We approach building the Cursor agent harness the way we'd approach any ambitious software product. Much of the work is vision-driven, where we start with an opinion about what the ideal agent experience should look like.
From there, we form hypotheses about how to get closer to that vision, run experiments to test them, and iterate using quantitative and qualitative signals from evals and real usage. That process depends on having the right online and offline instrumentation, so we can tell when a change actually makes the harness better.
When we get early access to new models, all of these approaches converge. We spend weeks customizing our harness to a model's strengths and quirks until the same model inside our specially tuned harness is noticeably faster, smarter, and more efficient.
Occasionally we discover step-change improvements. More often, though, improving the harness is a matter of obsessively stacking small optimizations that together make agents better at building software.
Evolving the context window
At the heart of interacting with large language models is the context window. When asking the agent to build something, the context window starts with the system prompt and tool descriptions, followed by the current state of the conversation, and finally the user's request.
The way we populate and manage that window has evolved significantly over the history of Cursor.
When we first developed our coding agent in late 2024, models were much worse at choosing their own context and we invested lots of context engineering work into creating guardrails—for example, surfacing lint and type errors to the agent after every edit, rewriting its file reads when it requested too few lines, and even limiting the maximum number of tools it could call in one turn.
We also provided substantial amounts of static context that was always available to the agent at the start of each session. At various points, that included the folder layout of the codebase, code snippets that semantically matched the query, and compressed versions of files that the user manually attached.
That is mostly long gone.
We still include some useful static context (e.g., operating system, git status, current and recently viewed files). But we’ve adapted to increasing model capability by knocking down guardrails and providing more dynamic context, which can be fetched by the agent while it works. In an earlier post, we did a deep dive into some of our techniques behind dynamic context, many of which have since been adopted by other coding agents. Much of our work now focuses on providing more ways for the agent to dynamically pull context and interact with the world.
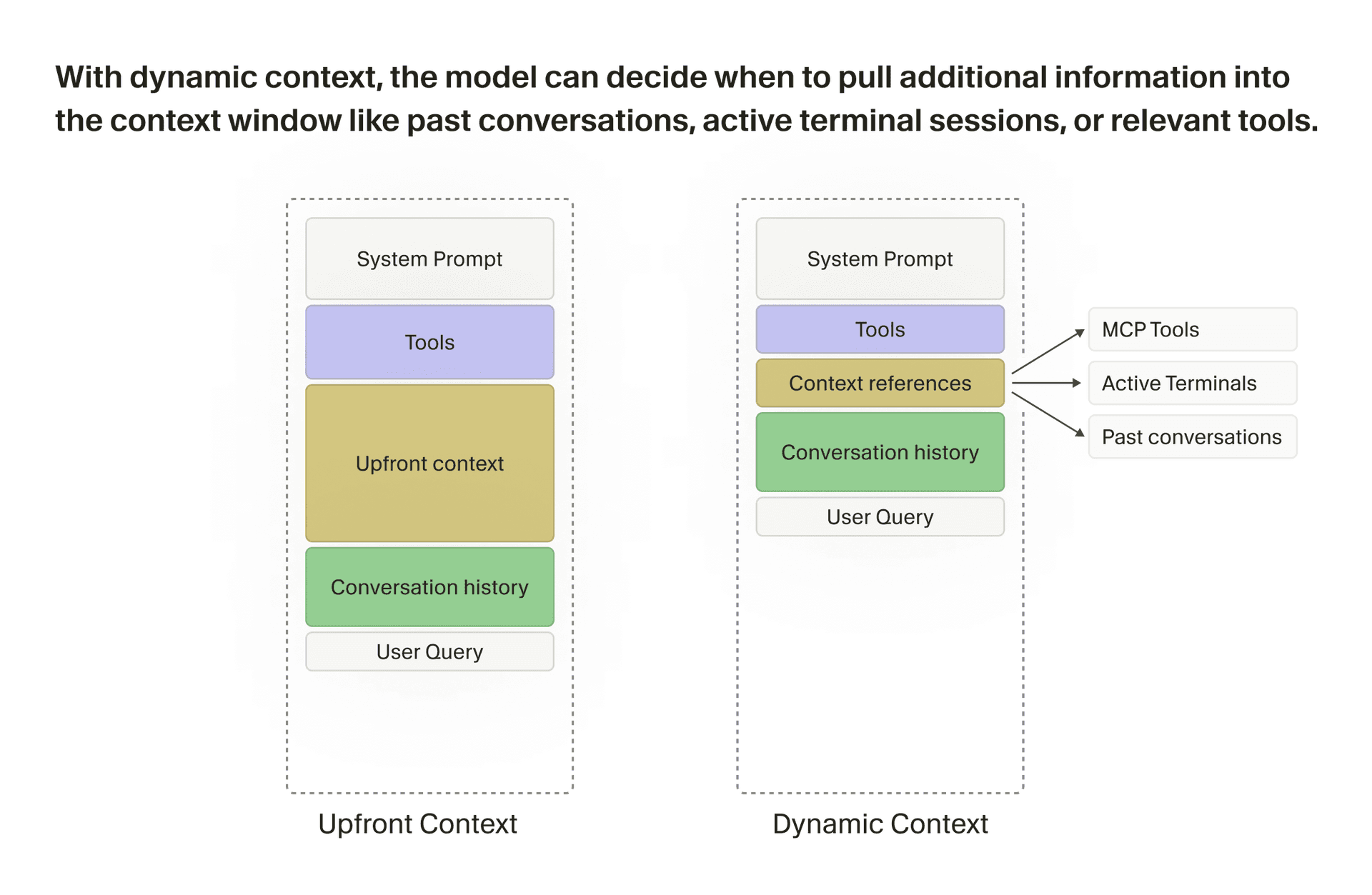
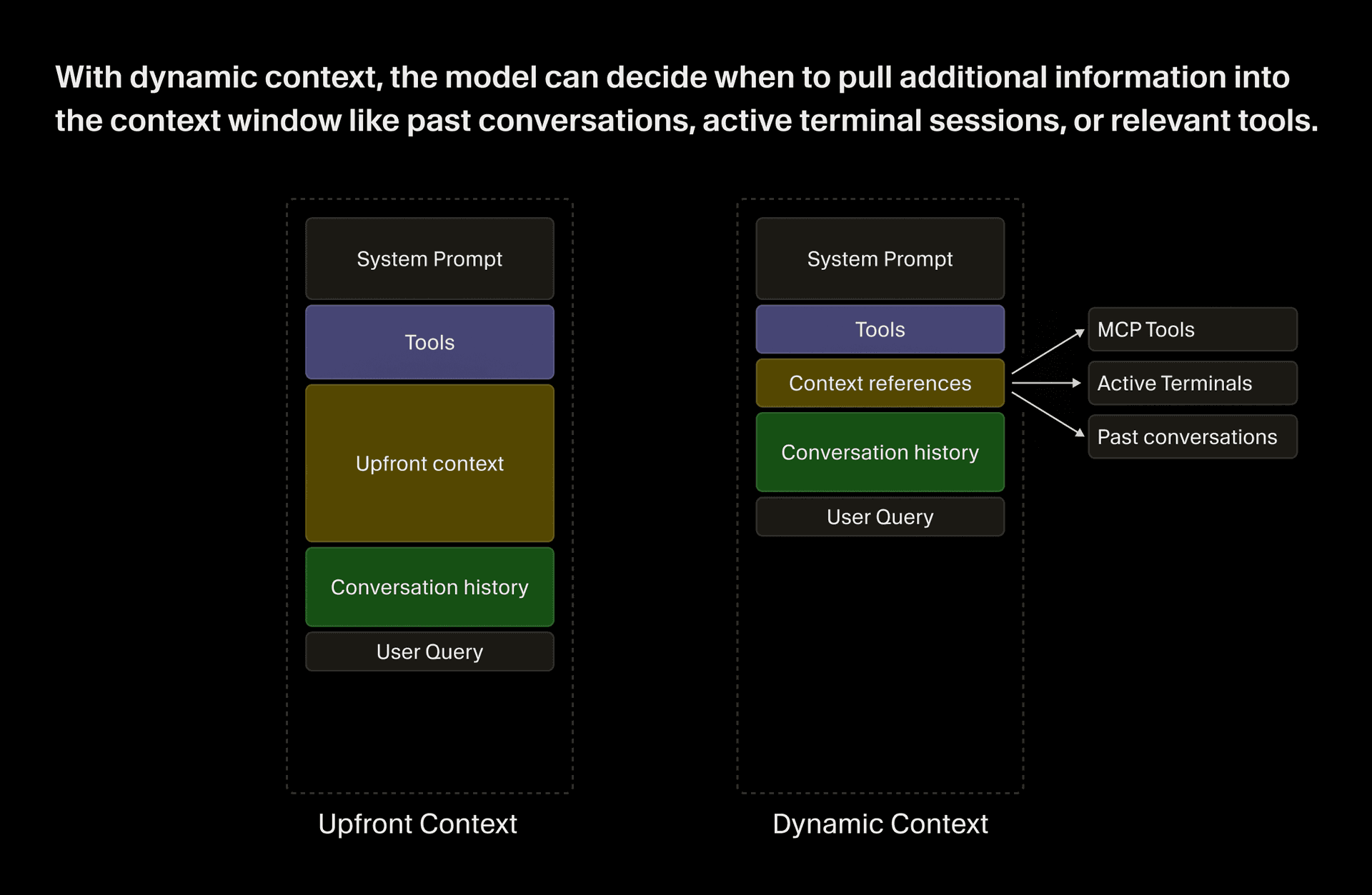
Two ways of assessing harness changes
The harness and the model together determine how good the agent is, but "good" is hard to pin down. To locate it, we've built several layers of measurement.
We maintain public benchmarks alongside our own eval suite, CursorBench, which gives us a fast, standardized read on quality and lets us compare across time. But even the best benchmarks only approximate real usage, meaning we’d miss important signals if we relied on them entirely.
So we also run online experiments where we deploy two or more harness variants side by side and A/B test them on real usage. We measure agent quality in these tests through a variety of metrics. Some are straightforward like latency, token efficiency, tool call count, and cache hit rate. Those are directionally useful but still don’t get at fuzzier and more important questions of whether the agent actually did a good job. We measure those in two ways.
