
你有没有想过,DeepSeek 可能会怎么赚钱,而且会赚很多钱?
他们没有像 GLM、MoonShot 和 MiniMax 那样推出有竞争力的 coding 计划。他们没有多模态、音频、视频模型。到目前为止,他们甚至还没有 harness(他们最近才开始招聘搭建 harness 的人)?DeepSeek 还长期坚持开源,而且非常乐于分享自己的独门诀窍。这是疯狂吗?这是在白白烧钱吗?那些准备向他们投资 100 亿美元的投资人,是在把钱往下水道里扔吗? ** 不是,恰恰相反,依我看完全不是!!!
**下面我想讲讲他们到目前为止做过的事,以及他们似乎正在遵循的一套战略。梁文锋(DeepSeek CEO)看中的奖赏显然大得多,他们有可能做到 1 万亿美元估值,同时帮助创造一个 10 万亿美元的产业!

重看 DeepSeek 的英雄之旅
DeepSeek 一直都在逆风而行。他们不走那种把模型一点点做得更好,然后赶紧卖现成应用的路子,比如 coding 计划。2025 年 1 月 27 日,我写过一条传播很广的推文,谈我眼中的 DeepSeek 英雄之旅。现在这个故事只会越来越有意思。
-
当大家都在尝试构建 dense model 时,DeepSeek 转向了更难训练的 Mixture of Expert model,也就是 MoE。
-
他们从 first principal 的思路出发,发明了新的算法 GRPO,用来替代在 Reinforcement Learning(RL)里占主导地位、实现成本更高的 PPO 算法。
-
他们把 Reinforcement Learning from Verified Rewards(RLVR)找出来,作为提升模型推理能力的一项关键策略。
-
他们提出了一个简单的 Speculative Decoding 策略,也就是通过 Multi Token Prediction,同时还让训练信号变得更密集。
-
他们把 ZERO bubble pipeline 做到了极致,用来提升有限 GPU 资源的利用率。
-
他们发布了 Expert Load balancer,让所有人都能更容易部署 Mixture of Expert model。尤其是配合 Wide Expert Parallel 策略,模型服务成本可以低很多,因为可以使用更大的 batch。
-
他们发明了 MLA、DSA、CSA、HCA,用来降低 KV Cache 需求,并让计算需求在 context 持续变长时仍然接近恒定。
-
他们发明了 Engram,用 memory 换 compute。
-
他们发明了 mHC,在模型规模继续变大时依然能保持稳定训练。后面的例子还可以继续列下去。
