我通过用 5 年工作历史、1.5 万份文档、350 万字内容,以及我工具栈里的每一个工具,打造了一个“第二大脑”,让自己作为 @mercury 产品副总裁的生产力翻了一倍。它在本地运行,是我每次使用 LLM 时的核心组成部分,并且每天都在变得更好。
今天,我想分享用来构建它的技术栈、工作流和提示词:
背景
我是 @mercury 的产品副总裁。说得长一点,就是我开很多会,在不同工具里消化大量内容,比如 Linear、Slack、Notion、数据分析,同时还得确保自己真的把事情做完。在一家公司工作了 5 年,又是个信息成瘾者,所以从 2021 年到今天,关于 Mercury 的事,我基本上就是一部会走路的百科全书。但最近我发现,我的职责范围和工作量已经意味着,我不可能让每个盘子都一直转着。
有一天,我在刷 X,看到一系列帖子吸引了我的注意。最开始是 @tobi 的 QMD。QMD 是一个本地向量搜索工具。随后又有几条帖子出现,把一些点在我脑子里连了起来:
-
Claude Code 发布了 hooks,也就是按事件注入提示词
-
GasTown / OpenClaw 发布,展示了 orchestrator 写入 memory、委派 sub-agent 的能力,当然还有很多其他模式
-
MCPs/CLIs 达到了临界规模,我日常核心工具里已经有足够多可以直接使用,不必再去找管理员要 API key
-
@tylercowen 做了一次访谈,深入谈到“为 AI 写作”,这点击中了我:已经存在的工作产出里,到底有多少是我没有利用起来的?
我决定,是时候动手构建了。
准备工作(全程约 1-2 小时)
首先,我需要一个资料库,装下所有我可能知道的内容。所以我下载了自己在 Mercury 工作以来创建过的每一份文档,以及任何相关的产品战略、分析、复盘、执行反思等。最后得到的是超过 1.5 万份文档和 350 万字。也许我都读过,但大部分已经忘了。这些内容变成了一个文件夹,我直接叫它“raw data”,然后在电脑上用 QMD 为它建立索引。
为了看看这是否有效,我用 Claude Code 随机询问这个知识库中的记忆和令人意外的洞察。当我看到向量搜索比基于文本的搜索强大这么多时,那种惊喜让我有信心继续做下去。我问了一个问题,想知道它觉得我会喜欢哪些书,结果它给出的推荐好到有点诡异。我觉得这是这段旅程里我最好的建议:每一步都要测试!很容易陷入只是在局部最优点上继续爬坡。
训练我的大脑,并连接到我的工具(约 2 小时)
有了所有原始数据之后,我需要帮助它理解我是谁、我的目标是什么、我使用哪些工具。所以我走了三条路径:
-
解释我自己。为了创建第二大脑,它需要知道我的大脑在做什么。我写了一份 me.md,说明我是谁,包括工作和生活,给了它我的目标、过去 5 年的绩效评估,以及一组个人优先事项。最让我谦卑的一点,是系统根据我自己的绩效评估指出,我多年来一直在犯同一个战略错误,而且就在我设置这个系统的那一周,我还在犯这个错误。
-
