Developers spend weeks perfecting prompt engineering, tool calling, and response latency. None of it matters when your agent needs to stay alive for five days.
The workflows that actually matter in production (processing thousands of insurance claims, running week-long sales sequences, reconciling financial data across systems) don't fit inside a single conversation turn. They take days, not seconds.
The moment you try to build these long-running agents, you realize most agent architectures are stateless. They reconstruct context from databases on every interaction. They lose the reasoning chain, the soft signals, and the confidence gradients that made the agent's previous decisions make sense.
At Cloud Next 26, we announced that Agent Runtime now supports long-running agents that maintain state for up to seven days. In this article, we’ll share five essential agent design patterns for building long-running agents with Agent Runtime.
By @addyosmani and @Saboo_Shubham_
Here are five design patterns that separate production systems from demos.
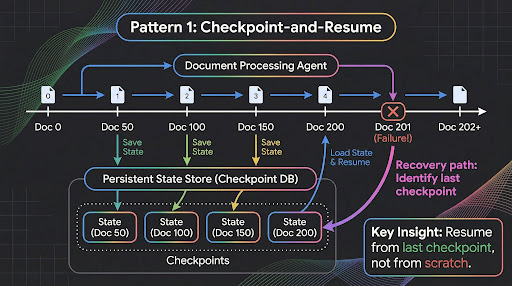
Pattern 1: Checkpoint-and-Resume
The most common failure mode in multi-day workflows is context loss. An agent processes 200 documents over four hours, then hits an error on document 201. Without checkpointing, you restart from scratch.
Long-running agents on Agent Runtime maintain persistent execution state in a secure cloud sandbox. The agent has full access to bash commands and a sandboxed file system, so you can write intermediate results to disk, maintain processing logs, and recover from failures.
Treat your agent like a long-running server process, not a request handler. The same way you build a data pipeline that processes millions of records: checkpoint progress, handle partial failures, ensure idempotency.
Here is how you structure a document processing agent that checkpoints after every batch using Google Agent Development Kit:
Notice the checkpoint granularity. Not after every document (wasteful). Not only at the end (risky). Fifty documents per batch balances durability against overhead. Your specific number depends on how expensive each unit of work is.
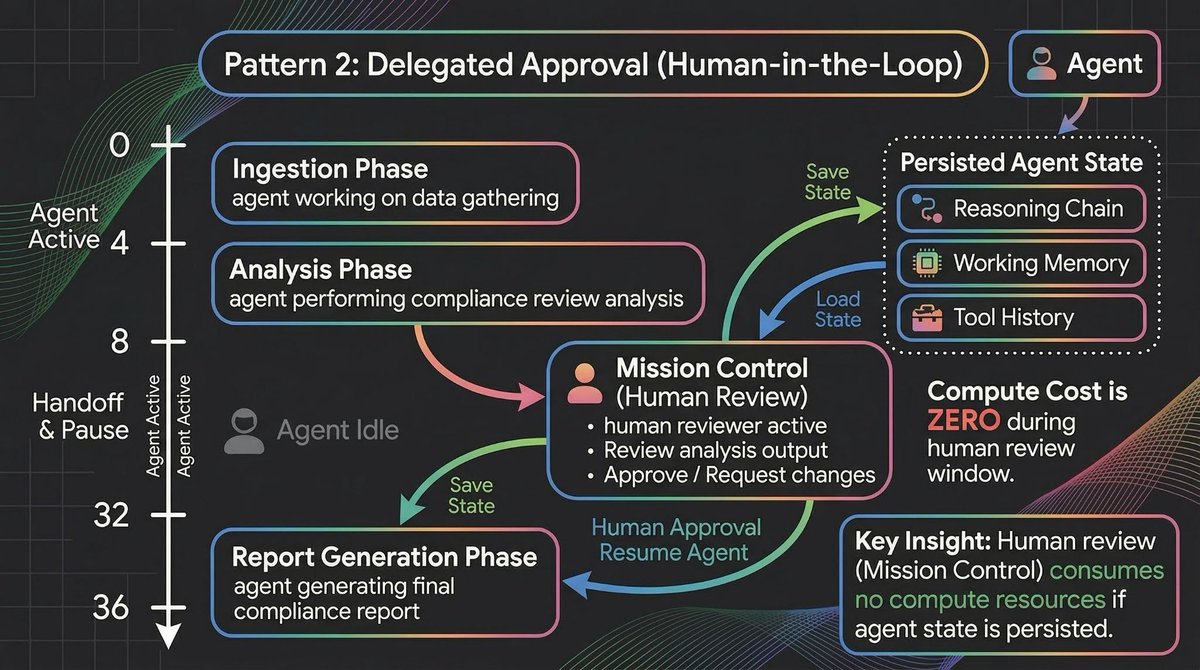
Pattern 2: Delegated Approval (Human-in-the-Loop)
Every framework advertises human-in-the-loop.