在英雄之旅这种故事结构里,也是最普遍的一种结构,英雄从不会一开始就决定自己的旅程终点是什么。他是在路上不断学习,最后为自己找到一个伟大的使命,并在几乎不可能的情况下把它完成。他会遇到很多唱反调的人,但他不会理会。他会遇到很多动机不纯的人。他也会有很大的缺陷或短板,但他最终会克服这些,完成自己的使命。他会面对看上去根本跨不过去的挑战,但最后会想明白该怎么结盟,怎么珍惜并合理使用宝贵资源。这就是为什么观众会站在英雄这边。这也是 DeepSeek 为什么会拥有粉丝、全球性的尊重,当然也包括反对者。
接下来我会更详细地说明,DeepSeek 在这条路上已经走了够久,也已经看到了最终命运。那不是去卖 coding 计划,而是去促成一个 10 万亿美元规模的中国 AI 硬件生态,同时让自己拿到 1 万亿美元估值。在这个过程中,他们也会推动西方硬件生态里出现许多新的参与者。
欢迎评论和批评 @naval @teortaxesTex @jukan05 @bubbleboi @poezhao0605 @hsu_steve @tphuang



https://arxiv.org/pdf/2405.04434
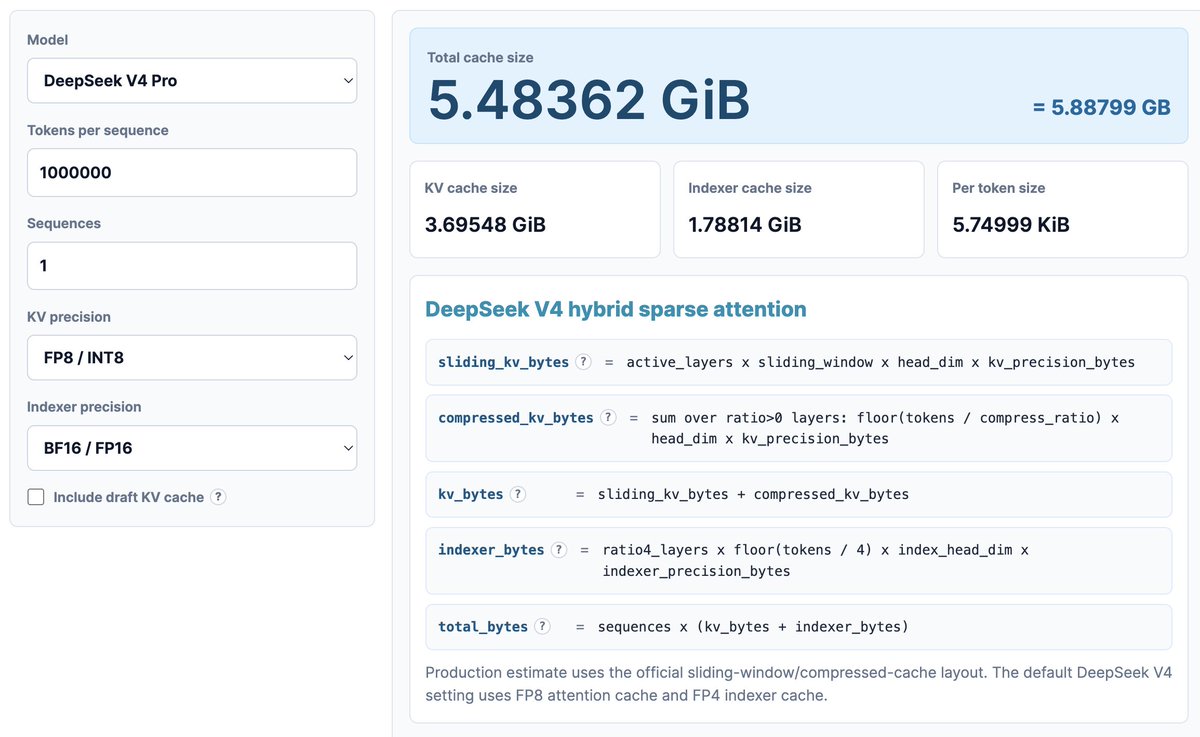
先从一些有意思的 KV Cache 计算开始:
看看这条非常应景的推文,来自 @SemiAnalysis_:
https://arxiv.org/pdf/2512.24880
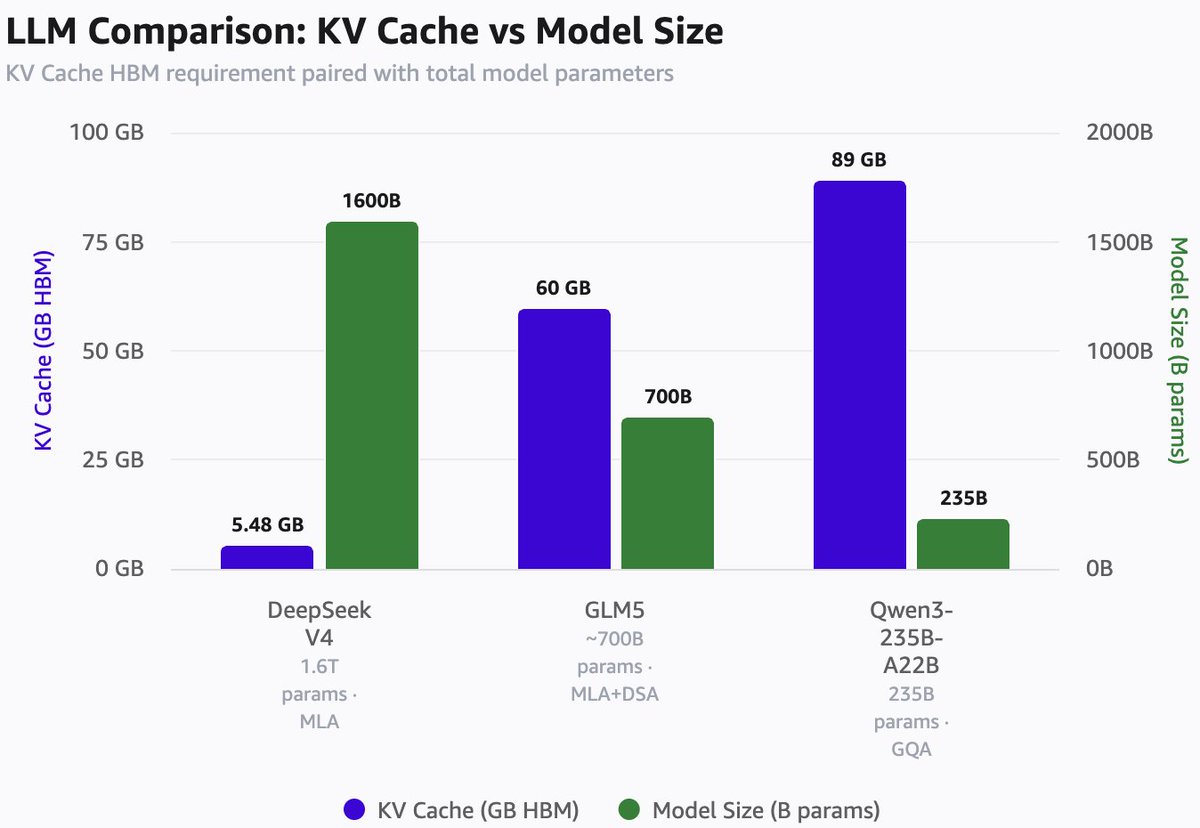
先来做点有意思的 KV cache 数学题。就算你不喜欢数学也别担心。我们会用最近发布的 KV Cache calculator,看一看 DeepSeek V4 Pro 带来的 KV Cache 节省,再和最新的 GLM 与 Qwen 模型做对比。
我按 1M context 来算。假设 KV precision 是 8 bit,indexer precision 是 16 bit。你也可以自己玩这个 calculator。
https://kvcache.ai/tools/kv-cache-calculator/

在 1M context 下
-
DeepSeek V4 只需要 5.48GB HBM
-
GML5 需要 60GB HBM
-
Qwen3-235B-A22B 夸张地需要 89B
别忘了
-
DeepSeek 是一个 1.6T parameter model,
-
GLM5 大约是 700B parameter,它已经用了 DeepSeek 的 MLA 和 DSA,不过还没用上最新的 compressed attention
