如果你用 25 年的市场数据训练一个 AI 智能体,你真的能靠它稳定做到每月 $20k 吗?
剧透:读到最后你会明白——只要抓住正确的时机,在预测市场做到 10 倍收益是可能的
在开始之前,先把这篇文章收藏一下并点个关注 每天在 Polymarket 等平台发布日更 alpha
人类大脑一次最多只能同时跟踪 19 件事。预测市场却由数百个变量共同驱动:新闻、成交量、动量、鲸鱼资金、情绪——全都在同一时间发生。
手动分析不可能。但代码可以。
这个机器人会一次性开出 100+ 笔交易,而且在进场前就已经知道每一笔的情景假设。就算胜率只有 64%——也已经是利润。
阶段 1 —— 时间周期
在预测市场里,有很多时间周期: - 1 天 - 7 天 - 30 天
模型可以跨不同周期做预测,但本文聚焦 1 天。这份预测市场合约明天会以 YES 结算吗?
先从最简单的开始——只看一天。如果你能稳定地提前 1 天判断方向,这就已经是一套可用于日常交易的工具。
阶段 2 —— 模型预测什么(分类预测)
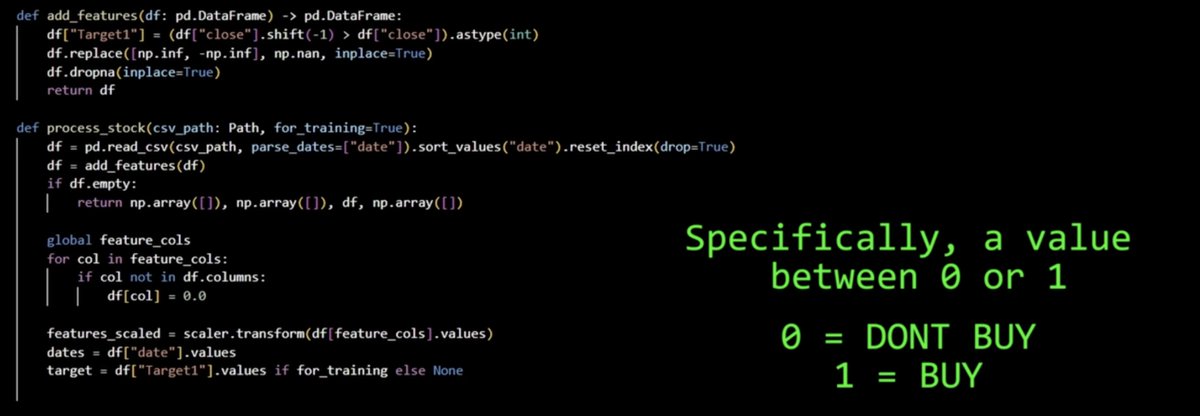
Target1 = 1 -> 明天更高 -> BUY
Target1 = 0 -> 明天更低 -> DONT BUY
很简单——模型不试图预测精确价格。它只回答一个问题:涨还是跌?