But in practice, most implementations are: serialize state to JSON, send a webhook, hope someone checks it. The problems compound fast. JSON serialization loses implicit reasoning context. Notifications compete with dozens of alerts.
When the human responds hours later, the agent has to deserialize, re-establish context, and hope nothing changed.
Long-running agents handle this differently. When the agent hits an approval gate, it pauses in place. Full execution state stays intact: reasoning chain, working memory, tool call history, pending action.
Here's what that looks like in practice:
The critical detail: hours 8 through 32 are dead time for the agent but active time for the human. The agent consumes zero compute while paused. Sub-second cold starts mean zero latency penalty when it resumes.
Mission Control provides the inbox that makes this manageable at scale. Notifications categorized into "Needs your input," "Errors," and "Completed." If you're managing twenty long-running agents, you're not hunting through Slack channels to figure out which ones need attention.
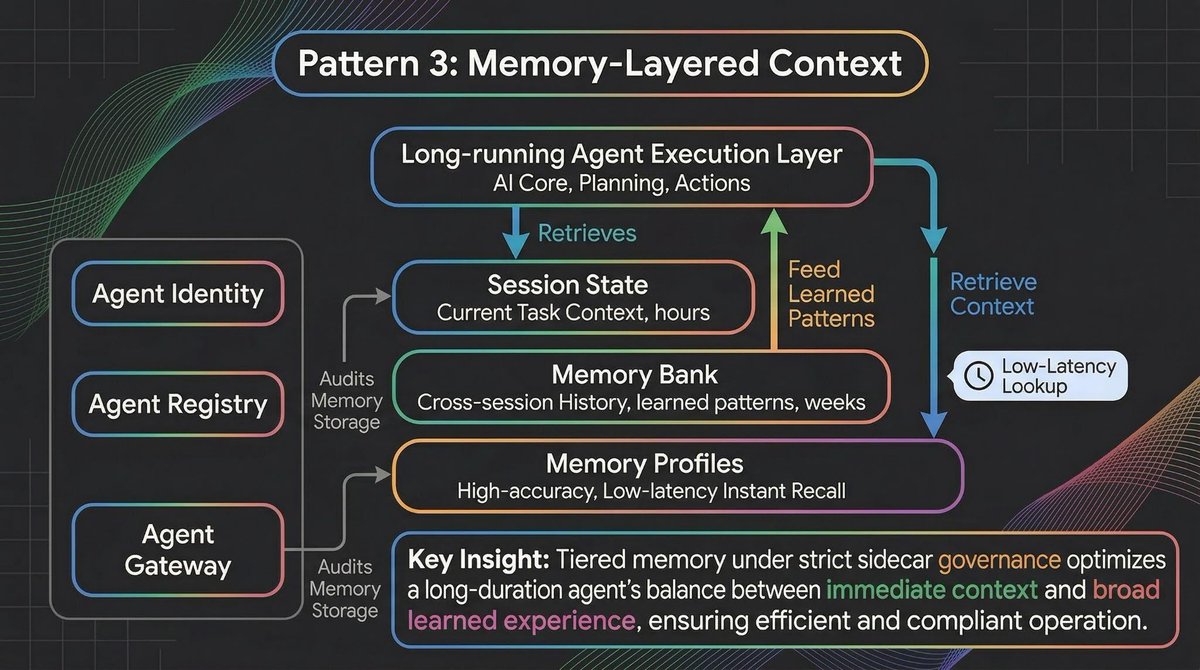
Pattern 3: Memory-Layered Context
A seven-day agent needs more than session state. It needs to remember things from previous sessions, user preferences from weeks ago, and organizational context that no single conversation could contain.
This is where Memory Bank and the new Memory Profiles work together.
from google.adk import Agent, ToolContext
class DocumentProcessor(Agent):
"""Processes large document sets with checkpoint-and-resume."""
async def process_batch(self, docs: list, ctx: ToolContext):
checkpoint = self.load_checkpoint() # Resume from last position
start_idx = checkpoint.get("last_processed", 0)
for i, doc in enumerate(docs[start_idx:], start=start_idx):
result = await self.classify_and_extract(doc)
self.results.append(result)
# Checkpoint every 50 documents
if (i + 1) % 50 == 0:
self.save_checkpoint({
"last_processed": i + 1,
"partial_results": self.results,
"timestamp": datetime.now().isoformat()
})
return self.compile_final_report()
Memory Bank (now available for everyone) dynamically generates and curates memories from conversations, organized by topic. Memory Profiles add low-latency access to specific, high-accuracy details. Think of Memory Bank as long-term memory and Memory Profiles as working memory.