The first is the “Keep Rate” of agent-generated code. For a given set of code changes that the agent proposed, we track what fraction of those remain in the user’s codebase after fixed intervals of time. This allows us to understand when users have to manually adjust the agent's output, or need to iterate and have the agent fix things, indicating the agent’s initial response was of lower quality.
Second, we use a language model to read the user's responses to the agent’s initial output in order to capture semantically whether the user was satisfied or not. A user moving on to the next feature is a strong signal the agent did its job, while a user pasting a stack trace is a reliable signal that it didn't.
Sometimes these online tests tell us to shelve an idea that seems promising. In one experiment, we tried a more expensive model for context summarization and observed it made a negligible difference in agent quality that wasn’t worth the higher cost.
Tracking and repairing degradations
As we add more models and capabilities, the harness gets more complex with more potential states, just like any piece of software. With this comes more surface area for bugs to crop up, many of which we can only detect at scale.
The agent’s tools are one of the broadest surfaces for bugs, and tool call errors can be extremely harmful to a session in Cursor. While the agent can often self-correct, errors remain in context, wasting tokens and causing “context rot,” where accumulated mistakes degrade the quality of the model's subsequent decisions.
Sometimes, the agent can be blocked or go off the rails completely after a failed tool call. Though metrics like tool call volume and error rate don’t directly measure whether the agent did a good job, they act as indicators that can point to a broader issue.
