint on the Training Scheduler, acting as a "middle ground" between strict synchronous ordering and greedy asynchronous execution.
The core logic governs how the Training Scheduler fetches samples from the global generation queue. Even if a large batch of requests (e.g., Generation Batch Size N) is submitted, the scheduler is restricted to a visibility window of size W (e.g., W=0.3N).
Restricted Visibility Scope: Let the generation queue be denoted as Q=[T0,T1,...,TN−1], with the current head at index i. The Training Scheduler is strictly limited to fetching completed trajectories from the range [Ti,Ti+W−1].
Local "Greedy" Disorder (Within Window): Inside the active window [Ti,Ti+W−1], the scheduler can retrieve any completed trajectory immediately. This mitigates the Head-of-Line (HoL) blocking effect, as fast tasks within the window do not need to wait for the absolute first task to finish.
Global "Strict" Blocking (Window Boundary): Crucially, even if a task at index j>i+W (outside the window) is completed—common for simple, fast tasks in a large generation batch—the scheduler is forbidden from fetching it.
Constraint Implementation: The window slides forward (i→i+1) only as tasks at the head are consumed. This mechanism effectively forces the scheduler to wait for "stragglers" (complex, long-horizon tasks) within the current window, preventing the training distribution from drifting towards "fast and easy" samples found later in the queue.
3.2 Accelerating Agent Trajectory Training with Prefix Tree Merging
In the training of agents, datasets typically consist of extensive multi-turn dialogue samples. Structurally, these samples exhibit a high degree of overlap.
The Challenge: Redundancy in Traditional Methods
Prefix Overlap: In naive multi-turn dialogues, messages are sequentially appended. Given a consistent tokenizer, multiple completions sharing the same history could theoretically be merged.
Complex Context Management: Agents often employ sophisticated context management strategies, such as discarding irrelevant intermediate results or performing self-summarization. Consequently, distinct completions frequently share extensive common prefixes.
Limitations of the Naive Approach: Traditional training methods treat each sample as an independent entity, repeatedly recalculating these common prefixes. In long-context scenarios, this computational redundancy results in a massive waste of TFLOPS and severely constrains training throughput.
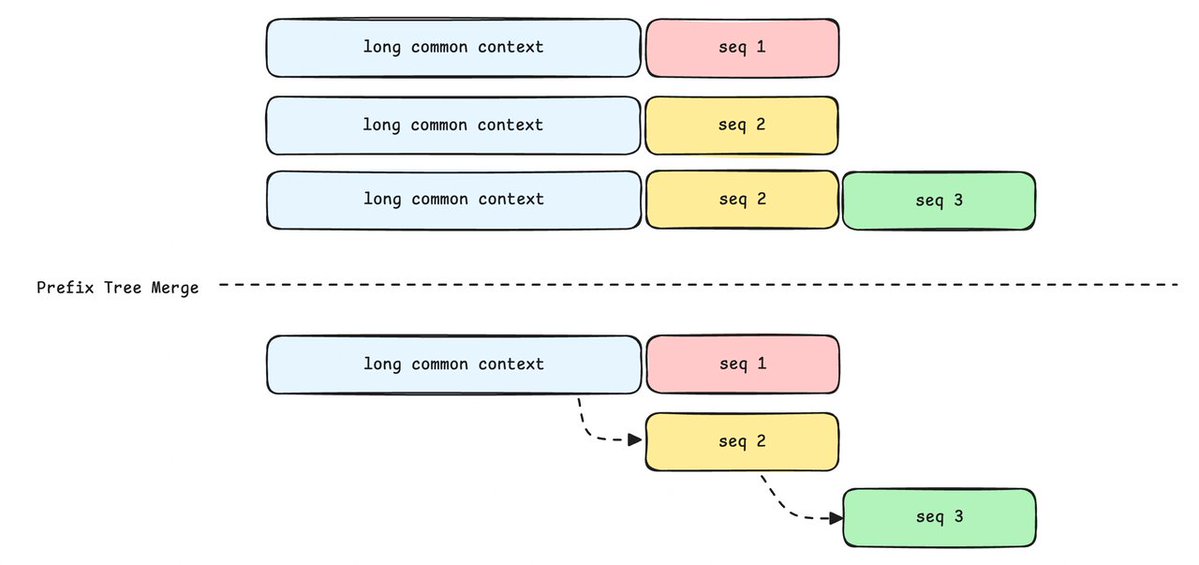
Prefix Tree Merging
To eliminate this redundancy, we propose a Prefix Tree Merging scheme, transforming the training process from "linear processing" to a "tree-structured" approach.