“蒸馏”数据。我启动了一个 agent team,让它们用 me.md 和知识库,在我和原始知识库之间创建一组文档。这个想法很大程度上来自这样一个事实:LLM 经常把更小的模型蒸馏出来执行任务。我不知道这对我有没有帮助,但 Agent Teams 刚刚发布,所以我让一群 agent 从知识库中找出我们做过的主要“主题”,给出带来源的历史脉络,并总结关键经验。这些内容创建成了一个 context.md 文件夹。
-
工具。我用几个工具,比如 Google Docs、Linear、Notion、Metabase。幸运的是,大多数工具在 Claude Code 上都有连接器,或者这些公司正在积极发布 MCPs/CLIs。少数没有,但我启动了一些特定技能,用来编写直接 API 调用,完成类似“为 XYZ 跑一个查询”这样的任务。
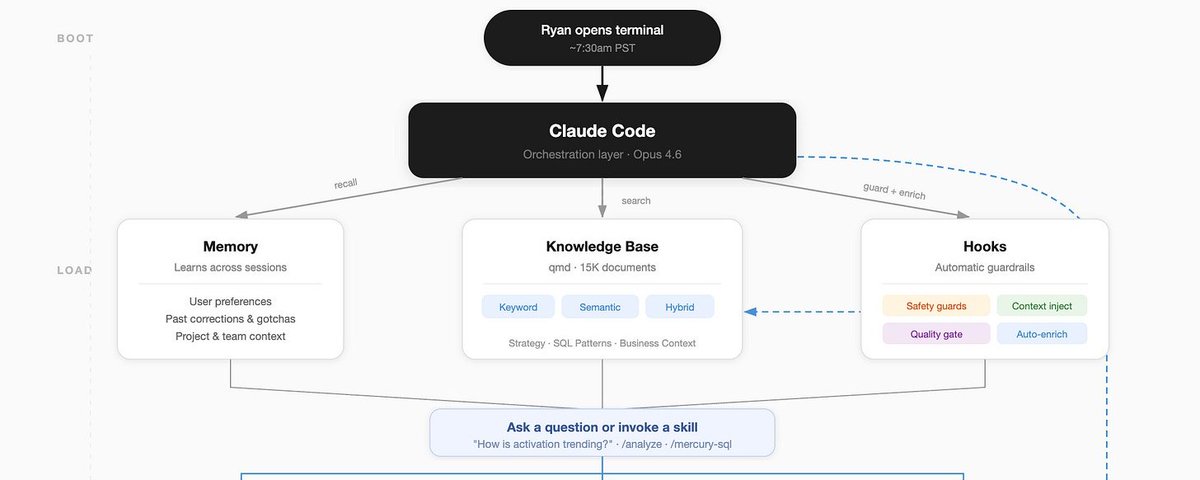
Claude 已经能访问关于我的全部信息、我使用的工具,以及我所有工作的庞大资料库。但它真的知道什么吗?有人知道吗?
接上线(少于 1 小时)
到这个阶段,我已经有了太多文字和文档,是时候真正找到用途,或者干脆弃船了。但我不想每次都自己去搜索这些内容。也就是这个时候,“hooks”吸引了我的注意。
Claude Code 的 hooks 允许你把内容插入提示词里,而不需要主动询问,也可以在 session 开始时、工具使用之后,或 session 停止时插入。通过 UserPromptSubmit hook,我让自己的 Claude Code 可以使用 qmd 查找与我提示词相关的人名、主题和具体文档。
这是一个让人 nerd-out 的时刻,但当你在 Finder 里搜索文件时,它大多只是基于名称和原始文本搜索。而 QMD 可以把上下文带进搜索里。我的系统会先判断查询意图,然后用两种技术之一返回结果:
-
vsearch(语义/向量)——理解我的问题含义。“How's the funnel performing?” 会找到关于转化率的文档,即使那些文档里没有写 “funnel”。
-
BM25(关键词)——精确术语匹配。它能抓住专有名词、缩写、具体指标,这些是语义搜索可能漏掉的。
把上下文注入提示词之后,很快我就看到结果质量提升了。我可以带着懒散的行话和有限的背景过来,然后让 Claude 用我的“第二大脑”内容补全它。这让我看到了把正确上下文和工具放进每一次查询里的力量。之后开始发生一些奇怪的事……但这个稍后再说,因为我还有一个重大步骤要解锁。
让它学习
GasTown 和 OpenClaw 的 agent 似乎会变得更好,因为它们会持续更新自己的 memory,也就是一个写入式的 .md 文件。所以我开始想,我是不是也可以用这种方式学习。我发现,进行自我反思、增量更新新知识,大致有三个时间尺度:
-
每个 session。我创建了一个 /learn skill,它会读取一次对话,查看我当时试图完成的任务,然后更新我的 .md 文件。这对经常报错的 MCP 特别有用。一旦经历过一次,提示词就会变得更好,从而避免同样的错误。
-