But here's the problem most developers don't anticipate until production: memory drift. Your agent's behavior isn't shaped only by its code and prompts. It's shaped by accumulated experience. If an agent "learns" from a few atypical interactions that a procedural shortcut is acceptable, it might start applying that shortcut broadly. And if multiple agents read and write to shared memory pools, data leakage between distinct workflows becomes a real risk.
You can't let agents write to a vector database unchecked. You need to govern them the same way you govern microservices. This is where Agent Identity, Agent Registry, and Agent Gateway come in. They bring standard infrastructure concepts into the agent lifecycle:
Agent Identity works like IAM for agents. Just as a microservice needs a service account, an agent needs a cryptographic identity that determines exactly which memory banks and tools it's authorized to access.
Agent Registry works like service discovery. When you have dozens of long-running agents, you need a centralized way to track which agents are active, what version of the prompt and code they're running, and what their current execution state is.
Agent Gateway works like an API gateway tailored for LLMs. It sits between the agent and its memory and tools, evaluating requests against organizational policies. If an agent tries to commit PII to its long-term Memory Bank, the Gateway blocks the transaction.
Build auditing into your memory layer from day one. The question isn't just "what are my agents doing?" It's "what are my agents remembering, and how is that changing their behavior?"
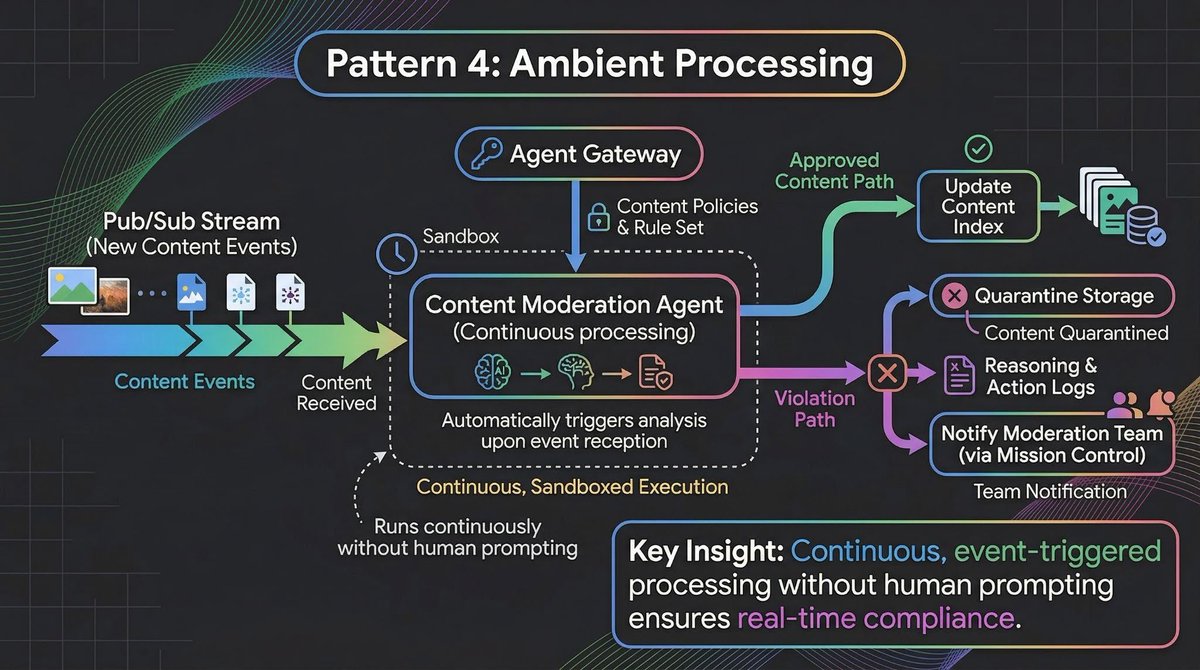
Pattern 4: Ambient Processing
Not every long-running agent interacts with humans. Some are ambient. They watch for events, process data streams, and take action in the background without any user prompting.
Batch and Event-Driven Agents connect directly to BigQuery tables and Pub/Sub streams.
Here's a concrete example: a content moderation agent that processes user-generated content as it arrives.
This agent runs for days. It doesn't wait for someone to ask it to moderate content. It processes events as they arrive, maintains its own state about trends and patterns, and escalates only when necessary.
The important architectural decision here ties back to the governance layer from Pattern 3.
Don't hardcode content policies into the agent. Define them in Agent Gateway and the agent enforces them at runtime. When policies change, you update Gateway once and every ambient agent picks up the new rules. The agent's identity (from Agent Identity) determines which policies apply to it, and the Registry tracks which version of the agent is running against which policy set.
This separation matters because ambient agents run unsupervised for long stretches. If you hardcode policies, every policy change requires redeploying every agent. If you externalize policies through the Gateway, you update once and the fleet adapts.