-
Qwen3-235B-A22B 大约是 235B,并且使用的是 GQA attention
DeepSeek 在缓解 memory 压力这件事上做出了基础性贡献。如果这些创新被广泛采用,就能让 long horizon agent 变得极其经济,并解锁下一批用例。
疯狂背后的方法:
这种很小的 KV cache 体积,而且不牺牲质量,正是他们能把长时间持有 cache 的价格压到荒谬低水平的原因。价格还不到 Sonnet 4.6 cache hit 的 3%,而且他们能持有好几个小时。
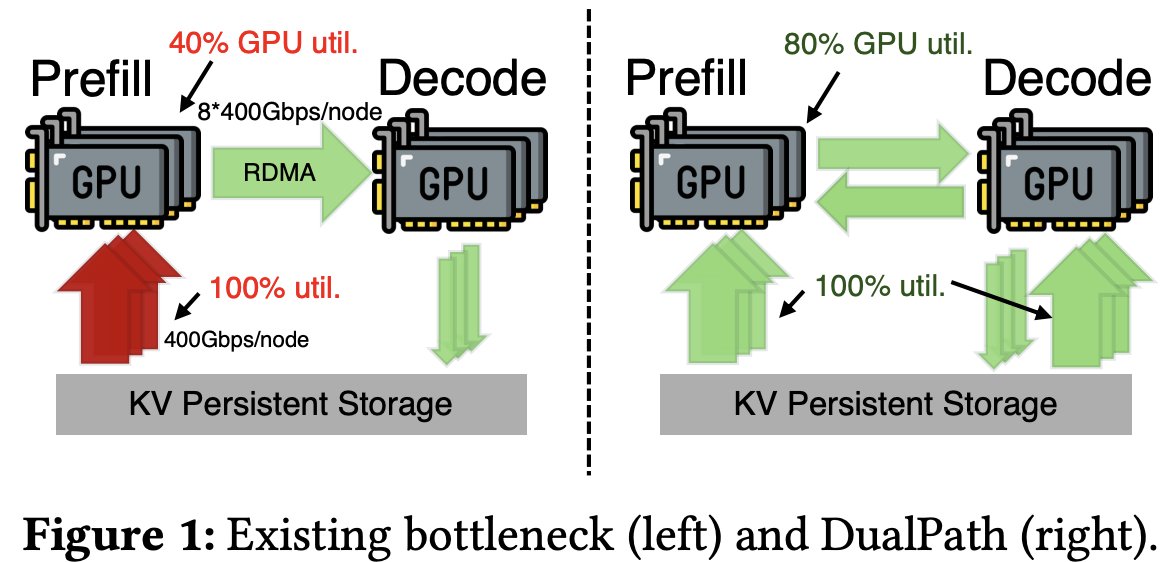
对 long horizon task 来说,少量 cache 意味着可以非常经济地卸载到 SSD,再重新加载。这减少了对 HBM 的需求,而 HBM 恰恰是供应最紧张、也是从中国 AI 硬件产业角度最难制造出来的 memory。DeepSeek 还开发了从 SSD 更快加载 KV cache 的技术,这一点在 Dual Path 论文里有描述。
https://arxiv.org/pdf/1701.06538
谁是 KV Cache 压缩的直接受益者?
谁能大规模供应 SSD?别忘了,YMCT 正在崛起为 3D NAND 巨头。NAND 让 DeepSeek 可以避免对 KV 进行重复计算。反过来,DeepSeek 又为 NAND 和 SSD 创造了一个巨大的市场,不只是 YMTC,也包括其他所有厂商。

但这不只是 NAND 和 SSD 的事:
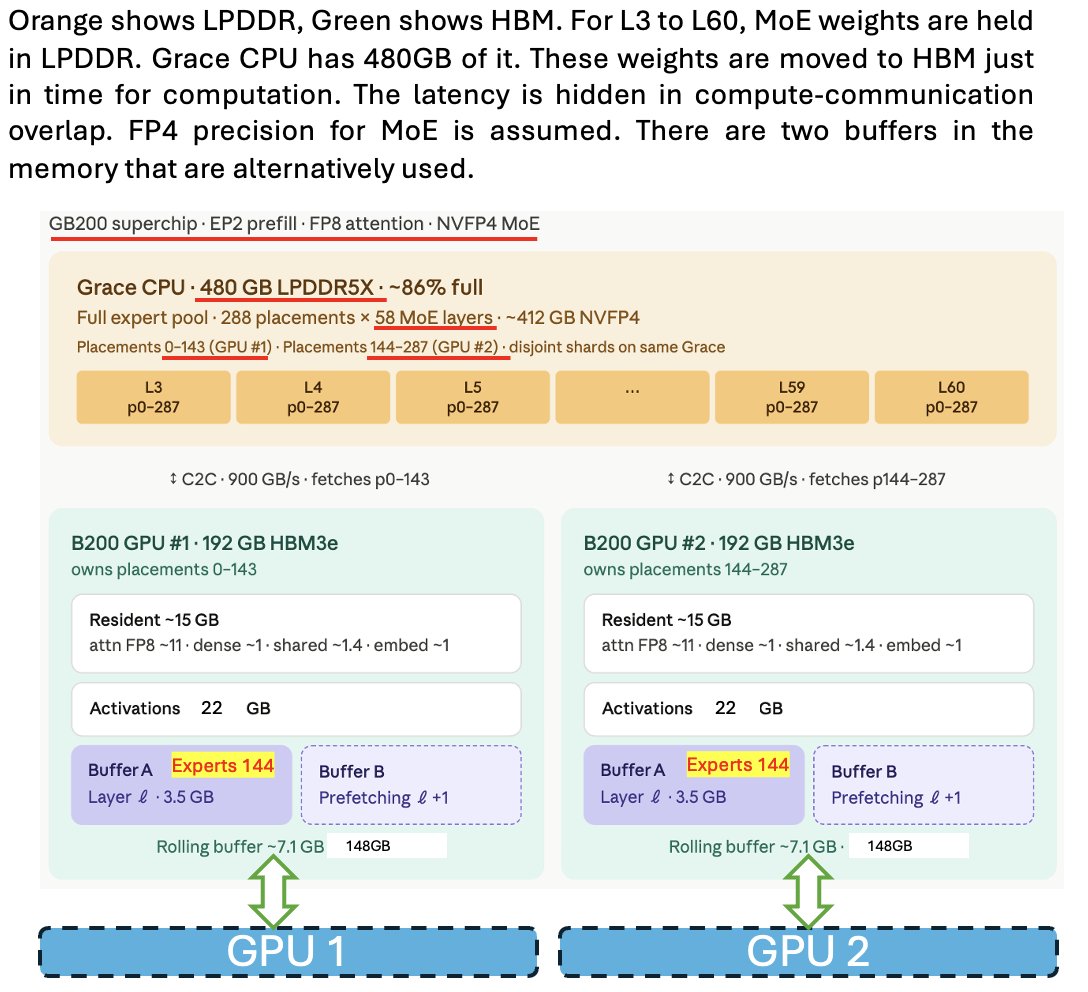
LPDDR memory 也很有潜力。它可以成为存放 weights 的地方,再按需把 weights 流式送入 HBM,从而减轻对 HBM 需求的压力。SGLang 团队写过一篇很好的博客讲这件事。下面这张图可以帮助理解这个方案是怎么工作的。
虽然 DeepSeek 没有专门为这件事单独做什么,但他们的 MoE 架构拥有大量 expert,再加上 4 bit weights,这让这个方案很容易实现。

这种创新,再加上超紧凑的 KV Cache 压缩方案,而且还是无损的,会显著降低 HBM 需求。
中国谁做 LPDDR?CXMT。他们在 LPDDR 的速度上只落后 0.5 代,在 density 上落后 1 代。差得并不远!再加上充足的 NAND,中国生态在不久的将来还会拥有充足的 LPDDR。这能缓解 compute 压力吗?答案是能。继续往下看。
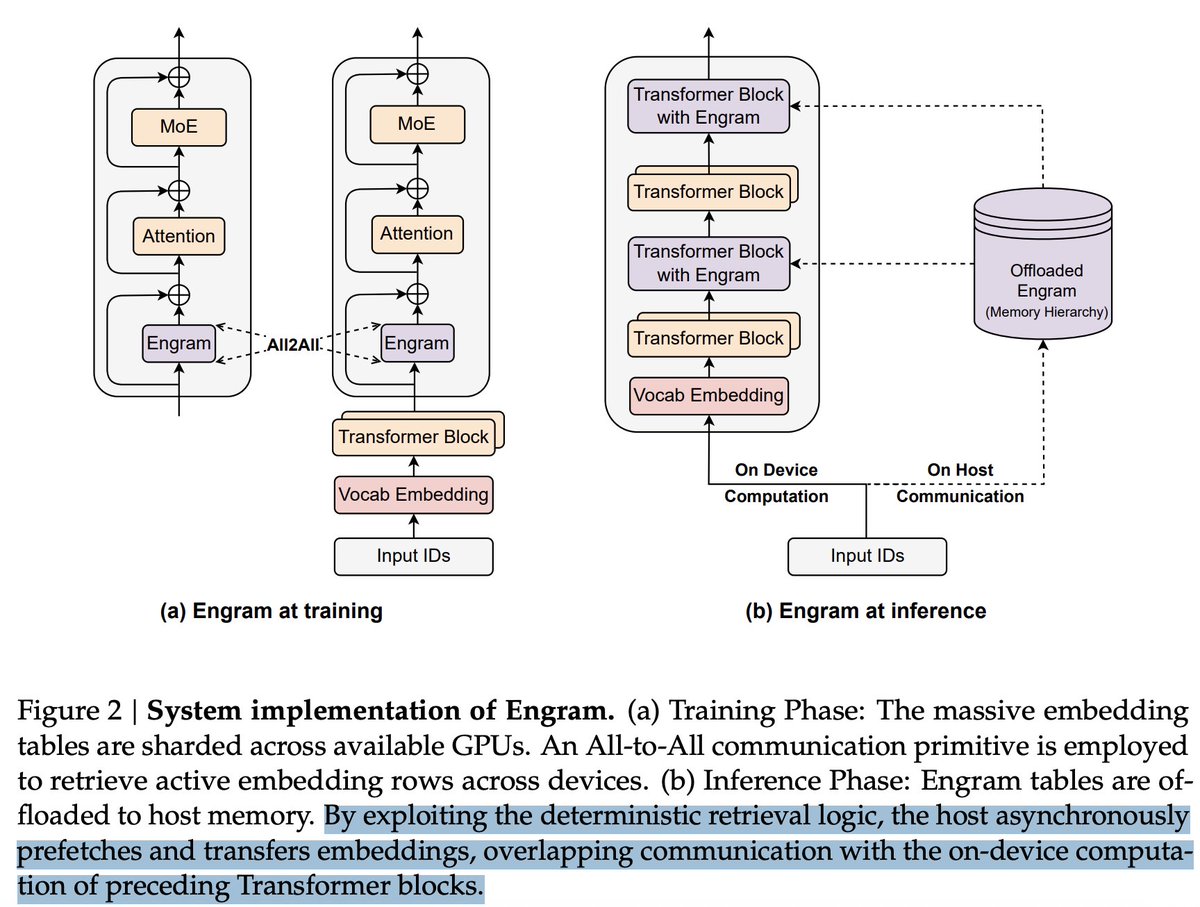