这和 Polymarket 合约的逻辑一致——你押的是事件结果,而不是一个精确数字
阶段 3 —— 通往结果的 38 个指标
train_val_cutoff = global_min_date + (global_max_date - global_min_date) * 0.8
train_cutoff = global_min_date + (train_val_cutoff - global_min_date) * (1 - 0.2)
Training (2000–2020): BTC, S&P500, ETH, major prediction markets
Testing (2021–2025): same markets, but future the model never saw
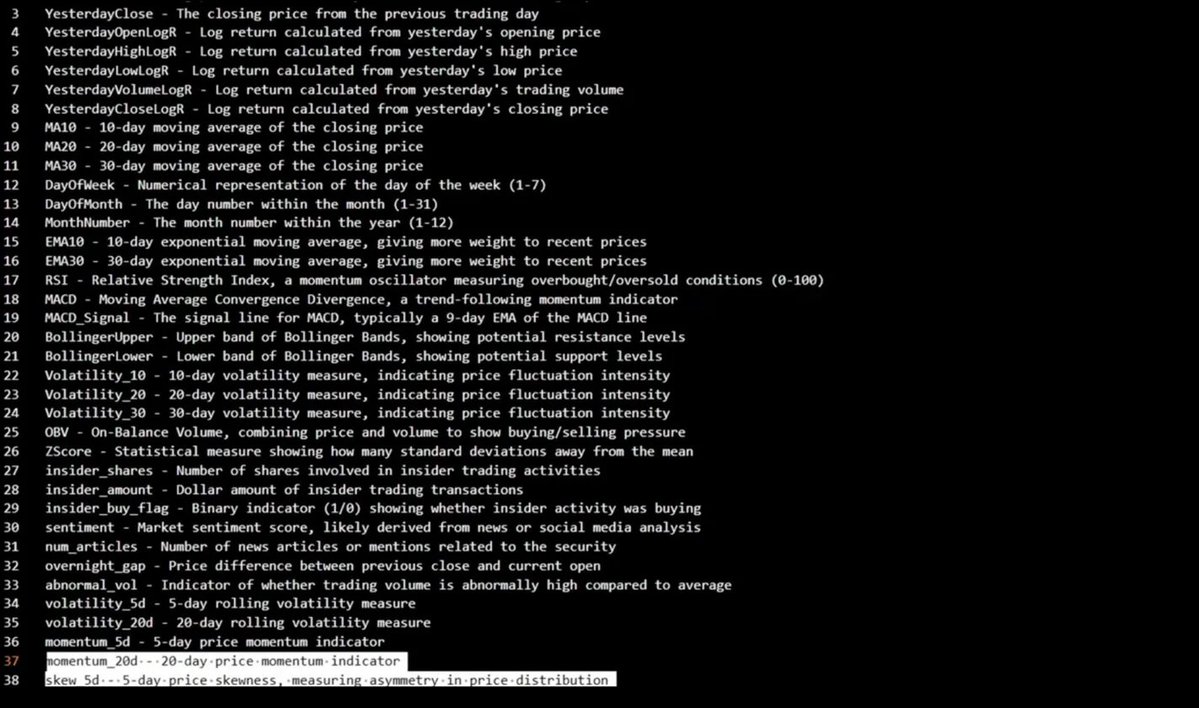
模型看的不只是价格——它会分析过去 60 天里、覆盖 30 份预测市场合约的 38 种不同信号
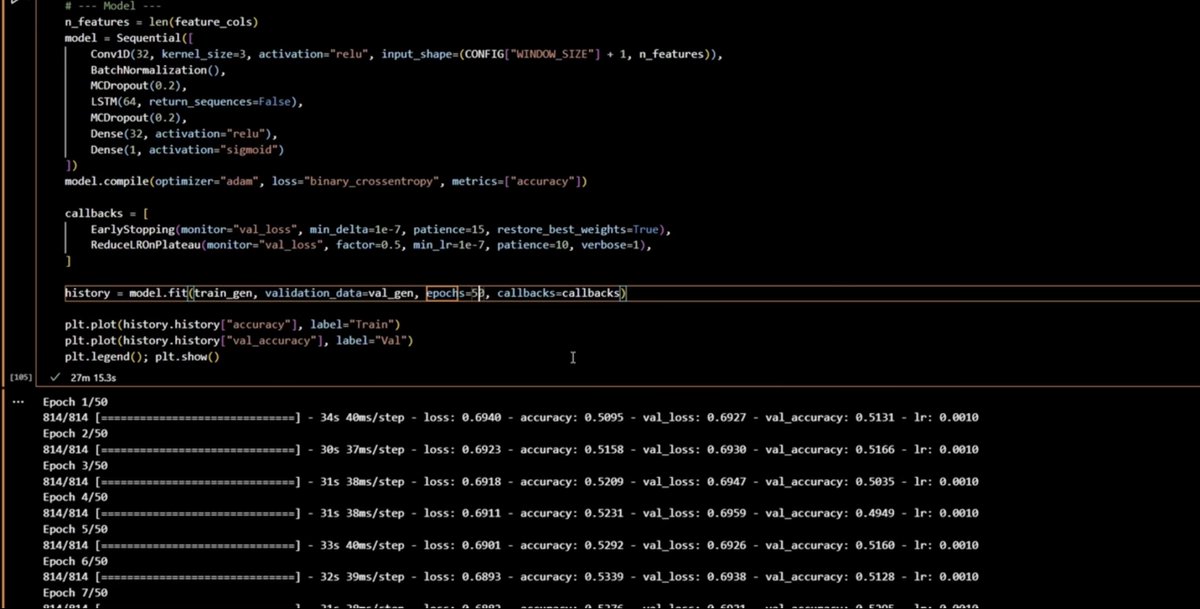
callbacks = [
EarlyStopping(monitor="val_loss", min_delta=1e-7, patience=15),
ReduceLROnPlateau(monitor="val_loss", factor=0.5, min_lr=1e-7, patience=10),
