I've used Claude Code for months, then moved to Codex. I just switched back to Claude and the reason has nothing to do with benchmarks. I also tested both on the same task.
In this article:
I will discuss the different aspects of Claude Code and Codex,
the difference between the two flagship models powering them
Opus 4.6 vs. GPT-5.3-Codex,
what really changes your AI coding experience,
and discuss a small case study where I have used both of them for the same task of building a RAG pipeline.
Just to give you a fair warning, this article takes ~12 minutes to read, and I think that's a time well-invested if you are going to commit to spending $200/month for either of them.
Opus 4.6 vs. GPT-5.3-Codex: Task-Completion Time Horizon
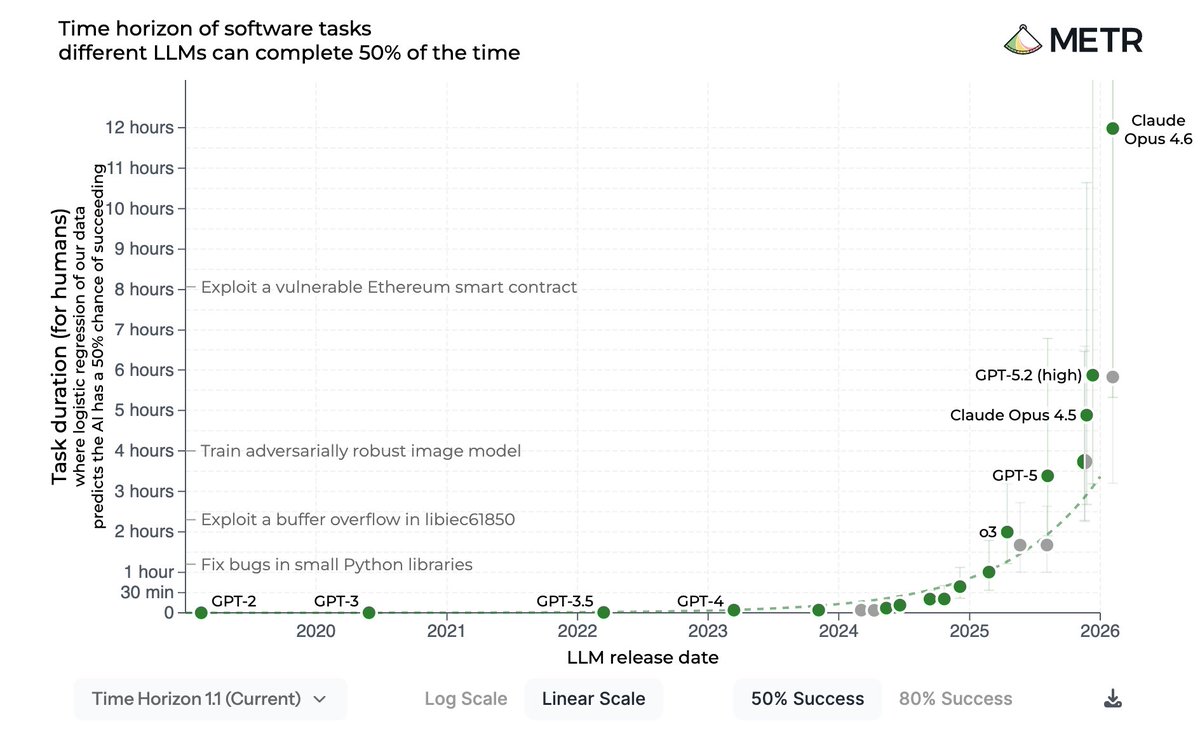
One reliable comparison between Codex vs. Claude Code is about their underlying flagship models and the Completion Time Horizon, which you can check out here.
This comparison asks: how long of a task can this model reliably complete? The task-completion time horizon is the task duration (measured by human expert completion time) at which the model is predicted to succeed with a level of reliability. So a model with a "2-hour time horizon at 50%" means: give it a task that would take a skilled human 2 hours, and the AI succeeds about half the time.
For this study, they use the appropriate scaffold for each model, including Claude Code and Codex. So while the focus is on the model, and not on the scaffold, we can get an idea of how reliable the scaffolds are as well. It tells us which one of these coding agents can handle longer, harder tasks.