聪明地使用 memory,也能减轻 GPU/ASIC 的压力
很容易看明白,拿 NAND 存 KV cache,可以更长时间持有 KV cache,减轻 HBM 压力,还能避免 KV cache 重算,从而降低 GPU 和 ASIC 的 compute 压力。那 LPDDR 能不能也起到类似作用,除了作为一个按需流入 weights 的地方之外?答案也是能。
LPDDR 支持存放大量所谓的 Engram。在他们关于 Engram 的论文里,DeepSeek 说明了一点。MoE 通过 conditional computation 扩展 capacity,但 Transformer 本身缺少一种原生的 knowledge lookup primitive。所以它们不得不通过计算,低效地模拟 retrieval。他们引入了 Engram 这个模块,把经典的 N-gram embedding 现代化,变成基于哈希的 O(1) lookup,从而创造出另一条互补的 sparsity 轴,他们称之为 conditional memory。这样可以节省 computation,但需要 memory 来承载 embedding table,而这个表可能很大。这是典型的memory-compute substitution,但关键洞见在于,memory 这一侧每取回一 bit 的成本要便宜得多,一个 LPDDR lookup,对比一次穿过多层 transformer 的完整 forward pass,在大规模场景下这是极其划算的交换。他们就是这样用 memory 换 compute,来节省计算的!!!
这种 trade-off 非常值得:中国的 GPU 和 ASIC 在原始 FLOPs 上会长期落后于西方 GPU,因为它们做不到同样的 chiplet transistor density,也就是没有 EUV。它们在 packaging 上也落后不少。所以这种 trade-off 非常值得做,尤其是在 NAND 和 LPDDR 都能大量生产的前提下。
回顾 DeepSeek 的长期布局:
从这一连串创新来看,DeepSeek 的盘算不像是立刻去赚几亿美元。考虑到他们做过的所有选择,没有多模态,没有语音模型,视频更是谈不上,他们显然在下的是一盘耐心的 10 万亿美元大棋,目标是扶持出一套替代性的硬件生态。
这不只是让中国的 memory 厂商在中国和全球 AI 硬件舞台上成为关键玩家,也是在降低资源需求本身,好让 AI 模型能以更经济的方式训练和服务。这会让更多 GPU/ASIC 厂商以及网络芯片厂商都有机会,因为它们会成为可行选项。所有这些创新,同样也会帮助西方开源生态,以及新的硬件制造商。