Prefix Tree Merge: Addressing the complex context management in Agent scenarios (as illustrated by the "long common context"), multiple completions can be merged into a single prefix tree at the sample level—even if subsequent responses differ slightly or belong to different sampling branches—provided they share an underlying prefix.
By utilizing attention primitives (such as Magi Attention), we ensure that the logical execution remains consistent with a standard forward pass. Following the forward pass, the prefix tree is deconstructed based on metadata to compute the loss normally, ensuring zero impact on downstream logic.
By eliminating redundant prefix prefilling, this solution achieves a 40x training speedup and significantly reduces memory overhead to support longer sequences or larger batch sizes, all while guaranteeing strict mathematical equivalence to standard methods with zero impact on loss computation or metrics.
3.3 Extreme Inference Acceleration
We optimize the generation pipeline through three architectural innovations:
MTP-based Speculative Decoding: Instead of static draft models, we use Multi-Token Prediction (MTP) heads continuously fine-tuned via Top-K KL loss. This ensures alignment with the evolving RL policy, sustaining high acceptance rates and significant speedup by mitigating distribution shifts.
Heterogeneous PD Disaggregation: We decouple Prefill and Decode to eliminate PD interference in mixed MoE scheduling and allow for independent parallelism strategies for each instance, simultaneously maximizing global throughput and optimizing tail latency for long-horizon tasks.
Global L3 KV Cache Pool: To prevent redundant prefilling in multi-turn agent RL and maximize prefix cache hit rate with group-level rollout, we introduce a DFS-backed Global L3 Cache. A cost-aware scheduler dynamically routes requests by weighing queuing delay against cache migration costs, maximizing cache locality without overloading instances.
- Scalable Agent RL Algorithm
4.1 RL Algorithm
We leverage CISPO as the core algorithm, specifically adapted for the characteristics of long-horizon Agents.
Unified Mixed-Domain Training: Unlike multi-stage reinforcement learning, which often leads to negative transfer or interference between domains, we adopt a unified training strategy. We mix tasks across Reasoning, General QA, and Agent domains simultaneously. This joint training approach mitigates the performance degradation typically seen in sequential training and significantly enhances the model's generalizability across diverse tasks.
4.2 Dense and Efficiency-Aware Reward
We propose a composite reward framework designed to tackle the credit assignment challenges of ultra-long contexts (up to 200k) while ensuring training stability:
Process Reward: To provide dense feedback, we target intermediate behaviors (e.g., penalizing language mixing or specific tool invocation errors) rather than relying solely on the final outcome.
Task Completion Time Reward: In agentic scenarios, multiple trajectories exist for task completion. The total duration depends not only on token generation but also on the latency associated with specific tool execution and sub-agent invocations. Since completion time is critical to the actual user experience, we incorporate relative completion time as a reward signal. This incentivizes the agent to leverage parallelism, thereby accelerating task execution.
Reward-to-go for Variance Reduction: Standard sparse rewards often lead to high gradient variance in long-horizon tasks. We employ the Reward-to-go formulation to normalize returns. This effectively reduces gradient variance and improves the precision of credit assignment, stabilizing the optimization process.
- Conclusions
We have successfully addressed the "impossible triangle" of scaling RL for agents. Through Forge, we achieved a breakthrough in RL system throughput while ensuring robust generalization across arbitrary Agent scaffolds. By integrating this flexible architecture with our stable CISPO algorithm, we enabled the massive-scale training behind MiniMax M2.5. This holistic approach overcomes previous constraints, delivering efficient, real-world agent capabilities and advancing our mission of "Intelligence with Everyone."





Link: http://x.com/i/article/2022169816556331008