As you can see in the chart, there is a BIG gap between Opus 4.6 and GPT-5.3-Codex. Opus 4.6 has a 12 hour task completion length at 50% success while for GPT-5.3-Codex, this number is 5 hours and 50 minutes. This gap closes at 80% success between the two models.
This is a clear indication of a gap between these two models and, consequently, between Claude Code and Codex, between how well they can tackle difficult and challenging tasks. It might not directly translate well to the type of tasks you use them for, so keep that in mind.
Claude Code is Faster, but Speed Doesn't Matter That Much
Claude is famously faster than Codex, but working with coding agents is a long-term process.
If an agent finishes the task in half the time, and then requires you to spend 10 minutes debugging the damn thing, as opposed to spending more time with implementation and not requiring you to babysit it afterwards, that extra time is 100% worth it.
This is NOT to say that Claude Code or Codex makes more mistakes, but a general idea to have in the back of your mind when evaluating the agents yourself or hearing people talk flex their agent's coding speed.
The Task Matters For Agents
Codex and Claude Code perform differently based on the coding task they're used in. In an AI Engineering task, one might outperform the other, while in a web development task, that same model would be obliterated.
Which coding tasks are better for Codex or Claude Code?
This is not studied well.
For example, it's not clear which one to use in low-level programming. Ideally, you'd test both in a simple and verifiable setup before going all-in. But spending $300-$400 for both is not feasible for most people.
It's an interesting area of research to fully review both agents in a variety of coding tasks, but it's also not trivial since these agents and the model powering them change drastically every few months.
How Each Came to Exist
Claude Code initially started as a side project by @bcherny at Anthropic, who built a terminal prototype that could interact with the Claude API, read files, and run some bash commands.
Half the internal team started using it by day five. Then Claude Code was released as a research preview on February 24, 2025, using Claude 3.7 Sonnet. It took some time to be mass-adopted by developers, and over time, Anthropic released a VS Code extension for it as well.
OpenAI on the other hand, announced the original Codex model as a 12B GPT-3 model fine-tuned on GitHub code, which eventually powered the first version of GitHub Copilot. The new Codex is an entirely new product though.
Codex CLI launched first on April 16, 2025, as a terminal agent, and has evolved with better models even since. The latest GPT-5.3-Codex (February 5, 2026) is described by OpenAI as "the first model that helped create itself."
https://newsletter.pragmaticengineer.com/p/how-codex-is-built
@GergelyOrosz has two very interesting interviews with the developers of Claude Code and Codex, about their tech stack, how they develop them, and also how each one started initially. You can learn a lot from these two interviews.
👉 How Codex is Built
Tech stacks and Powering Models
Claude Code is written in TypeScript, using React with Ink for terminal UI rendering. It ships as a single Bun executable (Anthropic acquired Bun in December 2025 for this reason). The Opus and Sonnet models used by it also support a 1M-token context window.
The Codex CLI is written in Rust, for its performance, correctness, and portability. OpenAI even hired the maintainer of Ratatui (a Rust TUI library) for the team.
Both CLI tools are thin wrappers around the model that they use through the API. I've noticed some small "glitches" when working with the Claude Code CLI that I didn't really notice with Codex, and I think that might be expected given their tech stack.
However, these glitches are nothing more than mildly annoying things; they really don't affect your coding experience.