所有迹象都已经在那里了。下面就把他们提出的这些创新详细回顾一遍:
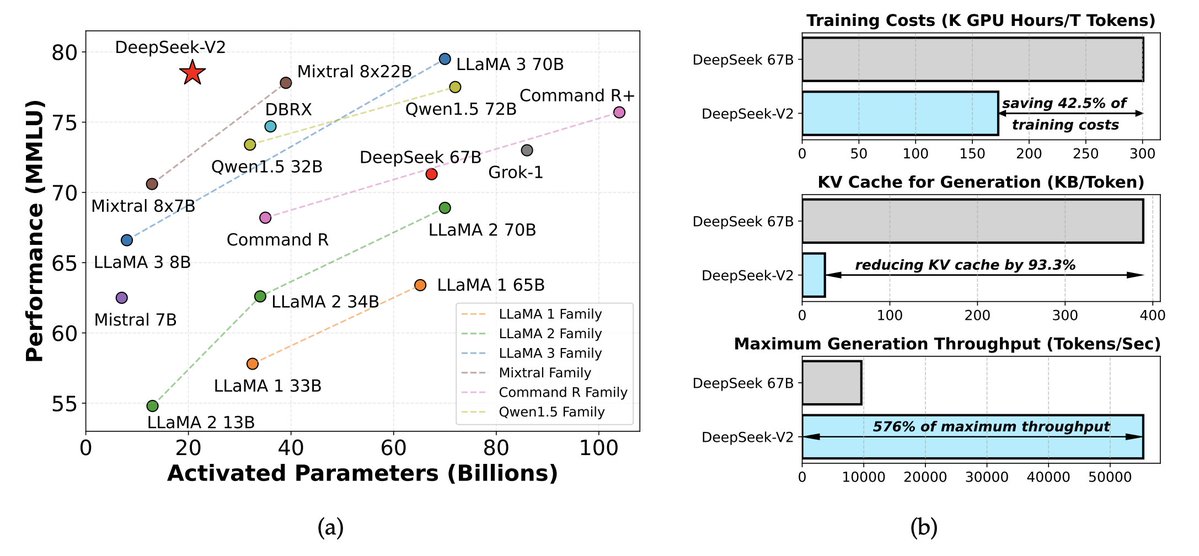
- Mixture of Expert(MoE)和 MLA,最早出现在 DeepSeek V2。MoE 让训练非常聪明的模型所需 compute 降低了 40% 到 50%。MLA 则让 KV cache 降低了 90%。这让把 KV cache 卸载到 SSD 变得很高效。这些想法来自他们 2024 年 5 月发布的 DeepSeek V2 论文。后来它又进一步解锁了 DeepSeek V3 的训练。当时这个模型几乎是 close source 状态,却只用了 2048 张被削弱的 H800 GPU。

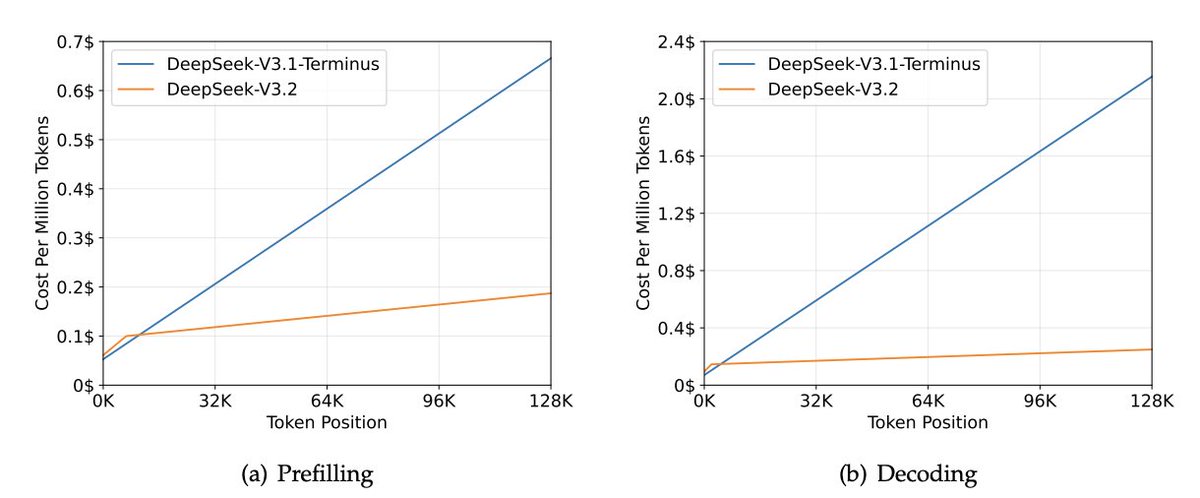
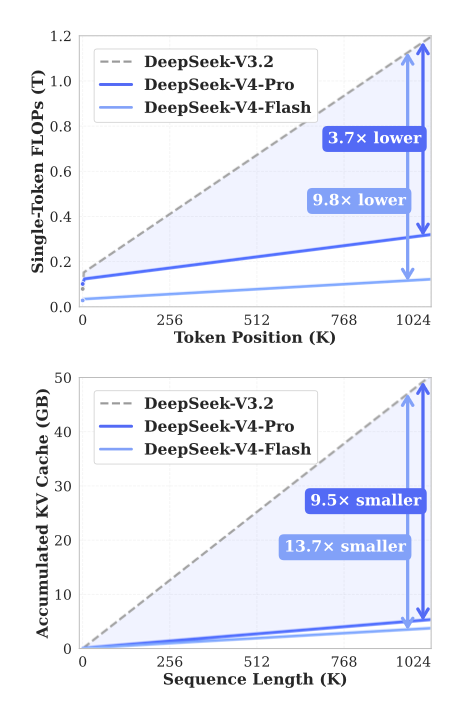
- DSA,出现在 DeepSeek V3.2 Exp,用来减少 long context 场景下的 compute,同时缓解 HBM bandwidth 的压力。它保证 computation 不会随着 context 变长而增长。请看下面的图,DeepSeek-v3.2 的处理时间会随着 context 保持平坦。
-
mHC,发表于 2025 年 12 月的论文 mHC: Manifold-Constrained Hyper-Connections。mHC 是 DeepSeek 提出的一项宏观架构创新,它重新发明了 transformer layer 之间的信息流动方式。它不再使用自 ResNet 时代就存在的标准 residual connection,也就是 (x + F(x)),而是把 residual stream 扩展成多条并行的信息高速通道,并允许它们之间进行可学习的混合。更关键的是,这些 mixing matrix 会被约束为 doubly stochastic,也就是通过 Sinkhorn-Knopp projection 投影到 Birkhoff polytope 上,这在数学上保证了无论网络有多深,signal magnitude 都能被保留下来。
-
这解决了灾难性的稳定性问题,之前 unconstrained Hyper-Connections 会碰上这个问题。这个思路最早来自 ByteDance。当模型规模到 27B 时,signal amplification 会爆炸到 3000 倍,导致训练彻底崩掉。
-