每天/每周。我用一个早晨的 chron job 生成每日简报,包含当天将要发生的事情,以及来自知识库的相关上下文。然后用这些内容自动更新我对进展的记忆。
-
每月月底。每个月结束时,我会和自己的 Claude Code 做一次关于世界状态的访谈:我们从这个月原本想做什么开始,回顾实际进展如何,哪些做得好,哪些做得差,下个月应该做什么。
实际使用是什么样子
描述自己如何使用一个大脑,或者第二个大脑,是一件很奇怪的事。但我真的相信,整体上我的生产力翻了一倍,所以我想分享一些实际例子。
秒级回忆速度。现在,从我的记忆干草堆里找针变得好得多。我的一天,以及大多数工作任务,都会从 Claude Code session 开始。无论是写文档、做分析,还是回答问题,现在都更快,也更全面。
不再需要会议准备。我的一天从一份关于身边正在发生什么的总结开始,包括会议、Linear 更新、GitHub push、我还没回复的 Slack 消息。因为工作上下文、计划、1:1 会议笔记等都在一个地方,所以当我进入一次 1:1 时,只需要针对即将到来的会议写一两个 prompt,我就已经准备好面对任何话题。
不再遗漏行动项。这很可能是深度使用这个系统后自然涌现出来的结果。但我每天结束时会问:“今天有什么我忘了做的吗?”它经常能找出一两个我忘记收尾的互动。跨工具综合真的太强了。
实时反馈。我已经工作了大约 15 年,而我从经理那里得到反馈的最高频率,通常也就是两周一次,或者最多每周一次。因为这个系统有我的绩效评估,它知道我从经理那里得到过什么反馈,也会指出我正在重复那些曾经被反馈过的模式。
下面是一段真实对话的样子:
主动探索模式
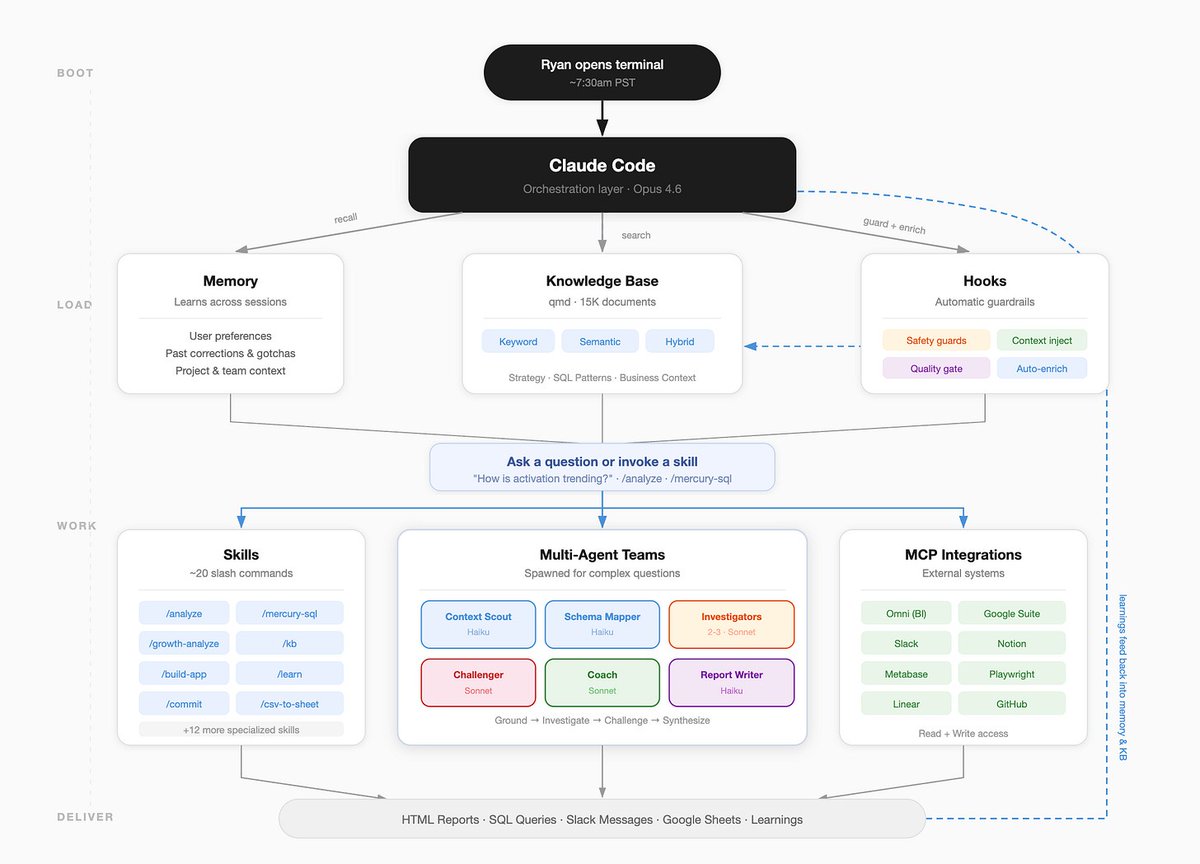
因为这个系统非常能干,也非常了解情况,而我在一份工作里做了 5 年之后,对自己的视角又太有偏见,所以我开始定期让它思考公司的优先事项、我的全部知识和经验。它能访问我拥有的所有工具,因此这个第二大脑系统已经可以做自主研究,帮助我思考如何解决自己的问题。
到这一步,它已经不再是一个连贯的叙事了,因为我正在主动深陷其中:我开始叠加其他新功能,比如 Chron/Scheduled jobs、Agent Teams/Swarm、@karpathy 的 AutoResearch 能力、@lennysan 的访谈档案……这些会流入我的每日简报、被分区写进我的 memory,并变成可复用的 skills。
第二大脑系统(由它自己绘制)
一个你可以使用的提示词
I want you to help me build a "Second Brain" — a persistent knowledge system that runs in parallel to my work using Claude Code. We'll do this in 5 phases. Walk me through each one interactively. Don't skip ahead — confirm each phase is working before moving on.