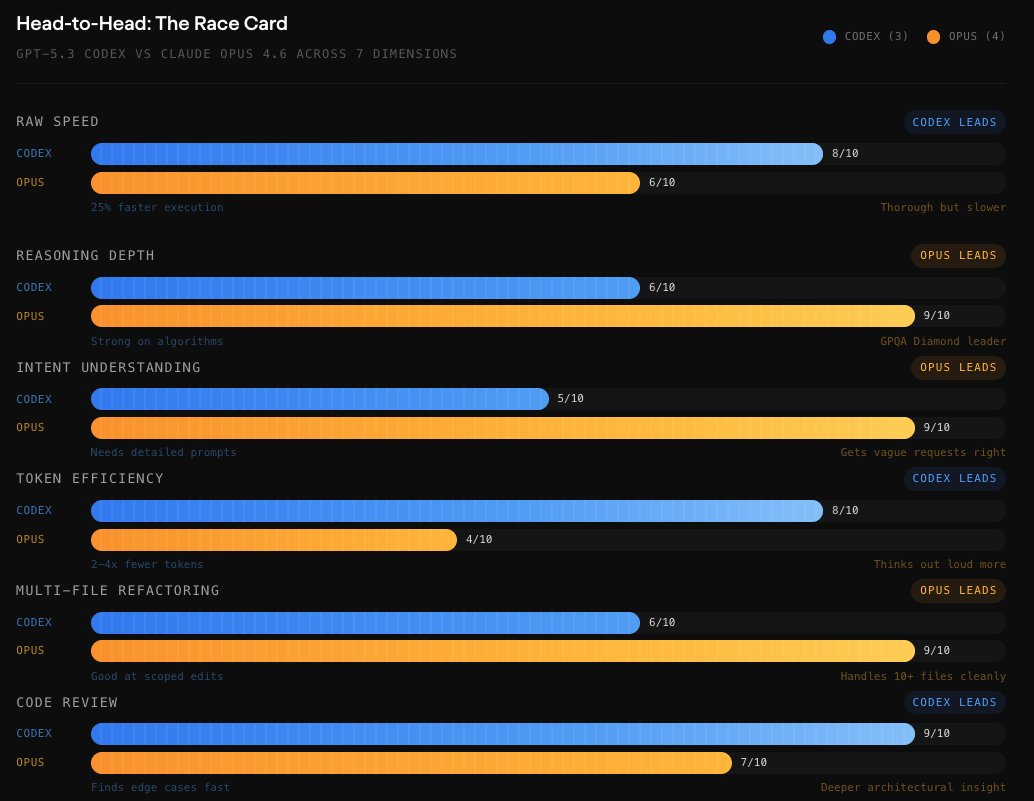
Benchmarks are Close, But with Nuances: Token Economics
The biggest performance difference isn't accuracy, but token efficiency. A comprehensive review on the Opus vs. Codex done by Morph shows an interesting gap.
https://www.morphllm.com/best-ai-model-for-coding
Claude Code uses 3.2–4.2x more tokens than Codex on identical tasks. On a Figma plugin build, Codex consumed 1.5M tokens compared to Claude's 6.2M.
If this is true, it means for paying the same money for a Claude Code subscription, you're more likely to hit token limits.
The Feeling Matters the Most
Claude feels like a senior developer doing work for you, and Codex is a contractor you hand off tasks to and then come back to pick up the results.
This is the common way developers describe the difference.
Claude Code reportedly has a strong interactive feel to it, and also a deep reasoning quality, which is expected of Opus. It asks you questions, shows you the reasoning, and explains its approach. Even though this was not the case in my single comparison experiment, I can confirm this is true, from my many-months experience of using Claude.
Codex is famous for its first-attempt accuracy on straightforward tasks, which comes at the cost of a slight decrease in implementation speed.
With all that being said, the difference in the behavior really diminishes as you lay out specifically what you want in the AGENTS.md. If you specify that you need the model to check the implementation plan with you before going off guns blazing, the model will do that, regardless of which one you use, the "senior developer" agent or the "contractor" agent.
This isn't to say that agents aren't actually different, THEY ARE.
But not as exaggerated as you commonly hear on X.
Quick Numbers
On VS Code Marketplace, Claude Code has 6.1M installs with a 4/5 rating, while Codex has 5.4M installs with a 3.5/5 rating.
On GitHub, Claude Code has approximately 65–72K stars and Codex has ~64K stars.
Why I'm Moving Back to Claude Code for Now
Anthropic's Ecosystem Pulls Hard
Choosing whether to go for Codex or Claude Code isn't just about coding. A subscription to each of them is a subscription to the whole ecosystem of Anthropic/OpenAI and this is something you might want to consider.
https://metr.org/time-horizons/
I personally believe that Claude is becoming a very hot ecosystem similar to Apple, now with Claude Cowork, the Claude Chat, and the Claude Code. It seems Anthropic is also slowly building a safer and tamer version of OpenClaw (your proactive personal agent) with the Claude app, and the small bits and pieces for it are being rolled out gradually.
On OpenAI's front, I'm not seeing anything enticing at the moment. Aside from Codex, everything else seems dull. I don't feel an ecosystem, but fragmented bits and pieces with better alternatives out there.
I've already been using Claude chat rather than ChatGPT, as for me, ChatGPT is borderline unusable at this point compared to Opus. The UI, the tone of the chat, and the model selection, none of them really encourage me to use ChatGPT.