计算成本非常低:mHC 只增加了 6.7% 的 wall-clock 训练开销,因为它并不改变 attention 或 FFN layer 的 FLOPs,只是改变它们输出在 layer 之间的路由方式。
-
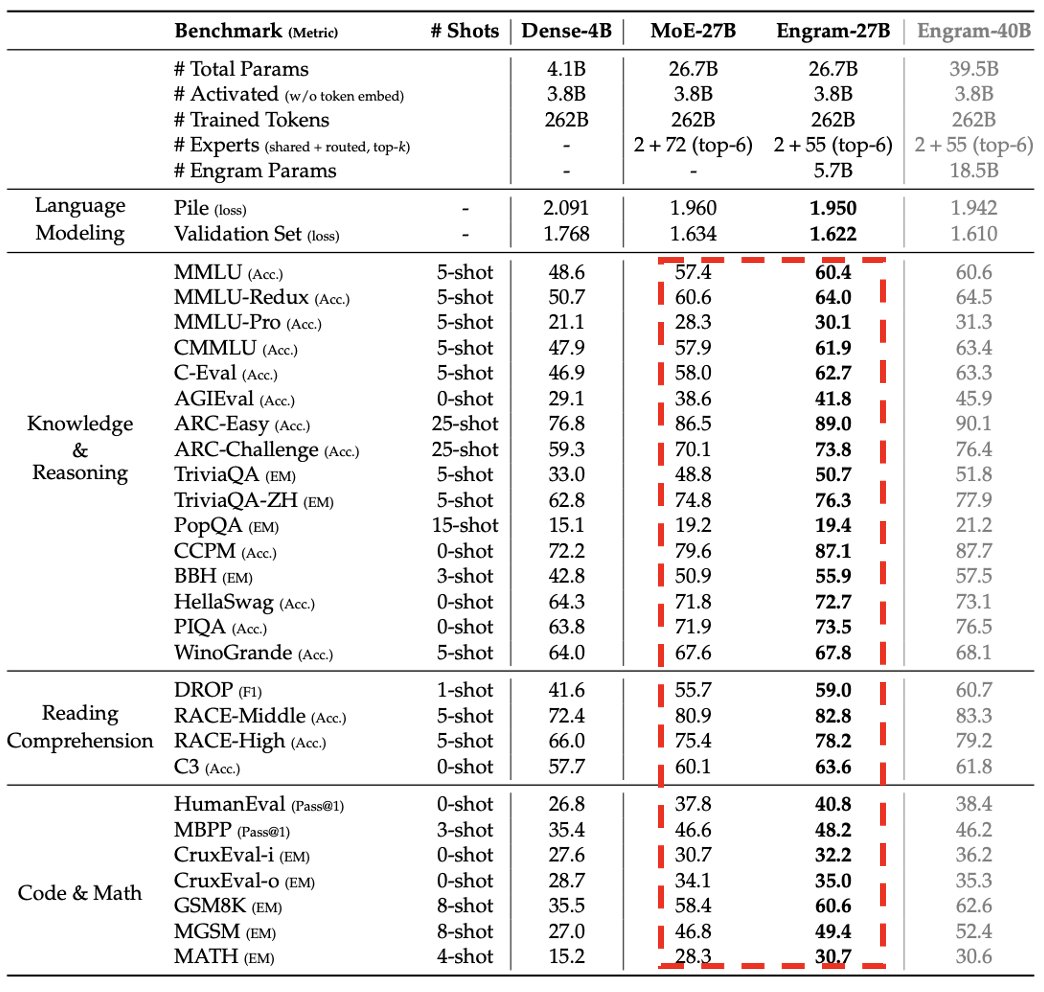
但性能收益相当可观:在 27B parameter 规模上,mHC 在 BIG-Bench Hard reasoning 上提高了 7.2 分,在 DROP 上提高 3.2 分,在 GSM8K math 上提高 2.8 分,在 MMLU general knowledge 上提高 1.4 分,而且模型大小不变,compute budget 也几乎一样。
本质上,mHC 通过给网络一个更丰富、更有表达力的信息路由拓扑,在几乎不增加额外 FLOPs 的前提下,实现了每个 parameter 对应更高的 intelligence。
- CSA、HSA,在 2026 年 4 月发布的 DeepSeek V4 中提出, 通过压缩 KV token,把 KV 需求再压低 90%,同时大幅减少所需 FLOPs,从而同时缓解 HBM 和 GPU/ASIC 的压力。
https://arxiv.org/pdf/2601.07372
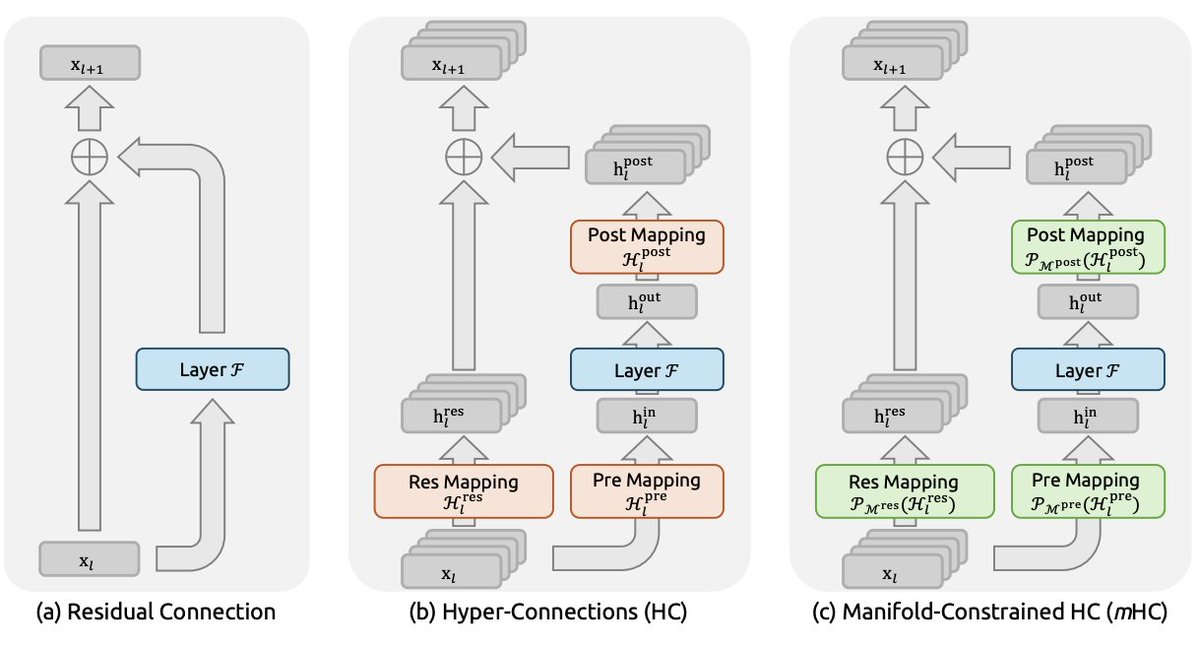
- Engram,发表于 2026 年第一季度,他们在这里用 memory,也就是 LPDDR memory,去换 compute。下面这张更详细的图展示了 Engram 在同样总体参数预算下带来的性能提升。
https://x.com/bookwormengr/status/1883712073814954379?s=20
- 他们极端专注于 Compute 和 Communication 的重叠利用,而 Dual Path 之类的创新,也可以理解为对资源约束的一种绕法。但 DeepSeek 还更进一步,会直接给硬件厂商提供 ASIC design 建议,确保他们不会浪费宝贵的 silicon 资源。这段内容来自 DeepSeek V4 论文。
- 对 TileLang 的投入,也一致说明他们不只是想解决自己的 compute 紧张,而是想让中国硬件生态能真正和西方生态竞争。借助 TileLang,可以只开发一次 kernel,也就是 computation code,然后在多个具备 TileLang backend 的硬件平台上成功运行。我预计其他中国实验室也会加入进来,这会帮助中国硬件厂商从侧面应对 CUDA moat。它同样也会解锁更多西方硬件,比如 AMD。 Note: 中国很多 AI 平台要么提供 CUDA compatibility,要么提供 CUDA translation layer。Moore Threads、MetaX、Biren 和 Iluvatar CoreX 是最兼容 CUDA 的中国芯片,它们主要靠 translation layer 实现。理论上说,它们并不需要 TileLang。