Any unknown error represents a bug in the harness, and we treat it accordingly. But many errors are “expected,” for example the model occasionally proposing an incorrect edit or trying to read a file that doesn't exist. We classify these expected errors by cause. InvalidArguments and UnexpectedEnvironment capture model mistakes and contradictions in the context window, while ProviderError captures vendor outages from tools like GenerateImage or WebSearch.
We have several other classifications like UserAborted and Timeout which altogether encompass most expected errors.
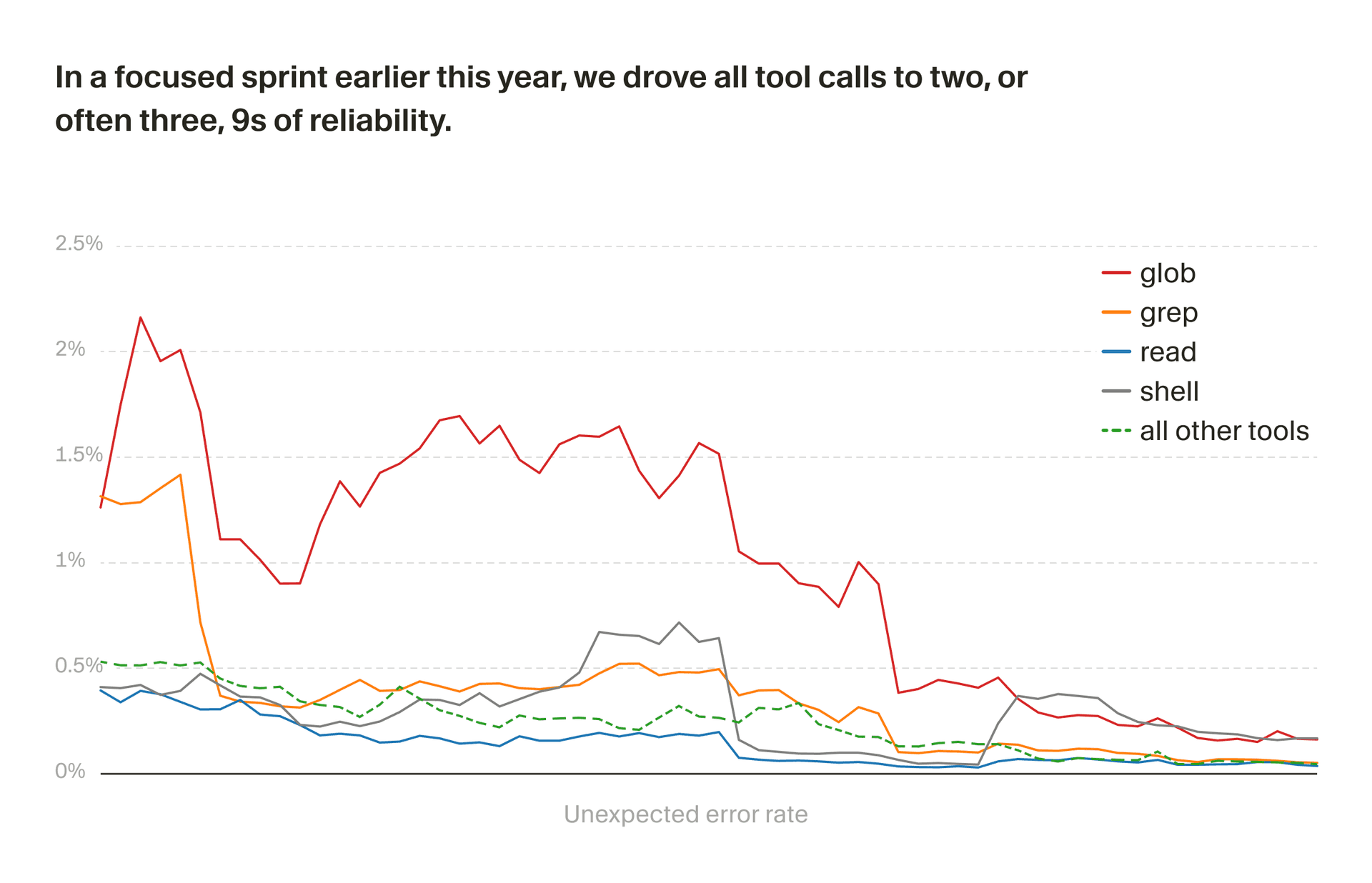
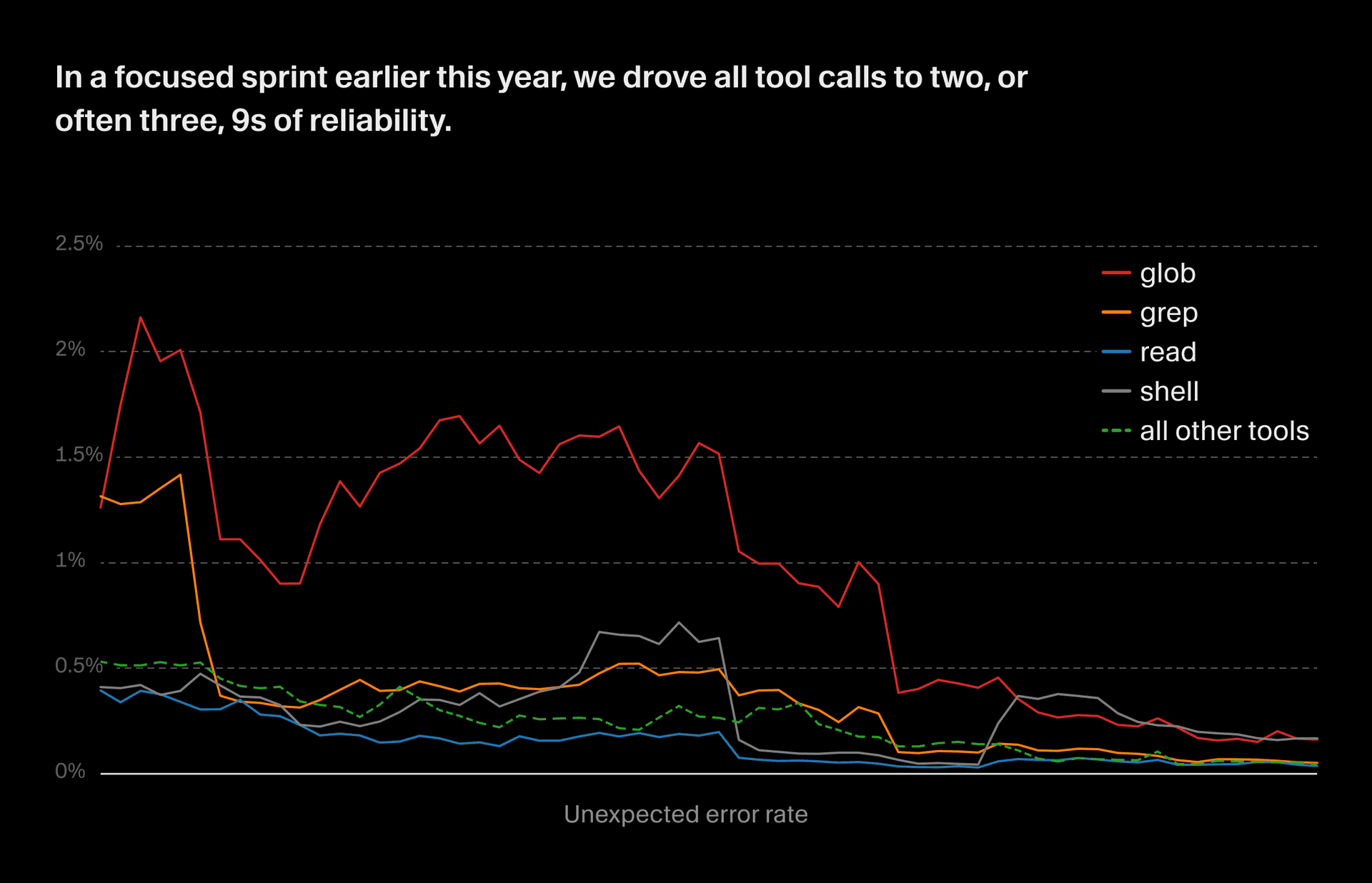
We define alerts based on these metrics to catch significant regressions that make it into production. Since unknown errors are always bugs, we alert whenever the unknown error rate for any tool exceeds a fixed threshold. But it can be tricky to tell whether expected errors represent a bug in the harness or expected behavior.