So, at the point of which I'm using Claude Chat frequently, I'm planning to tinker with cowork, and I don't see any deal-breaking improvement from Claude Code → Codex migration at the moment, the decision to go back to Claude Code and cut $200/month subscription price out of my pocket really seemed like an easy choice to make.
This has become a major factor for me, and one that drastically influenced my decision to move back to Claude.
Pricing
The pricing for both Claude Code and Codex is basically the same:
Entry: $20/month for both
Power User: Claude Code has a Max 5x priced at $100/month
Heavy User: $200/month for both
Where Claude Code really shines is that it offers a mid-tier $100/month, rather than a crazy jump from $20 to $200 subscriptions, and I believe the Max 5x plan ($100/month) is really adequate for most developers.
So in a way, you could say Claude Code is cheaper in practice, because it allows you to select a cheaper plan that works for you rather than forcing you to climb the pricing ladder.
Skills and Plugins: The Developer Ecosystem
As skills are compatible between Claude Code and Codex, you won't notice a difference regardless of which one you use. However, most skill hubs and repos are named after Claude Code, which might be a little confusing.
This is the case with most other things as well. Many of the posts you see on Reddit, X, or blog posts about coding agents are about Claude Code rather than Codex, even though the same principles apply to both of them, which really tells you something about the popularity and community size.
Codex has launched support for both skills and plugins much later than Claude Code. But plugins aren't as compatible as skills. And as plugin support for Codex started just recently, there's not so many available.
All this to say that many developers, including me, don't use plugins at all. So unless you specifically need the support for various plugins, this is not something to worry about or base your decision on.
RAG Pipeline: A Case Study
For the comparison, I chose to go with a task that can be quantitatively assessed. The problem with creating a landing page, for example, is that it's a qualitative task: one might think a landing page is cool looking while the other calls it purple-gradient slop.
So I chose the task of building a simple RAG pipeline, since the accuracy of the generated answers can be determined in numbers.
Other good ideas if you want to do a similar comparison yourself, could be training a vision model or fine-tuning an LLM, or measuring the performance of a low-level program.
Building a retrieval pipeline is a common task of an AI engineer, potentially something you'd use Claude Code or Codex in your job. I tasked both of these coding agents to build me a RAG Q&A pipeline for research papers. The workflow is simple:
-
Take a number of papers and extract their text.
-
Chunk the contents into smaller bits.
-
Embed each chunk into a vector space.
-
When a user asks a question, find the closest chunk embeddings to the embedding of the question.
-
Retrieve the close chunks in their original form (not their embeddings).
-
Use that context to answer the user's question.
This is a task simple enough to be implemented in one session, but it has intricate details that massively influence the output: - what chunking strategy to use - how to embed the chunks - what vector storage to go for - how to handle the confidence of which chunk is closer to the query - whether to rephrase the user's query to help find more similar chunks, etc.
The Experiment Setup
I took 5 research papers from the @huggingface daily papers of the past week, and created a test dataset (size = 100) of questions and ground truth answers, which I would later use for testing how good the implementation of Claude or Codex is.
For both coding agents, I specified the following:
-
Build a Python RAG pipeline
-
Process all PDFs using PyMuPDF
-
Choose a good chunking strategy for this use case
-
Create embeddings and a persistent local vector index (your choice)
-
generate final answers with **llama-3.1-8b-instant**.
-
If no sufficient evidence is found, do not hallucinate. return a fallback response
For both Codex and Claude Code, I used the best most popular and default available models: gpt-5.3-codex and Opus 4.6, both with High effort (the degree of reasoning). None had an AGENTS.md.
How They Implemented The Pipeline
I didn't notice any noticeable difference in how each agent thinks about the task, other than the fact that Codex is more verbose in explaining its plan and what it's going to do. Claude simply writes the files and executes the commands without talking so much about it.
Codex also took longer to finish the task compared to Claude.
More importantly, Claude tested the script end-to-end and made sure the pipeline is ready to use.
Codex, on the other hand, finished the implementation but didn't test or run the program, and instructed me to pip install the requirements and run the script. Naturally, I hit an error in running the script, which Codex fixed. Claude's script worked with no problems whatsoever.
I've noticed this pattern with Codex, that it leaves many of the labor or setups for you to do rather than simply doing it itself.
While Codex would let you know and take action for an env problem or implementation difficulty, Claude takes the liberty of fixing it, which depending on your preference, can be a good/bad thing.