## Phase 1: Interview Me & Create my Profile
Interview me to create a file at ~/Documents/second-brain/me.md that captures:
- Who I am (role, company, responsibilities)
- What I'm optimizing for (goals, priorities, what success looks like)
- My working style (tools I use daily, how I communicate, what frustrates me)
- My growth edges (feedback I've gotten, patterns I want to break)
- What I care about outside work (interests, values — helps with recommendations)
Ask me 5-7 questions conversationally. Don't make me fill out a template. Write the file when you have enough.
## Phase 2: Build the Knowledge Base
Help me collect and index my work history:
1. Ask me where my documents live (Google Docs, Notion exports, local files, etc.)
2. Help me export/download them into ~/Documents/second-brain/raw/
3. Install QMD (https://github.com/tobi/qmd) if not present: `bun install -g qmd`
4. Create a QMD collection from the raw folder: `qmd collection add Documents/second-brain/raw`
5. Index it: `qmd update`
6. **Test it together** — ask me for a few things I remember working on, then search the KB to see if it finds them. Try both `qmd search` (keyword) and `qmd vsearch` (semantic). If results are bad, we troubleshoot before moving on.
## Phase 3: Distill & Summarize
Using me.md + the knowledge base, create ~/Documents/second-brain/summaries/ with:
- strategic-context.md — what my company/team is trying to do and why
- role-context.md — my specific responsibilities and how I fit in
- historical-context.md — key decisions, pivots, lessons from my work history
- team-context.md — who I work with, dynamics, stakeholders
- personal-growth.md — patterns in my feedback, coaching themes
For each file, search the KB extensively (10+ queries mixing keyword and semantic search), cite specific source documents, and flag where you're inferring vs. quoting.
## Phase 4: Wire Up Automatic Context Injection
Create a Claude Code hook that enriches every prompt with relevant KB context.
Create ~/.claude/hooks/context-enrichment.sh that:
1. Extracts key terms and names from my prompt
2. Runs parallel searches (semantic + keyword) against the QMD collection
3. Returns the top results as context injected into the prompt
4. Completes in <2 seconds (kill searches that take longer)
Register it in ~/.claude/settings.local.json as a UserPromptSubmit hook.
The hook should output a <context> block with search results so Claude sees it but it doesn't clutter my conversation.
Test it: I'll type a lazy prompt about something in my KB and we'll see if the hook injects useful context.
## Phase 5: Create the Learning Loop
Set up three learning mechanisms:
### Per-session: /learn skill
Create ~/.claude/skills/learn/SKILL.md that:
- Reviews the conversation for mistakes, surprises, and validated approaches
- Updates ~/.claude/CLAUDE.md with new tool gotchas, workflow preferences, corrections
- Saves important context to memory files in ~/.claude/projects/-Users-{me}/memory/
- Bias toward brevity — only save what's genuinely new and useful for future sessions
Create a script at ~/.claude/scripts/morning-brief.sh that:
- Checks my calendar (if Google CLI is available)
- Searches the KB for context related to today's meetings
- Summarizes any updates from connected tools
- Outputs a brief I can read in 2 minutes
Help me set it up as a launchd job that runs at my preferred morning time.
### Per-month: Retro prompt
Create ~/.claude/skills/retro/SKILL.md that walks me through:
- What were we trying to accomplish this month?
- How did it actually go?
- What patterns are emerging (good and bad)?
- What should change next month?
- Update summaries/ with anything that's shifted.
---
## Rules for this whole process:
- Ask before installing anything
- Test each phase before moving to the next
- If something fails, don't retry — propose 2 alternatives
- Keep all files in ~/Documents/second-brain/ (KB) or ~/.claude/ (config)
- No over-engineering — functions over classes, scripts over frameworks
- Everything should be runnable, debuggable, and modifiable by me later
Start with Phase 1. Interview me.
行动邀请
我分享这套系统,主要是因为我一直受到类似系统的启发,也希望它能变得更好。如果你用了它,哪些地方有效?哪些地方没用?还有没有什么线索是我应该继续追下去的?