For example, a grep search timeout might be because of a performance issue with the tool, or the codebase might just be huge and the model formed an inefficient query. To deal with this, we have anomaly detection alerts which fire when expected errors significantly exceed the baseline. We compute baselines per-tool and per-model, because different models may mess up tool calls at different rates.
We also run a weekly Automation equipped with a skill that teaches the model how to search through our logs, surface issues that are new or recently spiked, and create or update tickets in a backlog with an investigation. We lean heavily on Cloud Agents to kick off fixes for many issues at once, and can even trigger them directly from Linear.
This process is part of the way we’re instantiating an automated “software factory” for our agent harness. Over the course of a focused sprint earlier this year, we drove unexpected tool call errors down by an order of magnitude.
Customizing the harness for different models
All of our harness abstractions are model agnostic and can be heavily customized for every model we support. For instance, OpenAI's models are trained to edit files using a patch-based format, while Anthropic's models are trained on string replacement. Either model could use either tool, but giving it the unfamiliar one costs extra reasoning tokens and produces more mistakes. So in our harness, we provision each model with the tool format it had during training.
This customization goes very deep, and includes custom prompting for different providers and even for different model versions. OpenAI’s models tend to be more literal and precise in their instruction following, whereas Claude is a bit more intuitive and more tolerant to imprecise instructions.
When we get early access to a new model ahead of launch, we start from the closest existing model's harness and begin iterating. We run offline evals to find where the model gets confused, have people on our team use it and surface problems, and tweak the harness in response. We iterate like this until we have a model-harness combination we feel good about shipping.
Much of this tuning process is about customizing the harness to a new model’s strengths, but sometimes we encounter genuine model quirks that we can mitigate with the harness. For example, we observed one model develop what we came to call context anxiety: As its context window filled up, it would start refusing work, hedging that the task seemed too big. We were able to reduce the behavior through prompt adjustments.
Facilitating mid-chat model switching
It’s especially tricky to design the harness to support users switching models mid conversation, because different models have different behaviors, prompts, and tool shapes.
When a user switches models, Cursor automatically switches to the appropriate harness, with that model’s customized set of prompts and tools. However, the model still has to apply those tools to a conversation history that was produced by a different model and is out of distribution from what it was trained on.
To address this, we add custom instructions that tell the model when it's taking over mid-chat from another model. These instructions also steer it away from calling tools that appear in the conversation history but aren't part of its own tool set.