https://arxiv.org/pdf/2601.07372
大规模 RL 和 RSI:
随着能拿到更多 compute,也就是因为潜在硬件选项变多了,同时 compute 需求本身又在下降,DeepSeek 就能去做更有野心的训练项目,尤其是 RL post training。RL 需要生成大量 trajectory,也就是数万亿 token 的生成,成本会很快飙升。再进一步说,如果你要训练 1M context model,那你就需要生成同样长度的 trajectory。训练这种超长 trajectory 的模型,也就意味着它能处理 long horizon task。
另外,由于可选硬件变多,DeepSeek 手里的硬件资源也会更多,这会推动 automated research,也就是 RSI。RSI 指的是由 AI 自己来设计并执行实验。这种方法包含大量 trial and error,成本会非常快地膨胀。但 RSI 对于探索整个 design space 非常重要。DeepSeek 如果想先碰到 AGI,再走向 ASI,就必须先具备 RSI 能力。
DeepSeek 今天做的事,就是行业明天会做的事:
DeepSeek 围绕 Mixture of Expert、MLA、DSA 做出的创新,已经被全球其他 AI 实验室和中国实验室陆续接住了。
比如,GLM 系列模型的开发者 ZAI,就使用了 MLA 和 DSA。Kimi(Moonshot)也采用了 MLA,而且并不避讳承认自己的架构就是建立在 DeepSeek 架构之上的。反过来,DeepSeek 也在使用 Muon optimizer,而这是 Kimi(Moonshot)最早拿来做大规模训练的。
(NOTE: - MoE 是 Google 在 2027 年发明的,Naom Shazeer 是关键作者。DeepSeek 把它应用到了超大规模上,并发展出自己的一套技巧。 - Muon(MomentUm Orthogonalized by Newton-Schulz)optimizer 由机器学习研究者 Keller Jordan 于 2024 年底提出。Kimi(Moonshot)团队是第一个把它用到超大规模上的团队。)
那怎么赚大钱呢?:
我们来看看 OpenAI 这个有意思的例子。OpenAI 曾基于消费里程碑,获得以低价购买 AMD 和 Cerebras 股票的 warrant/options。这对 AMD 和 Cerebras 来说是笔很好的交易。OpenAI 对它们做出承诺,也会让它们更有可能长期成功。
AMD 公告中的原话是这样说的:As part of the agreement, to further align strategic interests, AMD has issued OpenAI a warrant for up to 160 million shares of AMD common stock, structured to vest as specific milestones are achieved. The first tranche vests with the initial 1 gigawatt deployment, with additional tranches vesting as purchases scale up to 6 gigawatts. Vesting is further tied to AMD achieving certain share-price targets and to OpenAI achieving the technical and commercial milestones required to enable AMD deployments at scale.
我预测,DeepSeek 也会和多家中国 memory、ASIC、CPU 以及 networking stack 厂商签下类似协议,并与它们紧密合作,让它们的硬件栈真正能跑最领先的 AI workload。
考虑到西方,包括东亚盟友在内,所有 AI 股票的合并估值早就远远超过 10 万亿美元。这样一种以股权奖励合作方的方式,能让 DeepSeek 帮助中国也创造出同样巨大的产业,同时分到属于自己的一块蛋糕,并最终实现1 万亿美元估值。
这样一来,他们不仅能赚到更多钱,也能实现他们自己所说的AGI for everyone。梁文锋是 Jim Simmon 的铁粉,不可能聪明到这个程度却错过这种资本主义玩法。
**如果你回头看 DeepSeek 到目前为止做过的所有事,这几乎是唯一说得通的解释……
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
关于这些创新的详细博客会在本周末发出来。有兴趣的话可以关注我的 substack https://polymath707.substack.com/