]
history = model.fit(train_gen, validation_data=val_gen, epochs=50)
想象一下:每天手动对 30 份合约逐一分析 38 个指标
阶段 4 —— 我们如何按时间切分数据
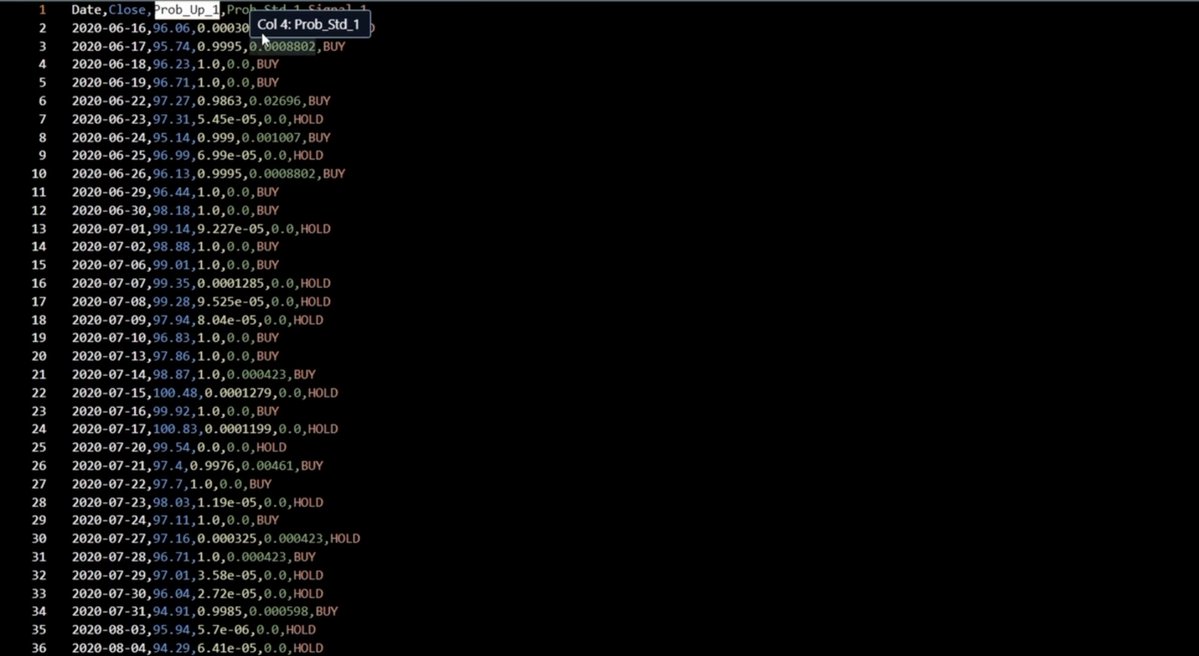
Date Close Prob_Up_1 Prob_Std_1 Signal_1
2020-06-17 95.74 0.9995 0.0008 BUY
2020-06-23 97.31 5.45e-05 0.0 HOLD
2020-06-26 96.13 0.9995 0.0008 BUY
result[f"Signal_{h}"] = [
"BUY" if p > 0.7 else "HOLD"
for p in y_pred_mean[:, i]
]
重点:模型在过去数据上学习,在未来数据上测试。没有数据泄漏
这是人们搭建这类系统时最常犯的错误——用训练过的数据去测试。我们不这么做。模型在训练时从未见过 2021–2025——这是一场干净、诚实的测试
阶段 5 —— 神经网络架构
-
Conv1D - 在时间序列中寻找局部模式
-
LSTM - 记住长期依赖关系
-
MCDropout - 衡量预测不确定性
-
Sigmoid - 输出 0 到 1 的数(概率)
model = Sequential([