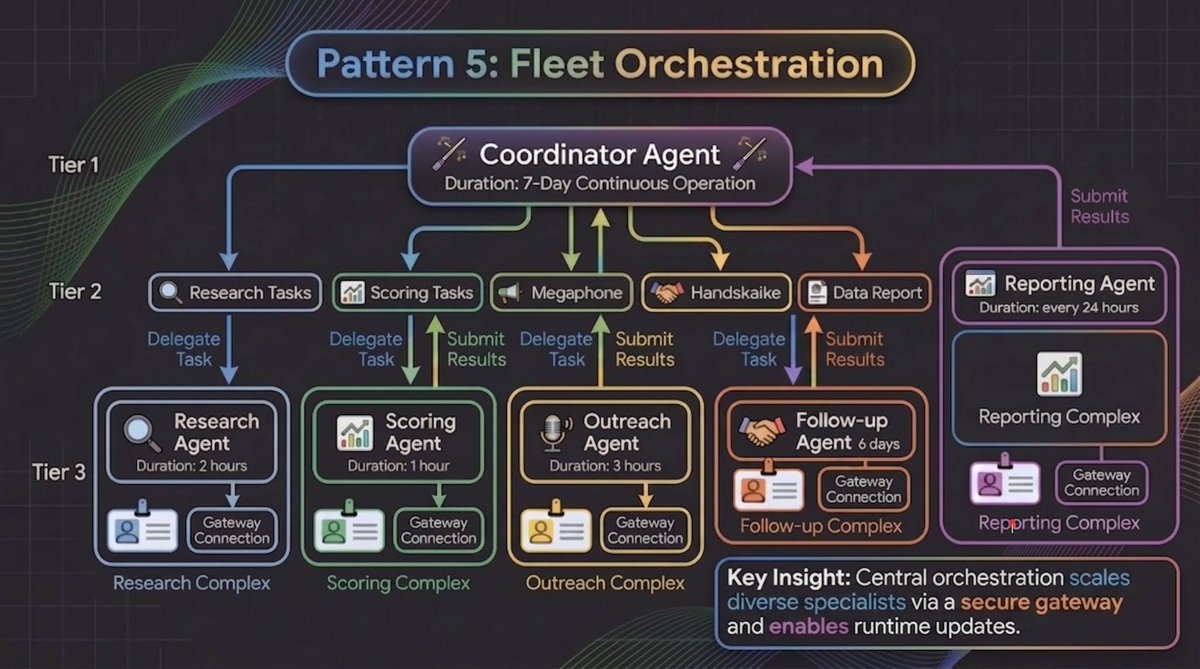
Pattern 5: Fleet Orchestration
The final pattern is about managing multiple long-running agents as a coordinated fleet. In production, you rarely have a single agent working alone. You have a coordinator agent that delegates sub-tasks to specialist agents, each running independently for different durations.
Consider a sales prospecting sequence:
Each specialist has its own Agent Identity (so it can only access the tools and memory it needs), its own policy enforcement through Agent Gateway (so the Outreach Agent can't access financial data meant for the Scoring Agent), and its own entry in the Agent Registry (so you can track versions and execution state across the fleet).
The coordinator maintains global state and handles handoffs between specialists. This is the same coordinator/worker pattern used in distributed systems for decades. What's new is that ADK handles this natively with graph-based workflows that define coordination logic declaratively.
The operational advantage of treating each specialist as an independent unit is that you can update them independently too.
If your Scoring Agent's ranking logic needs improvement, you can deploy the new version, monitor its performance through Agent Observability, and promote it only when the results hold up. And because each agent runs in its own container (with Bring Your Own Container support for your existing CI/CD and security requirements), a bad deployment in one specialist never cascades to the others.
Choosing the Right Pattern
These patterns compose. A compliance system might use Checkpoint-and-Resume for document processing, Delegated Approval for review gates, Memory-Layered Context for cross-session knowledge, and Fleet Orchestration to coordinate specialists.
The key question: what is the longest uninterrupted unit of work your agent needs to perform? If it's minutes, you probably don't need long-running agents. If it's hours or days, these patterns are where you start.
Get started
Long-running agents are available today on Gemini Enterprise Agent Platform. Build with ADK, deploy on Agent Runtime, monitor via Mission Control. The combination of 7-day persistence, human-in-the-loop approvals, and long-term memory is what turns an agent from a chatbot into an autonomous worker.
Start here: https://cloud.google.com/gemini-enterprise/agents
🚢 Put These Patterns into Practice: Google for Startups AI Agents Challenge
Don't just read about agent architecture - build it. We’re inviting startups to a 6-week global challenge to build, optimize, or refactor AI agents on the Gemini Enterprise Agent Platform. You'll get $500 in cloud credits, full platform access and a shot at the $90,000 prize pool.
Sign up today to start building!