I've also noticed that the initial time-to-response for the first token in a new session for Codex can go as high as a minute, while this is much shorter for Claude Code.
Claude Code vs. Codex Implementation
Both coding agents went for surprisingly similar approaches:
-
they both went for the same all-MiniLM-L6-v2 as the embedding model
-
they selected k=5 for the Top-K retrieval
-
both restricted the LLM in the system prompt to only use the provided context
This is where they went with separate approaches:
-
Vector Storage: Claude Code chose ChromaDB for the vector DB, and Codex went for FAISS, which is a lower-level similarity search library, more memory-efficient and faster.
-
Chunking: Claude Code went for a recursive character splitting. It tried \n\n first, then \n, then "." , then " ". The target is 1000 chars with 200 char overlap. Codex went for a sentence-level word splitting and fills chunks up to 220 words, with 40-word overlap. Claude Code splits by structure (paragraphs → lines → sentences → words) and measures in characters. Codex splits by sentences first, then packs them into word-budget bins. Codex's approach respects the sentence boundaries and avoids mid-sentence cuts, but the 220 words may be too small for this context (academic text).
-
Retrieval: Both chose Top-5 chunks. Claude Code returns raw L2 distances and Codex returns inner-product (cosine) scores.
-
Confidence: Claude Code used a single threshold on the best L2 distance (>1.2 = irrelevant) and then checks the average distance for low vs. well-grounded chunks. Codex uses multi-criteria with three tiers: strong, moderate, and insufficient.
-
Code Architecture:
Claude Code: Flat functions, constants in each module, no input validation on model consistency.
Codex: OOP pipeline class, centralized config, dataclasses, argparse CLI, model consistency validation.
Codex is clearly better engineered and more configurable. In large and more serious codebases, this is critical.
Results
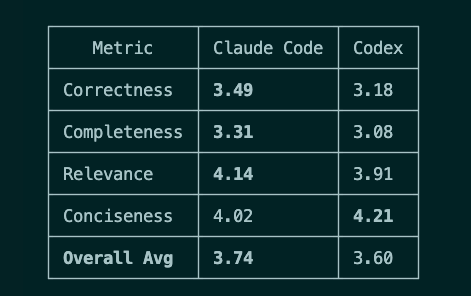
Using gpt-5.4 as the LLM-as-a-judge, the answer of both pipelines is compared in four criteria: Correctness, Completeness, Relevance, Conciseness.
Among the 100 questions, Claude Code won 42, Codex won 33, and 25 were ties. Claude won mostly due to its looser confidence gating, and maybe a slightly higher generation temperature (0.2 vs 0.1 in Codex's pipeline).
A Pinch of Salt
Now this was a very simple setup, and I was mostly curious to see the different approach the two coding agents take in implementing the same close-ended task. In a professional setup, it's the developer who makes the calls for the overall architecture: the chunking method, the Vector DB, the retrieval strategy, etc. Also, in a professional setup, developing such systems requires much more testing and iterative improvements, with more reliable test sets and verifications.
However, it's really expected that a junior developer who's not very experienced in building a RAG pipeline leaves these decisions to the AI to make.
Just Pick One
I don't think there is any terminally wrong decision whether you choose Claude Code or Codex. Both offer strong models compared to the existing landscape and get the job done to a similar degree.
Two major factors for me have been: the Anthropic ecosystem, and the $100/month pricing tier. Even if I have to bump up that tier to the $200/month pricing, I would still stick to Anthropic's Claude Code for the former reason.
The most important thing is what you use these scaffolds for and how you use them.
This determines which one is better for you better than any benchmarks, and there's no clear answer to that other than your gut telling you which one feels better after you test both.
There are developers like @steipete who swear by Codex, and there is a community that believes Opus is just unrivaled by OpenAI models.
I think both of them are correct at the same time, simply because their workflow of using these coding agents, and their "taste" is different.
If you're doubtful about which one to go with, I suggest trying out the $20/month version of both of them on the type of programming field that's relevant to you, and test preferably on several verifiable tasks.
Finally, keep in mind that similar to anything else related to AI, the landscape changes drastically every few months. While you might like one of them now, three months later, the agent's behavior might drift, or a new model might hit the market.
There are very few things in AI with definitive global answers, and this subject is not one of them ;)





Link: http://x.com/i/article/2030946053629915136