Conv1D(32, kernel_size=3, activation="relu",
input_shape=(WINDOW_SIZE + 1, n_features)),
BatchNormalization(),
MCDropout(0.2),
LSTM(64, return_sequences=False),
MCDropout(0.2),
Dense(32, activation="relu"),
Dense(1, activation="sigmoid"),
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
模型只输出一个数字。比如 0.85——意味着模型有 85% 的把握认为明天价格会上涨。至于信不信,由你决定
阶段 6 —— 蒙特卡洛 Dropout(关键部分)
我们不只做一次预测,而是用不同的 dropout 率让模型跑 50 次。这样能得到 mean(置信度)和 std(不确定性)。 如果模型自己都无法达成一致,我们就不买
你可以把它理解为:同时问 50 位分析师。如果 50 个都说 BUY,我们就进场;如果一半说 BUY、一半说 HOLD——我们就跳过。
> 只有当出现一致共识时,我们才交易
阶段 7 —— BUY/HOLD 信号
置信度阈值是 70%。如果模型给出 BUY 但置信度低于 70%——我们就忽略这条信号,继续寻找机会
我们不会每天在每个市场都交易。我们只等强信号。每周 3 笔高置信交易,胜过 20 笔不确定的交易
区块 8 —— 训练
def add_features(df: pd.DataFrame) -> pd.DataFrame:
df["Target1"] = (df["close"].shift(-1) > df["close"]).astype(int)
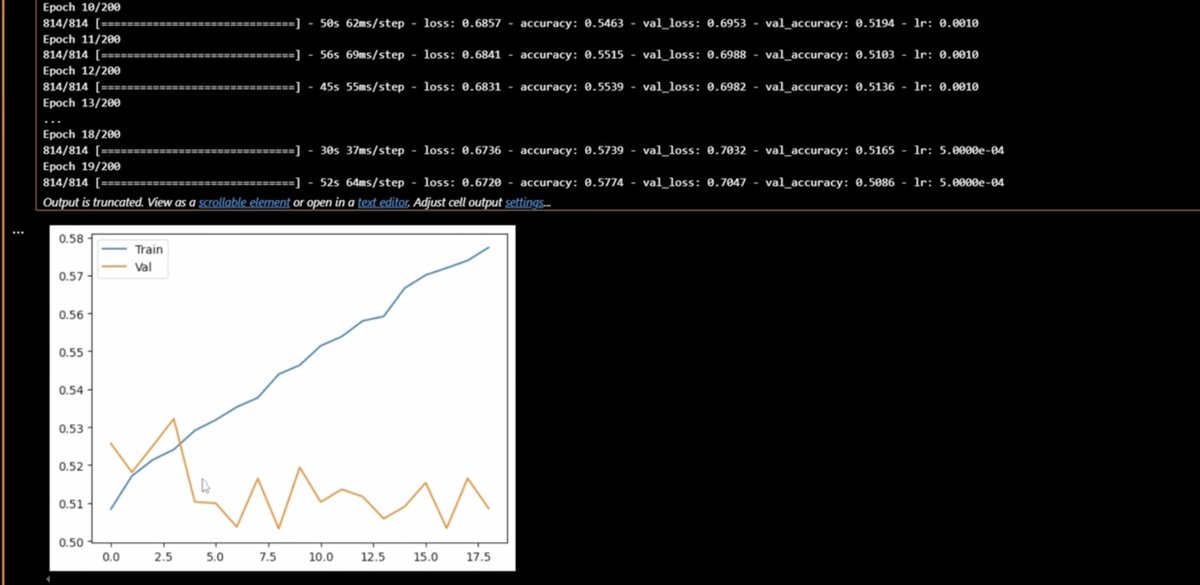
~59% 的准确率听起来不算高——但在预测市场,即便 59% 的胜率也能带来稳定盈利
MA10, MA20, MA30 — moving averages
RSI — overbought/oversold
MACD, MACD_Signal — trend
BollingerUpper/Lower — volatility bands
Volatility_10/20/30 — price fluctuation intensity
OBV — buyer/seller pressure
sentiment, num_articles — news flow
insider_shares/amount — insider activity
momentum_5d / momentum_20d
赌场只靠 2–3% 的优势就能赚钱。我们有 59%。每月 100+ 笔交易,数学站在我们这边
阶段 9 —— 最终结果