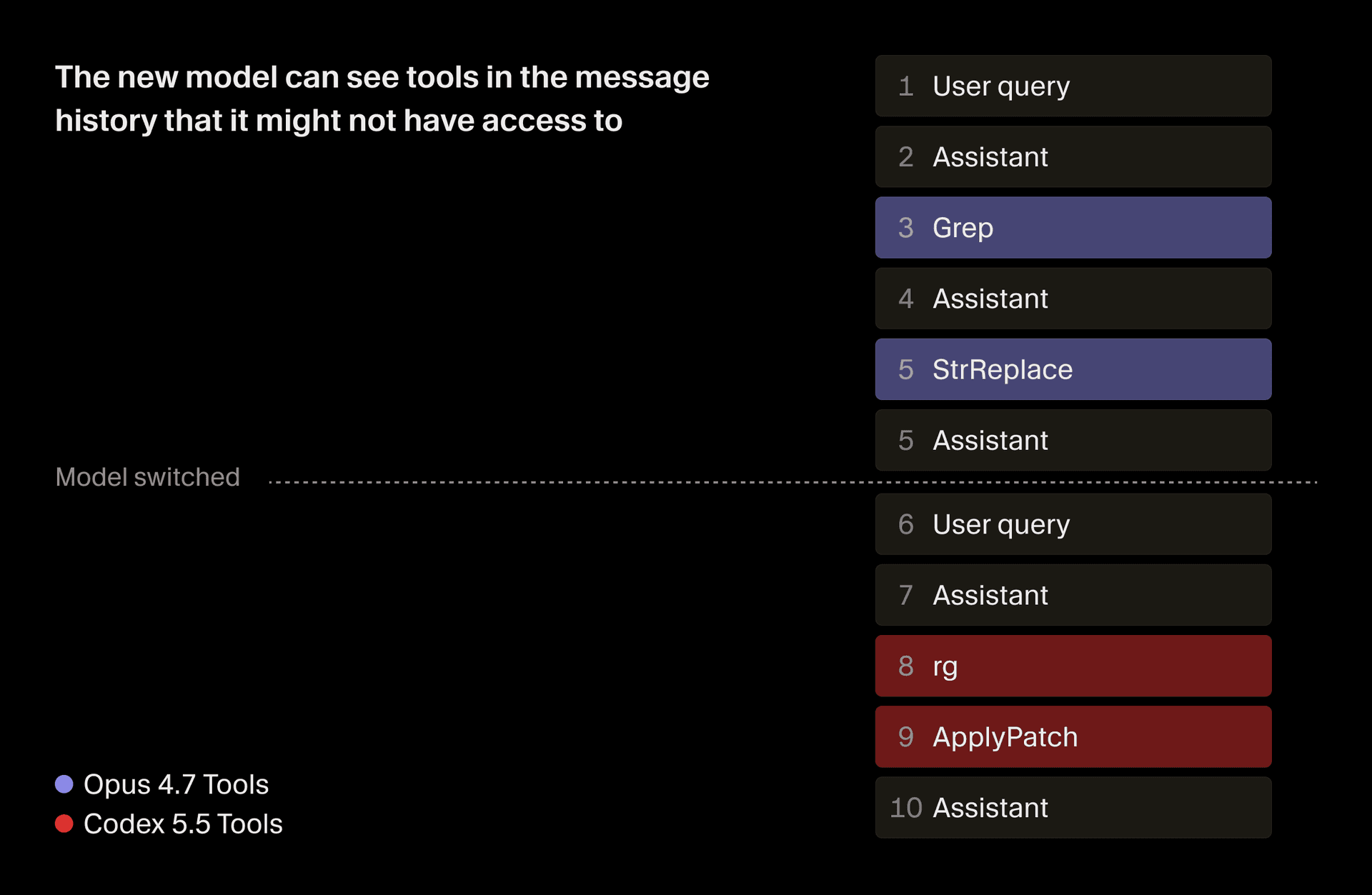
A second challenge is that caches are provider- and model-specific, so switching means a cache miss and a slower, more expensive first turn. We mitigate this by summarizing the conversation at switch time, which provides the model with a clean summary that reduces the cache penalty. But if the user is deep into a complex task, the summary can lose important details, which is why we generally recommend staying with one model for the duration of a conversation, unless you have a reason to switch.
Another way to sidestep the challenges of mid-conversation model switching is to instead use a subagent, which starts from a fresh context window. We recently added to the harness the ability for users to directly ask for a subagent to be run with a particular model.
The harness and the future of software development
The future of AI-assisted software engineering will be multi-agent. Instead of running every subtask through a single agent, the system will learn to delegate across specialized agents and subagents: one for planning, another for fast edits, and a third for debugging, each scoped to what it does best.
Making that work well is fundamentally a harness challenge. The system needs to know which agent to dispatch, how to frame the task for that agent's strengths, and how to stitch the results into a coherent workflow. The ability to orchestrate that kind of coordination will live in the harness rather than any single agent. This means that, while harness engineering has always been important for agent success, it's only going to be more critical going forward.