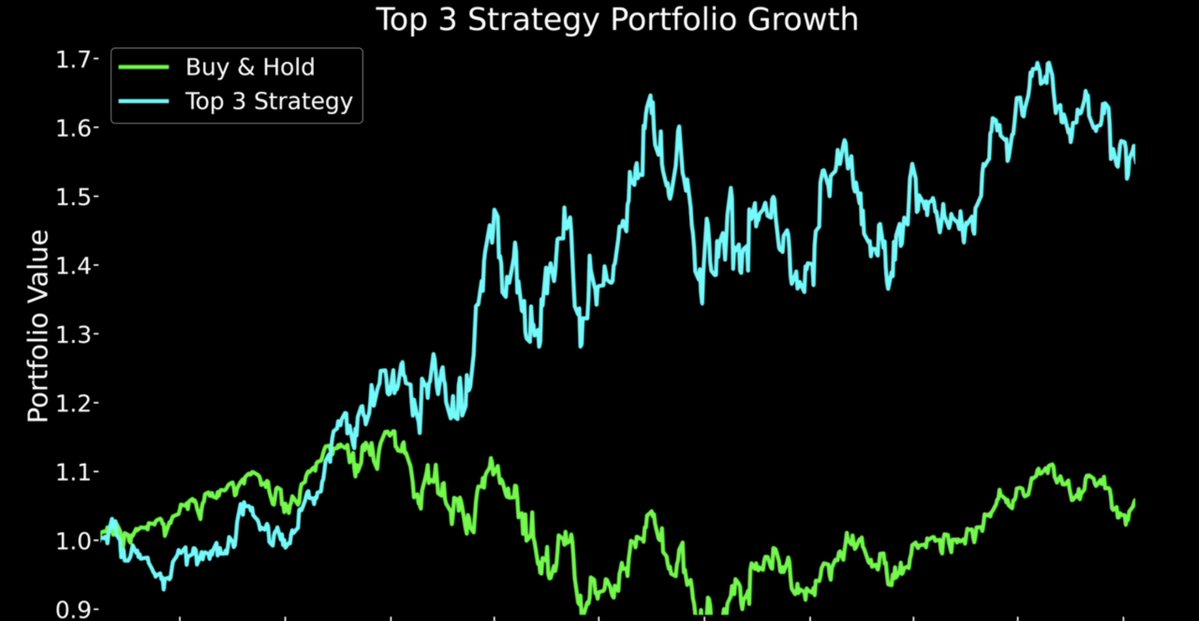
策略很简单——每天买入上涨概率最高的 前 3 个仓位。
class MCDropout(Dropout):
def call(self, inputs, training=None):
return super().call(inputs, training=True)
def mc_dropout_predict(model, X, n_samples=50):
preds = np.array([model(X, training=True).numpy() for _ in range(n_samples)])
return preds.mean(axis=0), preds.std(axis=0), preds
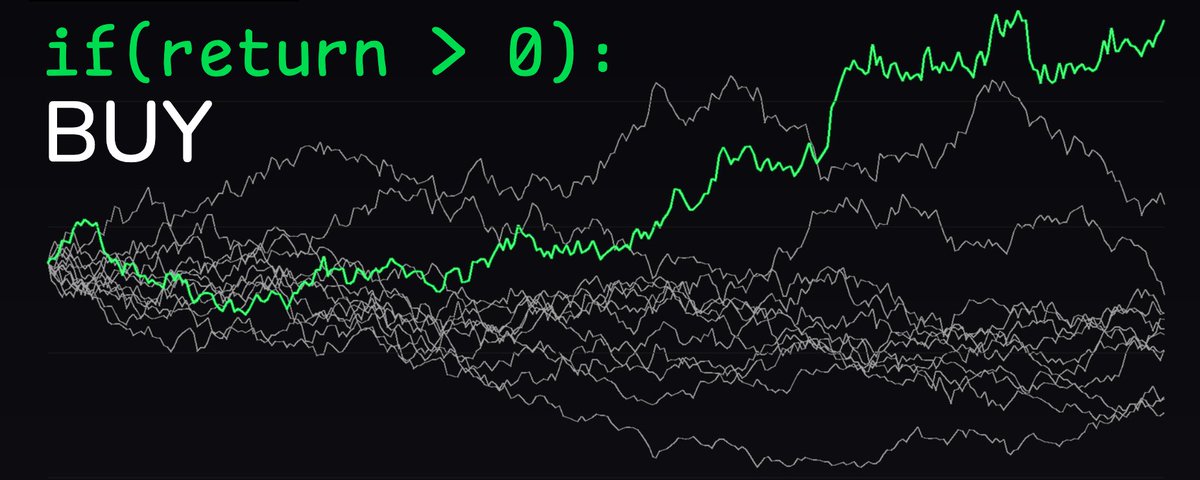
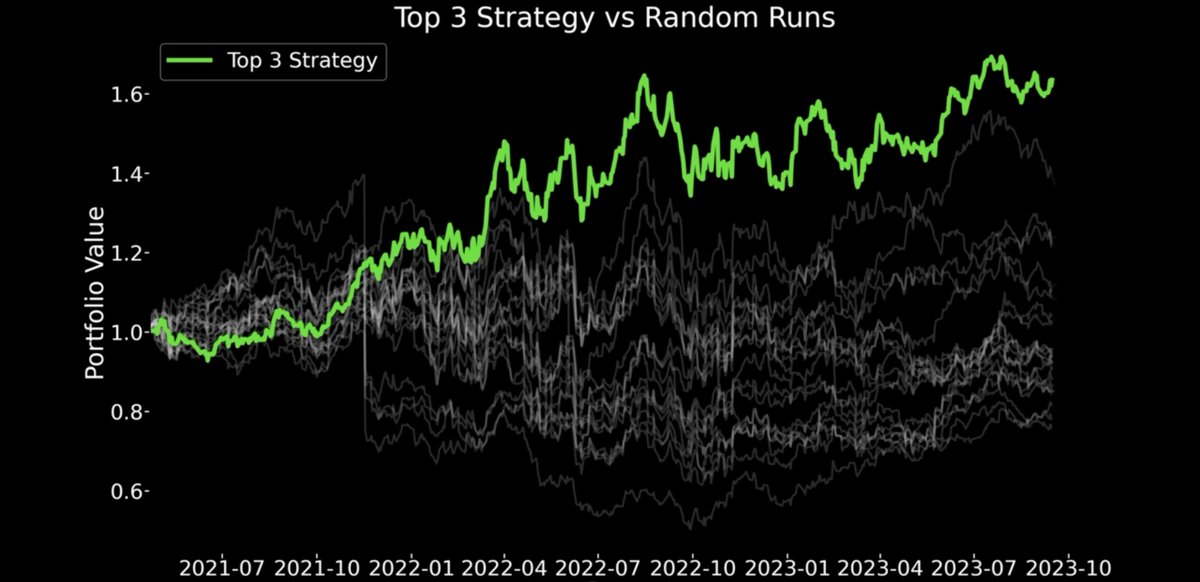
灰线代表 10 个人每天随机开预测市场仓位。绿线是我们的机器人。差异一目了然!
结果持续跑赢随机策略,而且胜率稳定高于 59%——有时甚至能到 78%
跨 30 个市场的每一条信号、每一个指标、每一种模式——几秒内处理完。不是你做的,而是一个 24/7 运行的模型在做
我们把 25 年的市场数据压缩为 38 个指标,用 LSTM 神经网络对每次预测跑 50 次——而且 结果持续跑赢随机策略。